 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEGDM: Learning EEG Representation with Latent Diffusion Model
Aug 28, 2025While electroencephalography (EEG) signal analysis using deep learning has shown great promise, existing approaches still face significant challenges in learning generalizable representations that perform well across diverse tasks, particularly when training data is limited. Current EEG representation learning methods including EEGPT and LaBraM typically rely on simple masked reconstruction objective, which may not fully capture the rich semantic information and complex patterns inherent in EEG signals. In this paper, we propose EEGDM, a novel self-supervised EEG representation learning method based on the latent diffusion model, which leverages EEG signal generation as a self-supervised objective, turning the diffusion model into a strong representation learner capable of capturing EEG semantics. EEGDM incorporates an EEG encoder that distills EEG signals and their channel augmentations into a compact representation, acting as conditional information to guide the diffusion model for generating EEG signals. This design endows EEGDM with a compact latent space, which not only offers ample control over the generative process but also can be leveraged for downstream tasks. Experimental results show that EEGDM (1) can reconstruct high-quality EEG signals, (2) effectively learns robust representations, and (3) achieves competitive performance with modest pre-training data size across diverse downstream tasks, underscoring its generalizability and practical utility.
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Sep 30, 2023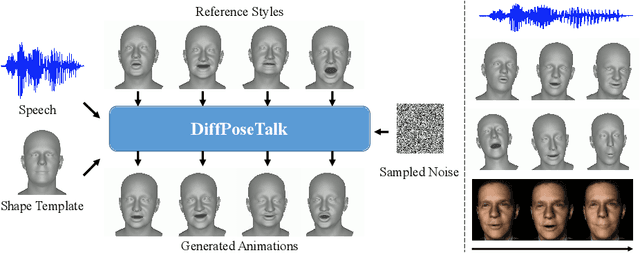
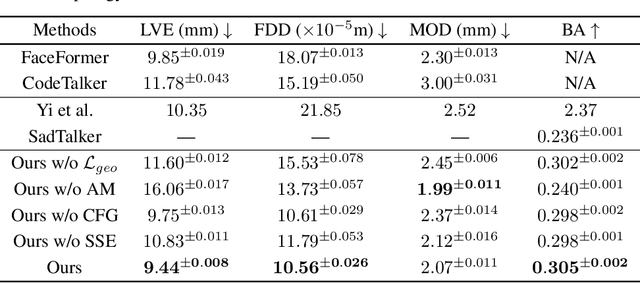
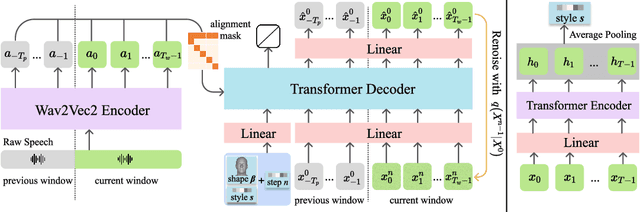
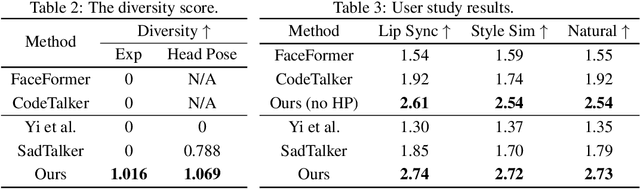
The generation of stylistic 3D facial animations driven by speech poses a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. We extend this to include the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Our extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset will be made publicly available.
3D-CariGAN: An End-to-End Solution to 3D Caricature Generation from Face Photos
Mar 15, 2020

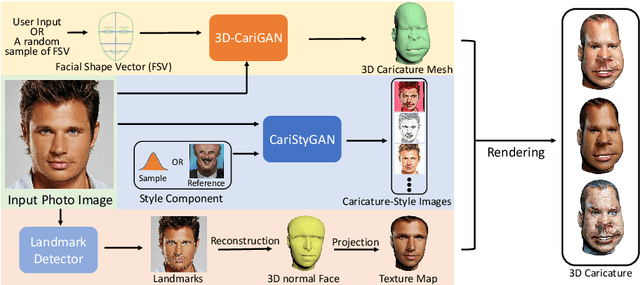
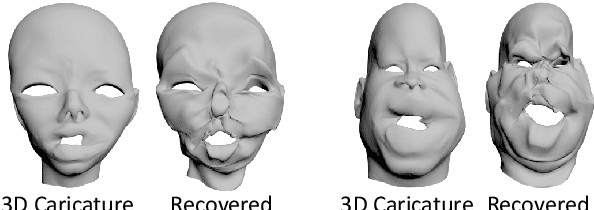
Caricature is a kind of artistic style of human faces that attracts considerable research in computer vision. So far all existing 3D caricature generation methods require some information related to caricature as input, e.g., a caricature sketch or 2D caricature. However, this kind of input is difficult to provide by non-professional users. In this paper, we propose an end-to-end deep neural network model to generate high-quality 3D caricature with a simple face photo as input. The most challenging issue in our system is that the source domain of face photos (characterized by 2D normal faces) is significantly different from the target domain of 3D caricatures (characterized by 3D exaggerated face shapes and texture). To address this challenge, we (1) build a large dataset of 6,100 3D caricature meshes and use it to establish a PCA model in the 3D caricature shape space and (2) detect landmarks in the input face photo and use them to set up correspondence between 2D caricature and 3D caricature shape. Our system can automatically generate high-quality 3D caricatures. In many situations, users want to control the output by a simple and intuitive way, so we further introduce a simple-to-use interactive control with three horizontal and one vertical lines. Experiments and user studies show that our system is easy to use and can generate high-quality 3D caricatures.