 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAGNet: Grounding 3D Affordance from Human-Object Interactions in Videos
Feb 24, 20263D object affordance grounding aims to identify regions on 3D objects that support human-object interaction (HOI), a capability essential to embodied visual reasoning. However, most existing approaches rely on static visual or textual cues, neglecting that affordances are inherently defined by dynamic actions. As a result, they often struggle to localize the true contact regions involved in real interactions. We take a different perspective. Humans learn how to use objects by observing and imitating actions, not just by examining shapes. Motivated by this intuition, we introduce video-guided 3D affordance grounding, which leverages dynamic interaction sequences to provide functional supervision. To achieve this, we propose VAGNet, a framework that aligns video-derived interaction cues with 3D structure to resolve ambiguities that static cues cannot address. To support this new setting, we introduce PVAD, the first HOI video-3D pairing affordance dataset, providing functional supervision unavailable in prior works. Extensive experiments on PVAD show that VAGNet achieves state-of-the-art performance, significantly outperforming static-based baselines. The code and dataset will be open publicly.
DMF-Net: Image-Guided Point Cloud Completion with Dual-Channel Modality Fusion and Shape-Aware Upsampling Transformer
Jun 25, 2024



In this paper we study the task of a single-view image-guided point cloud completion. Existing methods have got promising results by fusing the information of image into point cloud explicitly or implicitly. However, given that the image has global shape information and the partial point cloud has rich local details, We believe that both modalities need to be given equal attention when performing modality fusion. To this end, we propose a novel dual-channel modality fusion network for image-guided point cloud completion(named DMF-Net), in a coarse-to-fine manner. In the first stage, DMF-Net takes a partial point cloud and corresponding image as input to recover a coarse point cloud. In the second stage, the coarse point cloud will be upsampled twice with shape-aware upsampling transformer to get the dense and complete point cloud. Extensive quantitative and qualitative experimental results show that DMF-Net outperforms the state-of-the-art unimodal and multimodal point cloud completion works on ShapeNet-ViPC dataset.
PD-Flow: A Point Cloud Denoising Framework with Normalizing Flows
Mar 11, 2022

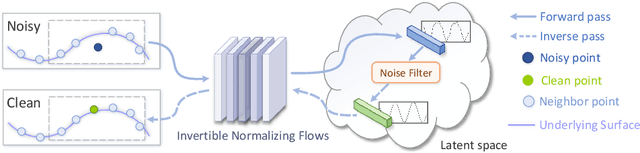
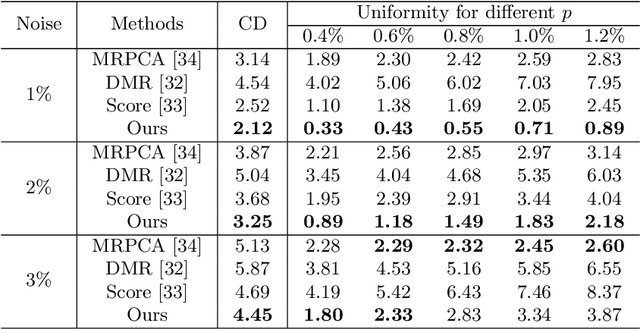
Point cloud denoising aims to restore clean point clouds from raw observations corrupted by noise and outliers while preserving the fine-grained details. We present a novel deep learning-based denoising model, that incorporates normalizing flows and noise disentanglement techniques to achieve high denoising accuracy. Unlike existing works that extract features of point clouds for point-wise correction, we formulate the denoising process from the perspective of distribution learning and feature disentanglement. By considering noisy point clouds as a joint distribution of clean points and noise, the denoised results can be derived from disentangling the noise counterpart from latent point representation, and the mapping between Euclidean and latent spaces is modeled by normalizing flows. We evaluate our method on synthesized 3D models and real-world datasets with various noise settings. Qualitative and quantitative results show that our method outperforms previous state-of-the-art deep learning-based approaches. %in terms of detail preservation and distribution uniformity.
PU-Flow: a Point Cloud Upsampling Networkwith Normalizing Flows
Jul 13, 2021
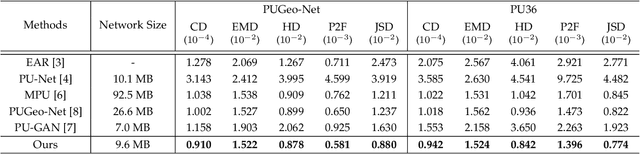


Point cloud upsampling aims to generate dense point clouds from given sparse ones, which is a challenging task due to the irregular and unordered nature of point sets. To address this issue, we present a novel deep learning-based model, called PU-Flow,which incorporates normalizing flows and feature interpolation techniques to produce dense points uniformly distributed on the underlying surface. Specifically, we formulate the upsampling process as point interpolation in a latent space, where the interpolation weights are adaptively learned from local geometric context, and exploit the invertible characteristics of normalizing flows to transform points between Euclidean and latent spaces. We evaluate PU-Flow on a wide range of 3D models with sharp features and high-frequency details. Qualitative and quantitative results show that our method outperforms state-of-the-art deep learning-based approaches in terms of reconstruction quality, proximity-to-surface accuracy, and computation efficiency.
STD-Net: Structure-preserving and Topology-adaptive Deformation Network for 3D Reconstruction from a Single Image
Mar 07, 2020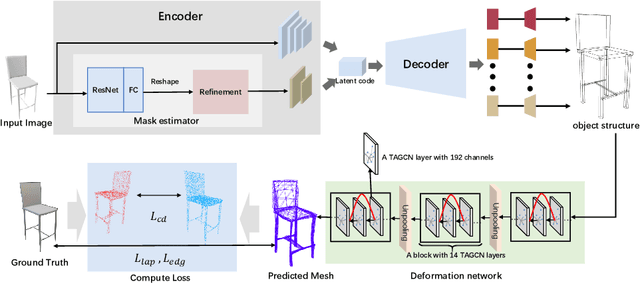

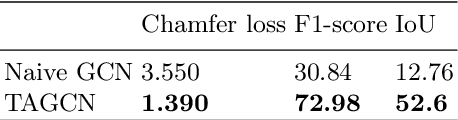
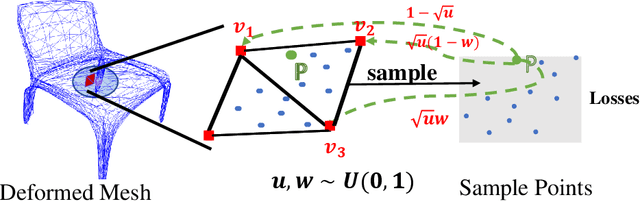
3D reconstruction from a single view image is a long-standing prob-lem in computer vision. Various methods based on different shape representations(such as point cloud or volumetric representations) have been proposed. However,the 3D shape reconstruction with fine details and complex structures are still chal-lenging and have not yet be solved. Thanks to the recent advance of the deepshape representations, it becomes promising to learn the structure and detail rep-resentation using deep neural networks. In this paper, we propose a novel methodcalled STD-Net to reconstruct the 3D models utilizing the mesh representationthat is well suitable for characterizing complex structure and geometry details.To reconstruct complex 3D mesh models with fine details, our method consists of(1) an auto-encoder network for recovering the structure of an object with bound-ing box representation from a single image, (2) a topology-adaptive graph CNNfor updating vertex position for meshes of complex topology, and (3) an unifiedmesh deformation block that deforms the structural boxes into structure-awaremeshed models. Experimental results on the images from ShapeNet show that ourproposed STD-Net has better performance than other state-of-the-art methods onreconstructing 3D objects with complex structures and fine geometric details.