 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Backdoor Adversarial Unlearning through the Lens of Catastrophic Forgetting in Continual Learning
Jun 12, 2026Existing studies reveal that current backdoor defenses exhibit limited robustness and often fail against specific types of attacks. More concerningly, prevailing safety tuning strategies tend to provide only superficial safety protection, as they fall short of completely eliminating the backdoor effects. In this work, we present a novel formulation of backdoor learning and unlearning as a sequential, three-stage process from a continual learning perspective. Within this framework, we formally define complete backdoor unlearning and further derive the necessary conditions for achieving it based on the mechanism of catastrophic forgetting. Guided by these insights, we propose Blind Inversion-Backdoor Adversarial Unlearning (BI-BAU), which formulates the generation of adversarial examples satisfying the unlearning conditions as a blind inversion problem. We solve this by integrating the bi-level optimization process of adversarial training into an Expectation-Maximization (EM) algorithm framework to optimize the maximum a posteriori (MAP) objective. Furthermore, BI-BAU is extended to untargeted adversarial scenarios with unknown target classes, as well as to multi-modal contrastive learning tasks, enhancing its applicability to real-world deployment scenarios where pre-trained models may be compromised. Extensive experiments demonstrate that our method exhibits general applicability across a wide spectrum of backdoor attacks and can effectively and thoroughly eliminate the backdoor effects from a backdoor model.
From Parameters to Feature Space: Task Arithmetic for Backdoor Mitigation in Model Merging
Jun 10, 2026Model merging (MM) has gained significant attention as a cost-effective approach to integrate multiple task-specific models into a unified model. However, recent work reveals that MM is highly susceptible to backdoor attacks. Existing defenses based on task arithmetic often fail to eliminate backdoors without substantially degrading clean-task performance, owing to their reliance on direct parameter-space editing. To address this gap, we propose Linear Feature Path Minimization (LFPM), a backdoor mitigation framework for model merging, which introduces an anti-backdoor task vector into the backdoored merged model. Unlike prior approaches, LFPM formulates the backdoor robustness of the merged model from a unified feature-space perspective under the Cross-Task Linearity (CTL) framework, which leverages the approximate linearity of features across tasks. This perspective guides the optimization of the anti-backdoor task to suppress backdoors while preserving clean-task performance. Furthermore, we introduce an effective optimization mechanism based on gradient accumulation and loss path-integral, ensuring robust backdoor suppression along the interpolation path. Extensive experiments demonstrate that LFPM consistently exhibits strong robustness against backdoor attacks in both full fine-tuning and Parameter-Efficient Fine-Tuning (PEFT) settings.
Structure-Conditioned Actor-Critic Branches for Quality-Diversity Reinforcement Learning
Jun 07, 2026Quality-diversity reinforcement learning (QD-RL) aims to construct policy repertoires that contain both high-performing and behaviorally diverse policies. Existing QD-RL methods mainly diversify policy instances after rollout evaluation or use learned value information to improve policy quality and behavior targeting, while the learning branches that generate candidate policies remain less explored. This paper proposes SV-QD-RL, a structure-value coupled framework that represents each candidate as a structure-conditioned actor-critic branch. Each branch contains an actor, a structural mask, a branch-specific critic, a replay state, and evaluation attributes including behavior, return, sparsity, and value profile. The structural mask defines the actor subspace in which the branch learns, while the branch-specific critic and replay state shape its value-learning trajectory. A branch-aware QD archive then evaluates and retains branches according to behavioral quality, structural footprint, and value-profile information. Experiments on MuJoCo continuous-control tasks show that SV-QD-RL constructs policy repertoires with strong archive quality and behaviorally useful diversity. Ablation and diagnostic analyses further indicate that structural conditioning, critic differentiation, and memory-consistent refinement make complementary contributions to behavioral specialization. Schedule-aware repertoire evaluation shows that the learned archive provides selectable policy alternatives under changing behavior-level requirements. These results suggest that coupling actor structure with branch-specific value learning is an effective mechanism for generating diverse QD-RL policy repertoires.
Co-evolving Agent Architectures and Interpretable Reasoning for Automated Optimization
Apr 20, 2026Automating operations research (OR) with large language models (LLMs) remains limited by hand-crafted reasoning--execution workflows. Complex OR tasks require adaptive coordination among problem interpretation, mathematical formulation, solver selection, code generation, and iterative debugging. To address this limitation, we propose EvoOR-Agent, a co-evolutionary framework for automated optimization. The framework represents agent workflows as activity-on-edge (AOE)-style networks, making workflow topology, execution dependencies, and alternative reasoning paths explicit. On this representation, the framework maintains an architecture graph and evolves a population of reasoning individuals through graph-mediated path-conditioned recombination, multi-granularity semantic mutation, and elitist population update. A knowledge-base-assisted experience-acquisition module further injects reusable OR practices into initialization and semantic variation. Empirical results on heterogeneous OR benchmarks show that the proposed framework consistently improves over zero-shot LLMs, fixed-pipeline OR agents, and representative evolutionary agent frameworks. Case studies and ablation analyses further indicate that explicit architecture evolution and graph-supported reasoning-trajectory search contribute to both performance improvement and structural interpretability. These results suggest that treating agent architectures and reasoning trajectories as evolvable objects provides an effective route toward adaptive and interpretable automated optimization.
CDH-Bench: A Commonsense-Driven Hallucination Benchmark for Evaluating Visual Fidelity in Vision-Language Models
Apr 01, 2026Vision-language models (VLMs) achieve strong performance on many benchmarks, yet a basic reliability question remains underexplored: when visual evidence conflicts with commonsense, do models follow what is shown or what commonsense suggests? A characteristic failure in this setting is that the model overrides visual evidence and outputs the commonsense alternative. We term this phenomenon \textbf{commonsense-driven hallucination} (CDH). To evaluate it, we introduce \textbf{CDH-Bench}, a benchmark designed to create explicit \textbf{visual evidence--commonsense conflicts}. CDH-Bench covers three dimensions: \textit{counting anomalies}, \textit{relational anomalies}, and \textit{attribute anomalies}. We evaluate frontier VLMs under \textit{binary Question Answering (QA)} and \textit{multiple-choice QA}, and report metrics including \textit{Counterfactual Accuracy} (CF-Acc), \textit{Commonsense Accuracy} (CS-Acc), \textit{Counterfactual Accuracy Drop} (CFAD), \textit{Commonsense Collapse Rate} (CCR), and \textit{Relative Prior Dependency} (RPD). Results show that even strong models remain vulnerable to prior-driven normalization under visual evidence--commonsense conflict. CDH-Bench provides a controlled diagnostic of visual fidelity under visual evidence--commonsense conflict.
A Novel Immune Algorithm for Multiparty Multiobjective Optimization
Mar 29, 2026Traditional multiobjective optimization problems (MOPs) are insufficiently equipped for scenarios involving multiple decision makers (DMs), which are prevalent in many practical applications. These scenarios are categorized as multiparty multiobjective optimization problems (MPMOPs). For MPMOPs, the goal is to find a solution set that is as close to the Pareto front of each DM as much as possible. This poses challenges for evolutionary algorithms in terms of searching and selecting. To better solve MPMOPs, this paper proposes a novel approach called the multiparty immune algorithm (MPIA). The MPIA incorporates an inter-party guided crossover strategy based on the individual's non-dominated sorting ranks from different DM perspectives and an adaptive activation strategy based on the proposed multiparty cover metric (MCM). These strategies enable MPIA to activate suitable individuals for the next operations, maintain population diversity from different DM perspectives, and enhance the algorithm's search capability. To evaluate the performance of MPIA, we compare it with ordinary multiobjective evolutionary algorithms (MOEAs) and state-of-the-art multiparty multiobjective optimization evolutionary algorithms (MPMOEAs) by solving synthetic multiparty multiobjective problems and real-world biparty multiobjective unmanned aerial vehicle path planning (BPUAV-PP) problems involving multiple DMs. Experimental results demonstrate that MPIA outperforms other algorithms.
* \c{opyright} 2026 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Evolutionary Biparty Multiobjective UAV Path Planning: Problems and Empirical Comparisons
Mar 23, 2026Unmanned aerial vehicles (UAVs) have been widely used in urban missions, and proper planning of UAV paths can improve mission efficiency while reducing the risk of potential third-party impact. Existing work has considered all efficiency and safety objectives for a single decision-maker (DM) and regarded this as a multiobjective optimization problem (MOP). However, there is usually not a single DM but two DMs, i.e., an efficiency DM and a safety DM, and the DMs are only concerned with their respective objectives. The final decision is made based on the solutions of both DMs. In this paper, for the first time, biparty multiobjective UAV path planning (BPMO-UAVPP) problems involving both efficiency and safety departments are modeled. The existing multiobjective immune algorithm with nondominated neighbor-based selection (NNIA), the hybrid evolutionary framework for the multiobjective immune algorithm (HEIA), and the adaptive immune-inspired multiobjective algorithm (AIMA) are modified for solving the BPMO-UAVPP problem, and then biparty multiobjective optimization algorithms, including the BPNNIA, BPHEIA, and BPAIMA, are proposed and comprehensively compared with traditional multiobjective evolutionary algorithms and typical multiparty multiobjective evolutionary algorithms (i.e., OptMPNDS and OptMPNDS2). The experimental results show that BPAIMA performs better than ordinary multiobjective evolutionary algorithms such as NSGA-II and multiparty multiobjective evolutionary algorithms such as OptMPNDS, OptMPNDS2, BPNNIA and BPHEIA.
* \c{opyright} 2026 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
ReBeCA: Unveiling Interpretable Behavior Hierarchy behind the Iterative Self-Reflection of Language Models with Causal Analysis
Feb 06, 2026While self-reflection can enhance language model reliability, its underlying mechanisms remain opaque, with existing analyses often yielding correlation-based insights that fail to generalize. To address this, we introduce \textbf{\texttt{ReBeCA}} (self-\textbf{\texttt{Re}}flection \textbf{\texttt{Be}}havior explained through \textbf{\texttt{C}}ausal \textbf{\texttt{A}}nalysis), a framework that unveils the interpretable behavioral hierarchy governing the self-reflection outcome. By modeling self-reflection trajectories as causal graphs, ReBeCA isolates genuine determinants of performance through a three-stage Invariant Causal Prediction (ICP) pipeline. We establish three critical findings: (1) \textbf{Behavioral hierarchy:} Semantic behaviors of the model influence final self-reflection results hierarchically: directly or indirectly; (2) \textbf{Causation matters:} Generalizability in self-reflection effects is limited to just a few semantic behaviors; (3) \textbf{More $\mathbf{\neq}$ better:} The confluence of seemingly positive semantic behaviors, even among direct causal factors, can impair the efficacy of self-reflection. ICP-based verification identifies sparse causal parents achieving up to $49.6\%$ structural likelihood gains, stable across tasks where correlation-based patterns fail. Intervention studies on novel datasets confirm these causal relationships hold out-of-distribution ($p = .013, η^2_\mathrm{p} = .071$). ReBeCA thus provides a rigorous methodology for disentangling genuine causal mechanisms from spurious associations in self-reflection dynamics.
Fairness-Aware Performance Evaluation for Multi-Party Multi-Objective Optimization
Jan 30, 2026In multiparty multiobjective optimization problems, solution sets are usually evaluated using classical performance metrics, aggregated across DMs. However, such mean-based evaluations may be unfair by favoring certain parties, as they assume identical geometric approximation quality to each party's PF carries comparable evaluative significance. Moreover, prevailing notions of MPMOP optimal solutions are restricted to strictly common Pareto optimal solutions, representing a narrow form of cooperation in multiparty decision making scenarios. These limitations obscure whether a solution set reflects balanced relative gains or meaningful consensus among heterogeneous DMs. To address these issues, this paper develops a fairness-aware performance evaluation framework grounded in a generalized notion of consensus solutions. From a cooperative game-theoretic perspective, we formalize four axioms that a fairness-aware evaluation function for MPMOPs should satisfy. By introducing a concession rate vector to quantify acceptable compromises by individual DMs, we generalize the classical definition of MPMOP optimal solutions and embed classical performance metrics into a Nash-product-based evaluation framework, which is theoretically shown to satisfy all axioms. To support empirical validation, we further construct benchmark problems that extend existing MPMOP suites by incorporating consensus-deficient negotiation structures. Experimental results demonstrate that the proposed evaluation framework is able to distinguish algorithmic performance in a manner consistent with consensus-aware fairness considerations. Specifically, algorithms converging toward strictly common solutions are assigned higher evaluation scores when such solutions exist, whereas in the absence of strictly common solutions, algorithms that effectively cover the commonly acceptable region are more favorably evaluated.
BAMBO: Construct Ability and Efficiency LLM Pareto Set via Bayesian Adaptive Multi-objective Block-wise Optimization
Dec 12, 2025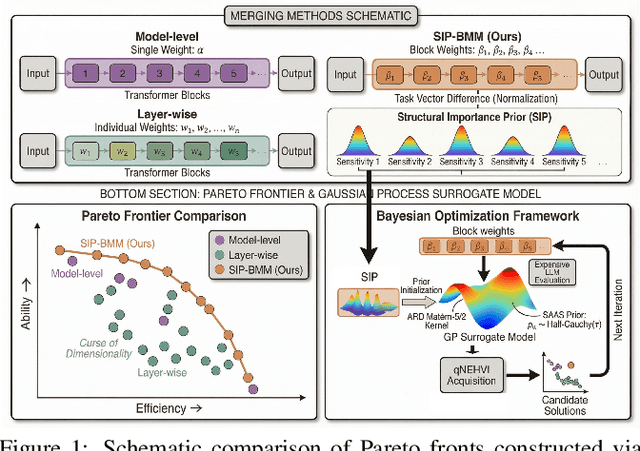



Constructing a Pareto set is pivotal for navigating the capability-efficiency trade-offs in Large Language Models (LLMs); however, existing merging techniques remain inadequate for this task. Coarse-grained, model-level methods yield only a sparse set of suboptimal solutions, while fine-grained, layer-wise approaches suffer from the "curse of dimensionality," rendering the search space computationally intractable. To resolve this dichotomy, we propose BAMBO (Bayesian Adaptive Multi-objective Block-wise Optimization), a novel framework that automatically constructs the LLM Pareto set. BAMBO renders the search tractable by introducing a Hybrid Optimal Block Partitioning strategy. Formulated as a 1D clustering problem, this strategy leverages a dynamic programming approach to optimally balance intra-block homogeneity and inter-block information distribution, thereby dramatically reducing dimensionality without sacrificing critical granularity. The entire process is automated within an evolutionary loop driven by the q-Expected Hypervolume Improvement (qEHVI) acquisition function. Experiments demonstrate that BAMBO discovers a superior and more comprehensive Pareto frontier than baselines, enabling agile model selection tailored to diverse operational constraints. Code is available at: https://github.com/xin8coder/BAMBO.