 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$S^3$LAM: Surfel Splatting SLAM for Geometrically Accurate Tracking and Mapping
Jul 28, 2025We propose $S^3$LAM, a novel RGB-D SLAM system that leverages 2D surfel splatting to achieve highly accurate geometric representations for simultaneous tracking and mapping. Unlike existing 3DGS-based SLAM approaches that rely on 3D Gaussian ellipsoids, we utilize 2D Gaussian surfels as primitives for more efficient scene representation. By focusing on the surfaces of objects in the scene, this design enables $S^3$LAM to reconstruct high-quality geometry, benefiting both mapping and tracking. To address inherent SLAM challenges including real-time optimization under limited viewpoints, we introduce a novel adaptive surface rendering strategy that improves mapping accuracy while maintaining computational efficiency. We further derive camera pose Jacobians directly from 2D surfel splatting formulation, highlighting the importance of our geometrically accurate representation that improves tracking convergence. Extensive experiments on both synthetic and real-world datasets validate that $S^3$LAM achieves state-of-the-art performance. Code will be made publicly available.
Weighted Poisson-disk Resampling on Large-Scale Point Clouds
Dec 12, 2024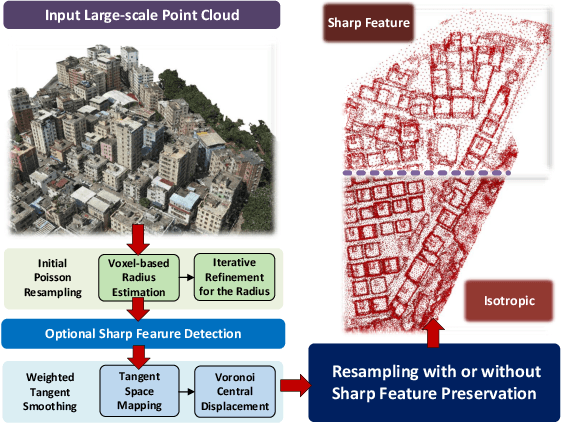



For large-scale point cloud processing, resampling takes the important role of controlling the point number and density while keeping the geometric consistency. % in related tasks. However, current methods cannot balance such different requirements. Particularly with large-scale point clouds, classical methods often struggle with decreased efficiency and accuracy. To address such issues, we propose a weighted Poisson-disk (WPD) resampling method to improve the usability and efficiency for the processing. We first design an initial Poisson resampling with a voxel-based estimation strategy. It is able to estimate a more accurate radius of the Poisson-disk while maintaining high efficiency. Then, we design a weighted tangent smoothing step to further optimize the Voronoi diagram for each point. At the same time, sharp features are detected and kept in the optimized results with isotropic property. Finally, we achieve a resampling copy from the original point cloud with the specified point number, uniform density, and high-quality geometric consistency. Experiments show that our method significantly improves the performance of large-scale point cloud resampling for different applications, and provides a highly practical solution.
DiveR-CT: Diversity-enhanced Red Teaming with Relaxing Constraints
May 29, 2024



Recent advances in large language models (LLMs) have made them indispensable, raising significant concerns over managing their safety. Automated red teaming offers a promising alternative to the labor-intensive and error-prone manual probing for vulnerabilities, providing more consistent and scalable safety evaluations. However, existing approaches often compromise diversity by focusing on maximizing attack success rate. Additionally, methods that decrease the cosine similarity from historical embeddings with semantic diversity rewards lead to novelty stagnation as history grows. To address these issues, we introduce DiveR-CT, which relaxes conventional constraints on the objective and semantic reward, granting greater freedom for the policy to enhance diversity. Our experiments demonstrate DiveR-CT's marked superiority over baselines by 1) generating data that perform better in various diversity metrics across different attack success rate levels, 2) better-enhancing resiliency in blue team models through safety tuning based on collected data, 3) allowing dynamic control of objective weights for reliable and controllable attack success rates, and 4) reducing susceptibility to reward overoptimization. Project details and code can be found at https://andrewzh112.github.io/#diverct.
SMaRt: Improving GANs with Score Matching Regularity
Nov 30, 2023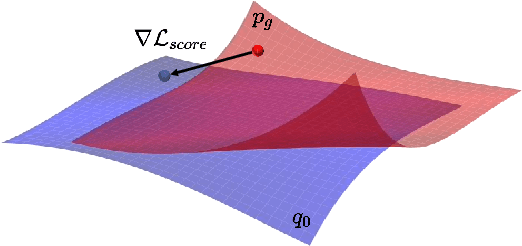

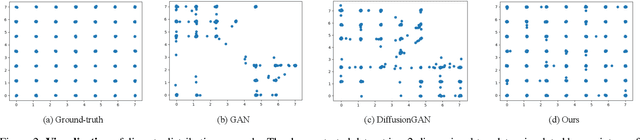
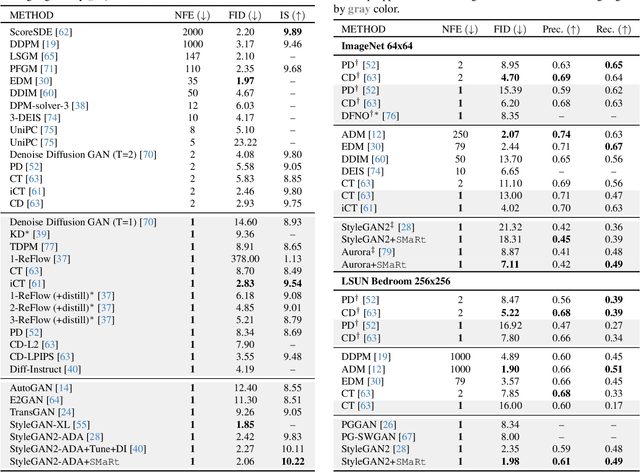
Generative adversarial networks (GANs) usually struggle in learning from highly diverse data, whose underlying manifold is complex. In this work, we revisit the mathematical foundations of GANs, and theoretically reveal that the native adversarial loss for GAN training is insufficient to fix the problem of subsets with positive Lebesgue measure of the generated data manifold lying out of the real data manifold. Instead, we find that score matching serves as a valid solution to this issue thanks to its capability of persistently pushing the generated data points towards the real data manifold. We thereby propose to improve the optimization of GANs with score matching regularity (SMaRt). Regarding the empirical evidences, we first design a toy example to show that training GANs by the aid of a ground-truth score function can help reproduce the real data distribution more accurately, and then confirm that our approach can consistently boost the synthesis performance of various state-of-the-art GANs on real-world datasets with pre-trained diffusion models acting as the approximate score function. For instance, when training Aurora on the ImageNet 64x64 dataset, we manage to improve FID from 8.87 to 7.11, on par with the performance of one-step consistency model. The source code will be made public.
Towards More Accurate Diffusion Model Acceleration with A Timestep Aligner
Oct 14, 2023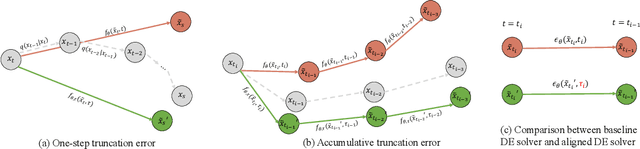
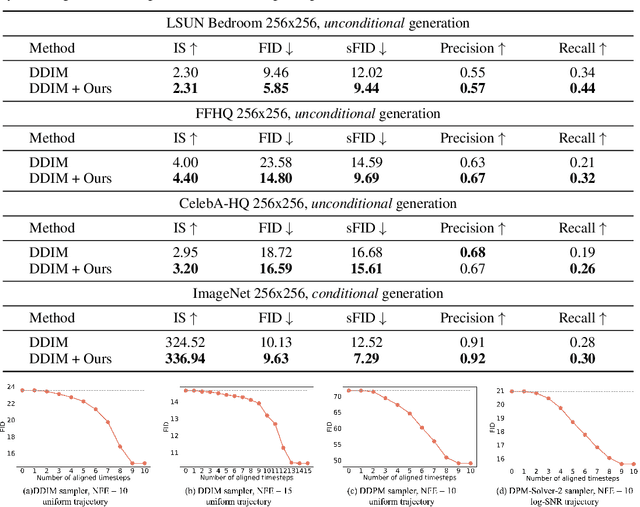
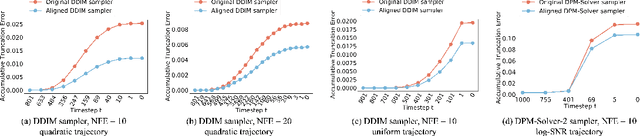

A diffusion model, which is formulated to produce an image using thousands of denoising steps, usually suffers from a slow inference speed. Existing acceleration algorithms simplify the sampling by skipping most steps yet exhibit considerable performance degradation. By viewing the generation of diffusion models as a discretized integrating process, we argue that the quality drop is partly caused by applying an inaccurate integral direction to a timestep interval. To rectify this issue, we propose a timestep aligner that helps find a more accurate integral direction for a particular interval at the minimum cost. Specifically, at each denoising step, we replace the original parameterization by conditioning the network on a new timestep, which is obtained by aligning the sampling distribution to the real distribution. Extensive experiments show that our plug-in design can be trained efficiently and boost the inference performance of various state-of-the-art acceleration methods, especially when there are few denoising steps. For example, when using 10 denoising steps on the popular LSUN Bedroom dataset, we improve the FID of DDIM from 9.65 to 6.07, simply by adopting our method for a more appropriate set of timesteps. Code will be made publicly available.
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Sep 30, 2023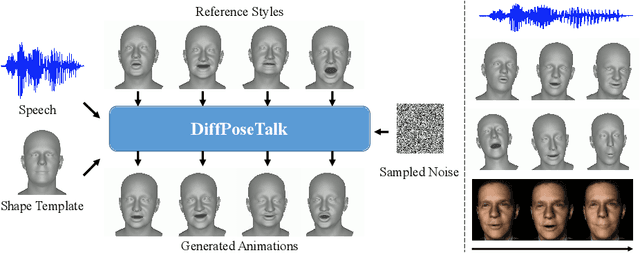
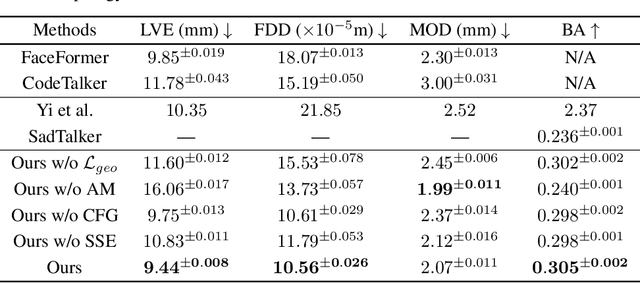
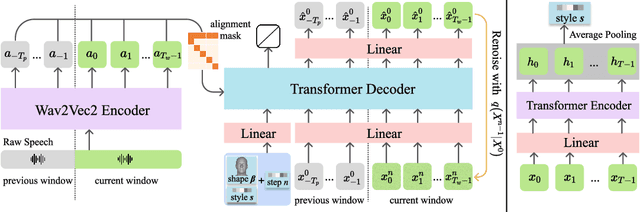
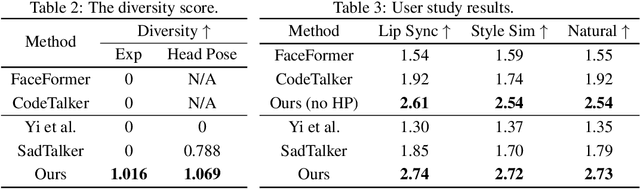
The generation of stylistic 3D facial animations driven by speech poses a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. We extend this to include the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Our extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset will be made publicly available.
Audio-Driven Talking Face Video Generation with Dynamic Convolution Kernels
Jan 16, 2022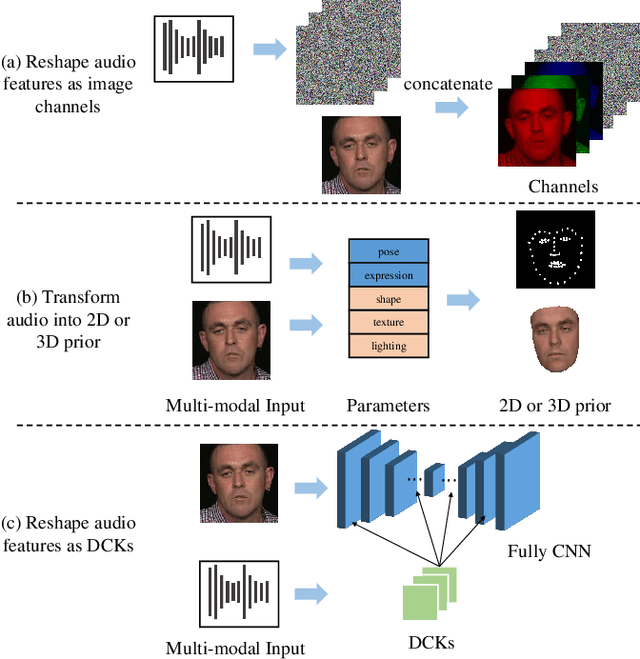
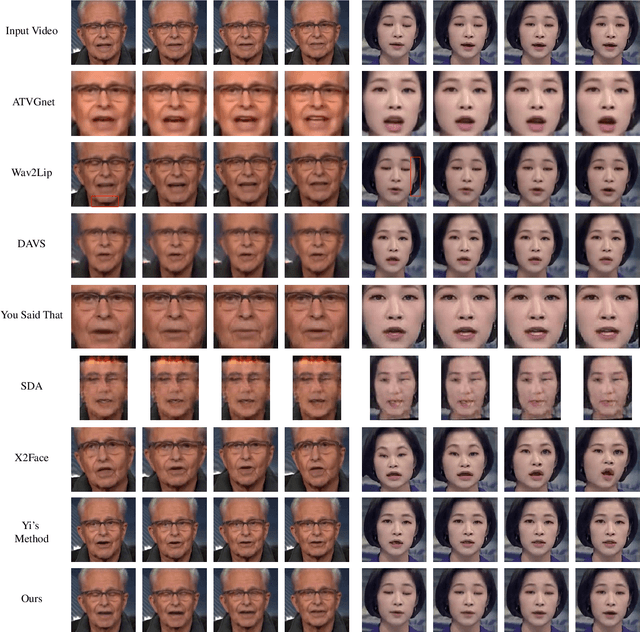
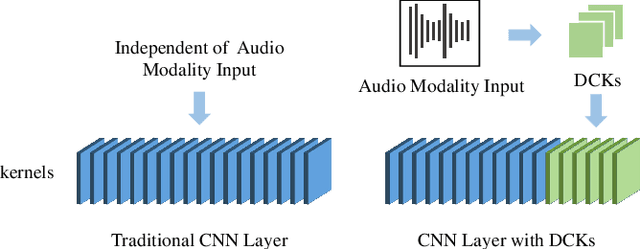
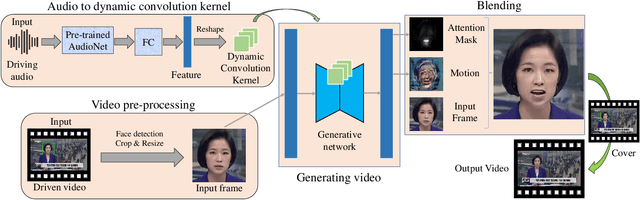
In this paper, we present a dynamic convolution kernel (DCK) strategy for convolutional neural networks. Using a fully convolutional network with the proposed DCKs, high-quality talking-face video can be generated from multi-modal sources (i.e., unmatched audio and video) in real time, and our trained model is robust to different identities, head postures, and input audios. Our proposed DCKs are specially designed for audio-driven talking face video generation, leading to a simple yet effective end-to-end system. We also provide a theoretical analysis to interpret why DCKs work. Experimental results show that our method can generate high-quality talking-face video with background at 60 fps. Comparison and evaluation between our method and the state-of-the-art methods demonstrate the superiority of our method.
PU-Flow: a Point Cloud Upsampling Networkwith Normalizing Flows
Jul 13, 2021
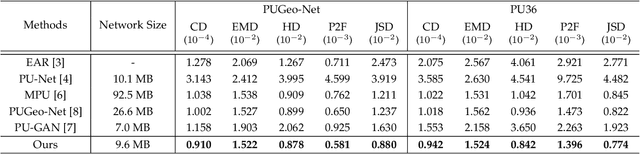


Point cloud upsampling aims to generate dense point clouds from given sparse ones, which is a challenging task due to the irregular and unordered nature of point sets. To address this issue, we present a novel deep learning-based model, called PU-Flow,which incorporates normalizing flows and feature interpolation techniques to produce dense points uniformly distributed on the underlying surface. Specifically, we formulate the upsampling process as point interpolation in a latent space, where the interpolation weights are adaptively learned from local geometric context, and exploit the invertible characteristics of normalizing flows to transform points between Euclidean and latent spaces. We evaluate PU-Flow on a wide range of 3D models with sharp features and high-frequency details. Qualitative and quantitative results show that our method outperforms state-of-the-art deep learning-based approaches in terms of reconstruction quality, proximity-to-surface accuracy, and computation efficiency.
3D-CariGAN: An End-to-End Solution to 3D Caricature Generation from Face Photos
Mar 15, 2020

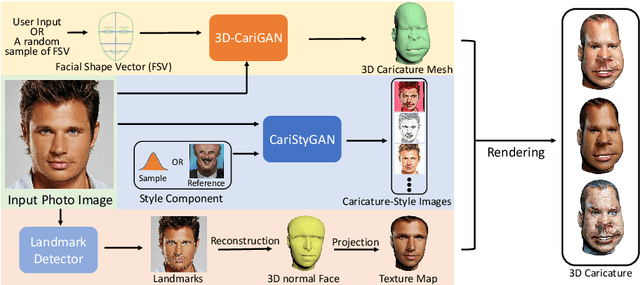
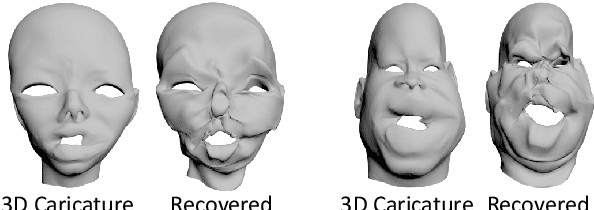
Caricature is a kind of artistic style of human faces that attracts considerable research in computer vision. So far all existing 3D caricature generation methods require some information related to caricature as input, e.g., a caricature sketch or 2D caricature. However, this kind of input is difficult to provide by non-professional users. In this paper, we propose an end-to-end deep neural network model to generate high-quality 3D caricature with a simple face photo as input. The most challenging issue in our system is that the source domain of face photos (characterized by 2D normal faces) is significantly different from the target domain of 3D caricatures (characterized by 3D exaggerated face shapes and texture). To address this challenge, we (1) build a large dataset of 6,100 3D caricature meshes and use it to establish a PCA model in the 3D caricature shape space and (2) detect landmarks in the input face photo and use them to set up correspondence between 2D caricature and 3D caricature shape. Our system can automatically generate high-quality 3D caricatures. In many situations, users want to control the output by a simple and intuitive way, so we further introduce a simple-to-use interactive control with three horizontal and one vertical lines. Experiments and user studies show that our system is easy to use and can generate high-quality 3D caricatures.
STD-Net: Structure-preserving and Topology-adaptive Deformation Network for 3D Reconstruction from a Single Image
Mar 07, 2020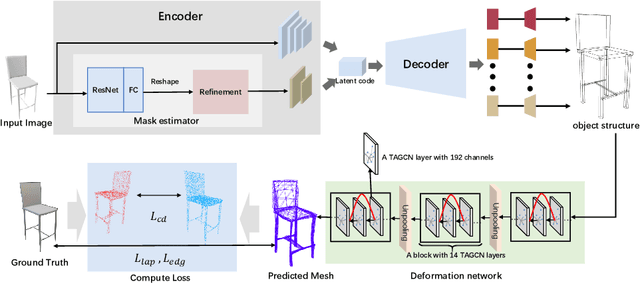

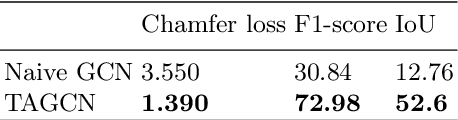
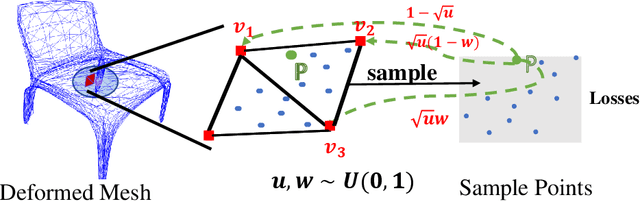
3D reconstruction from a single view image is a long-standing prob-lem in computer vision. Various methods based on different shape representations(such as point cloud or volumetric representations) have been proposed. However,the 3D shape reconstruction with fine details and complex structures are still chal-lenging and have not yet be solved. Thanks to the recent advance of the deepshape representations, it becomes promising to learn the structure and detail rep-resentation using deep neural networks. In this paper, we propose a novel methodcalled STD-Net to reconstruct the 3D models utilizing the mesh representationthat is well suitable for characterizing complex structure and geometry details.To reconstruct complex 3D mesh models with fine details, our method consists of(1) an auto-encoder network for recovering the structure of an object with bound-ing box representation from a single image, (2) a topology-adaptive graph CNNfor updating vertex position for meshes of complex topology, and (3) an unifiedmesh deformation block that deforms the structural boxes into structure-awaremeshed models. Experimental results on the images from ShapeNet show that ourproposed STD-Net has better performance than other state-of-the-art methods onreconstructing 3D objects with complex structures and fine geometric details.