 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Trigger Detection and Lightweight Model Repair Based Backdoor Defense
Jul 07, 2024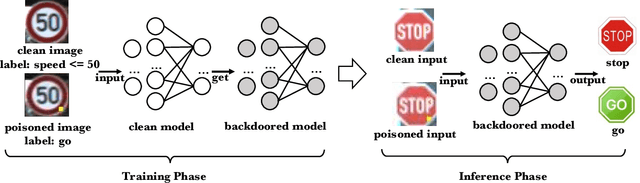
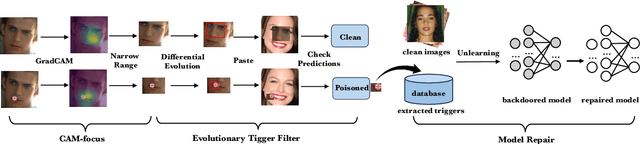

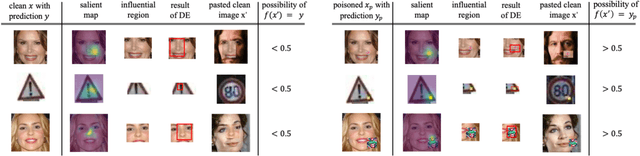
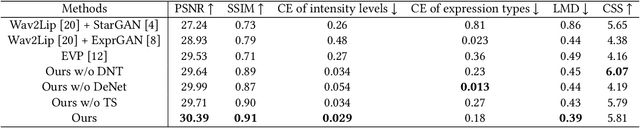
Deep Neural Networks (DNNs) have been widely used in many areas such as autonomous driving and face recognition. However, DNN model is fragile to backdoor attack. A backdoor in the DNN model can be activated by a poisoned input with trigger and leads to wrong prediction, which causes serious security issues in applications. It is challenging for current defenses to eliminate the backdoor effectively with limited computing resources, especially when the sizes and numbers of the triggers are variable as in the physical world. We propose an efficient backdoor defense based on evolutionary trigger detection and lightweight model repair. In the first phase of our method, CAM-focus Evolutionary Trigger Filter (CETF) is proposed for trigger detection. CETF is an effective sample-preprocessing based method with the evolutionary algorithm, and our experimental results show that CETF not only distinguishes the images with triggers accurately from the clean images, but also can be widely used in practice for its simplicity and stability in different backdoor attack situations. In the second phase of our method, we leverage several lightweight unlearning methods with the trigger detected by CETF for model repair, which also constructively demonstrate the underlying correlation of the backdoor with Batch Normalization layers. Source code will be published after accepted.
Dynamic Neural Textures: Generating Talking-Face Videos with Continuously Controllable Expressions
Apr 13, 2022


Recently, talking-face video generation has received considerable attention. So far most methods generate results with neutral expressions or expressions that are implicitly determined by neural networks in an uncontrollable way. In this paper, we propose a method to generate talking-face videos with continuously controllable expressions in real-time. Our method is based on an important observation: In contrast to facial geometry of moderate resolution, most expression information lies in textures. Then we make use of neural textures to generate high-quality talking face videos and design a novel neural network that can generate neural textures for image frames (which we called dynamic neural textures) based on the input expression and continuous intensity expression coding (CIEC). Our method uses 3DMM as a 3D model to sample the dynamic neural texture. The 3DMM does not cover the teeth area, so we propose a teeth submodule to complete the details in teeth. Results and an ablation study show the effectiveness of our method in generating high-quality talking-face videos with continuously controllable expressions. We also set up four baseline methods by combining existing representative methods and compare them with our method. Experimental results including a user study show that our method has the best performance.
Audio-Driven Talking Face Video Generation with Dynamic Convolution Kernels
Jan 16, 2022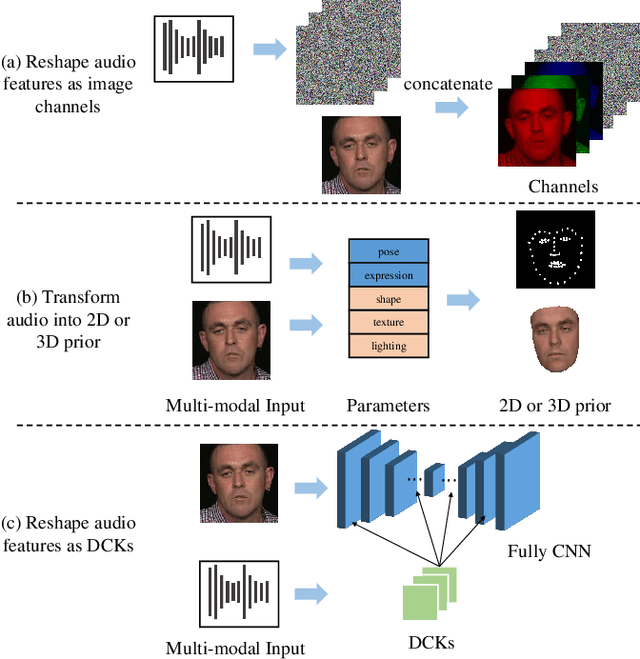
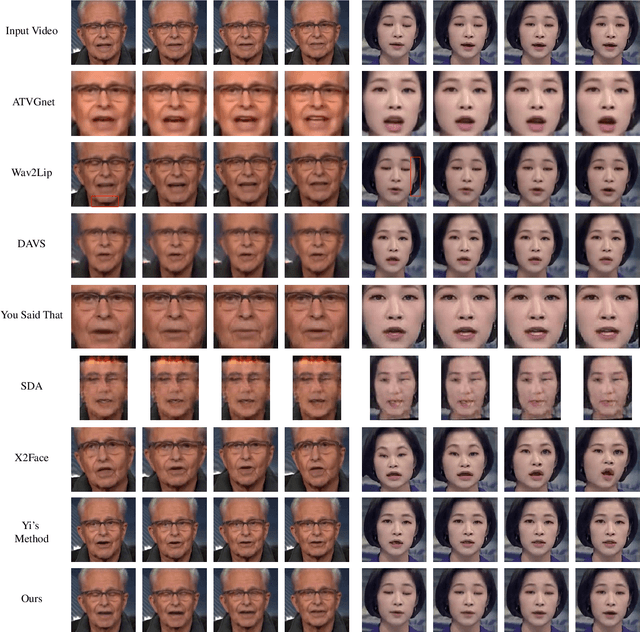
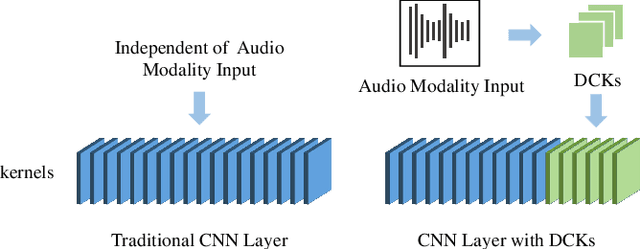
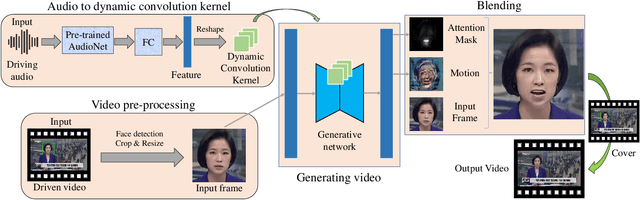
In this paper, we present a dynamic convolution kernel (DCK) strategy for convolutional neural networks. Using a fully convolutional network with the proposed DCKs, high-quality talking-face video can be generated from multi-modal sources (i.e., unmatched audio and video) in real time, and our trained model is robust to different identities, head postures, and input audios. Our proposed DCKs are specially designed for audio-driven talking face video generation, leading to a simple yet effective end-to-end system. We also provide a theoretical analysis to interpret why DCKs work. Experimental results show that our method can generate high-quality talking-face video with background at 60 fps. Comparison and evaluation between our method and the state-of-the-art methods demonstrate the superiority of our method.
3D-CariGAN: An End-to-End Solution to 3D Caricature Generation from Face Photos
Mar 15, 2020

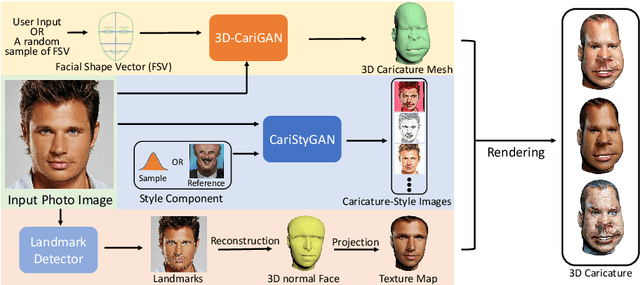
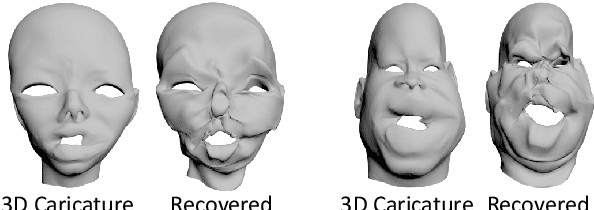
Caricature is a kind of artistic style of human faces that attracts considerable research in computer vision. So far all existing 3D caricature generation methods require some information related to caricature as input, e.g., a caricature sketch or 2D caricature. However, this kind of input is difficult to provide by non-professional users. In this paper, we propose an end-to-end deep neural network model to generate high-quality 3D caricature with a simple face photo as input. The most challenging issue in our system is that the source domain of face photos (characterized by 2D normal faces) is significantly different from the target domain of 3D caricatures (characterized by 3D exaggerated face shapes and texture). To address this challenge, we (1) build a large dataset of 6,100 3D caricature meshes and use it to establish a PCA model in the 3D caricature shape space and (2) detect landmarks in the input face photo and use them to set up correspondence between 2D caricature and 3D caricature shape. Our system can automatically generate high-quality 3D caricatures. In many situations, users want to control the output by a simple and intuitive way, so we further introduce a simple-to-use interactive control with three horizontal and one vertical lines. Experiments and user studies show that our system is easy to use and can generate high-quality 3D caricatures.
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose
Mar 05, 2020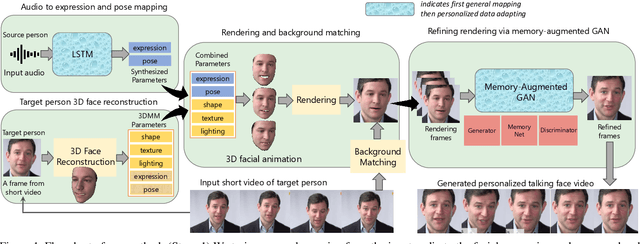
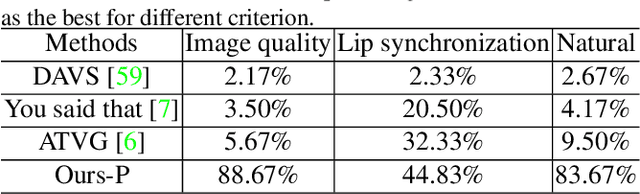
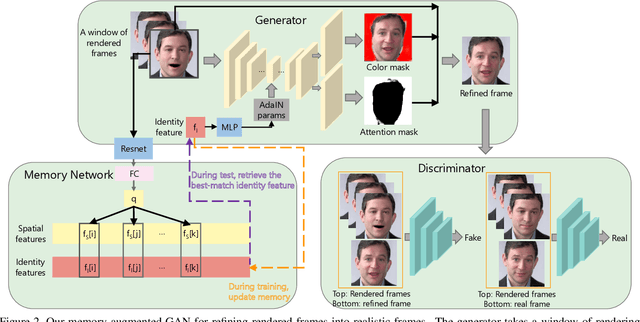
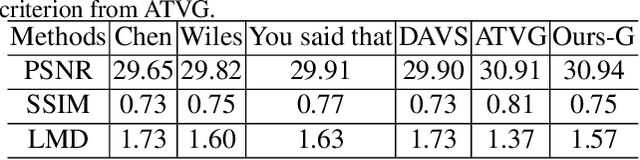
Real-world talking faces often accompany with natural head movement. However, most existing talking face video generation methods only consider facial animation with fixed head pose. In this paper, we address this problem by proposing a deep neural network model that takes an audio signal A of a source person and a very short video V of a target person as input, and outputs a synthesized high-quality talking face video with personalized head pose (making use of the visual information in V), expression and lip synchronization (by considering both A and V). The most challenging issue in our work is that natural poses often cause in-plane and out-of-plane head rotations, which makes synthesized talking face video far from realistic. To address this challenge, we reconstruct 3D face animation and re-render it into synthesized frames. To fine tune these frames into realistic ones with smooth background transition, we propose a novel memory-augmented GAN module. By first training a general mapping based on a publicly available dataset and fine-tuning the mapping using the input short video of target person, we develop an effective strategy that only requires a small number of frames (about 300 frames) to learn personalized talking behavior including head pose. Extensive experiments and two user studies show that our method can generate high-quality (i.e., personalized head movements, expressions and good lip synchronization) talking face videos, which are naturally looking with more distinguishing head movement effects than the state-of-the-art methods.
A Configuration-Space Decomposition Scheme for Learning-based Collision Checking
Nov 17, 2019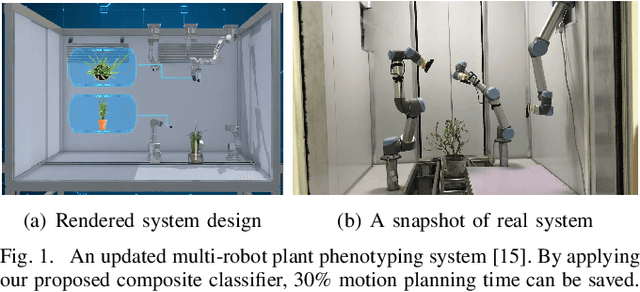
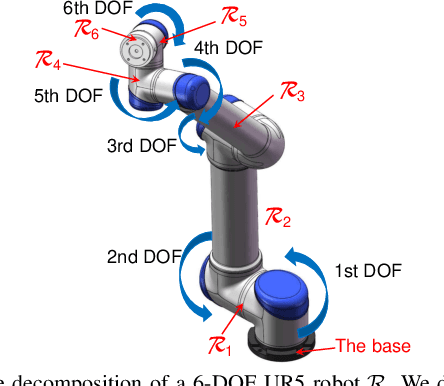
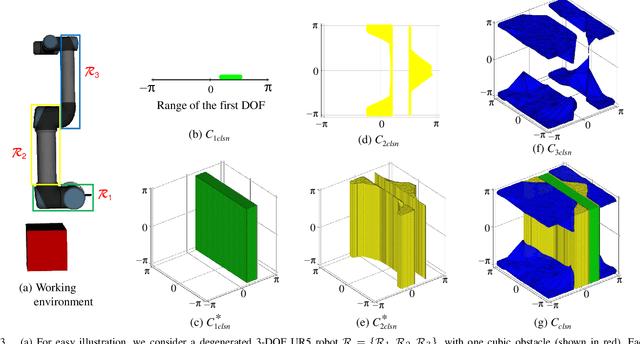

Motion planning for robots of high degrees-of-freedom (DOFs) is an important problem in robotics with sampling-based methods in configuration space C as one popular solution. Recently, machine learning methods have been introduced into sampling-based motion planning methods, which train a classifier to distinguish collision free subspace from in-collision subspace in C. In this paper, we propose a novel configuration space decomposition method and show two nice properties resulted from this decomposition. Using these two properties, we build a composite classifier that works compatibly with previous machine learning methods by using them as the elementary classifiers. Experimental results are presented, showing that our composite classifier outperforms state-of-the-art single classifier methods by a large margin. A real application of motion planning in a multi-robot system in plant phenotyping using three UR5 robotic arms is also presented.