 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagLLM: A Fine-Grained Tag Generation Approach for Note Recommendation
Mar 23, 2026Large Language Models (LLMs) have shown promising potential in E-commerce community recommendation. While LLMs and Multimodal LLMs (MLLMs) are widely used to encode notes into implicit embeddings, leveraging their generative capabilities to represent notes with interpretable tags remains unexplored. In the field of tag generation, traditional close-ended methods heavily rely on the design of tag pools, while existing open-ended methods applied directly to note recommendations face two limitations: (1) MLLMs lack guidance during generation, resulting in redundant tags that fail to capture user interests; (2) The generated tags are often coarse and lack fine-grained representation of notes, interfering with downstream recommendations. To address these limitations, we propose TagLLM, a fine-grained tag generation method for note recommendation. TagLLM captures user interests across note categories through a User Interest Handbook and constructs fine-grained tag data using multimodal CoT Extraction. A Tag Knowledge Distillation method is developed to equip small models with competitive generation capabilities, enhancing inference efficiency. In online A/B test, TagLLM increases average view duration per user by 0.31%, average interactions per user by 0.96%, and page view click-through rate in cold-start scenario by 32.37%, demonstrating its effectiveness.
Creation-MMBench: Assessing Context-Aware Creative Intelligence in MLLM
Mar 19, 2025



Creativity is a fundamental aspect of intelligence, involving the ability to generate novel and appropriate solutions across diverse contexts. While Large Language Models (LLMs) have been extensively evaluated for their creative capabilities, the assessment of Multimodal Large Language Models (MLLMs) in this domain remains largely unexplored. To address this gap, we introduce Creation-MMBench, a multimodal benchmark specifically designed to evaluate the creative capabilities of MLLMs in real-world, image-based tasks. The benchmark comprises 765 test cases spanning 51 fine-grained tasks. To ensure rigorous evaluation, we define instance-specific evaluation criteria for each test case, guiding the assessment of both general response quality and factual consistency with visual inputs. Experimental results reveal that current open-source MLLMs significantly underperform compared to proprietary models in creative tasks. Furthermore, our analysis demonstrates that visual fine-tuning can negatively impact the base LLM's creative abilities. Creation-MMBench provides valuable insights for advancing MLLM creativity and establishes a foundation for future improvements in multimodal generative intelligence. Full data and evaluation code is released on https://github.com/open-compass/Creation-MMBench.
GeneSUM: Large Language Model-based Gene Summary Extraction
Dec 24, 2024



Emerging topics in biomedical research are continuously expanding, providing a wealth of information about genes and their function. This rapid proliferation of knowledge presents unprecedented opportunities for scientific discovery and formidable challenges for researchers striving to keep abreast of the latest advancements. One significant challenge is navigating the vast corpus of literature to extract vital gene-related information, a time-consuming and cumbersome task. To enhance the efficiency of this process, it is crucial to address several key challenges: (1) the overwhelming volume of literature, (2) the complexity of gene functions, and (3) the automated integration and generation. In response, we propose GeneSUM, a two-stage automated gene summary extractor utilizing a large language model (LLM). Our approach retrieves and eliminates redundancy of target gene literature and then fine-tunes the LLM to refine and streamline the summarization process. We conducted extensive experiments to validate the efficacy of our proposed framework. The results demonstrate that LLM significantly enhances the integration of gene-specific information, allowing more efficient decision-making in ongoing research.
Showing Many Labels in Multi-label Classification Models: An Empirical Study of Adversarial Examples
Sep 26, 2024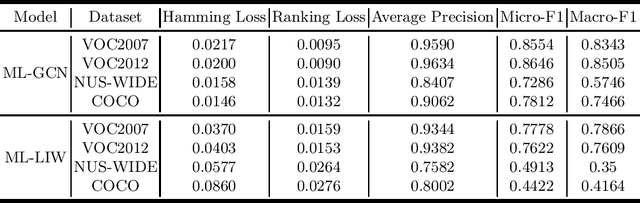
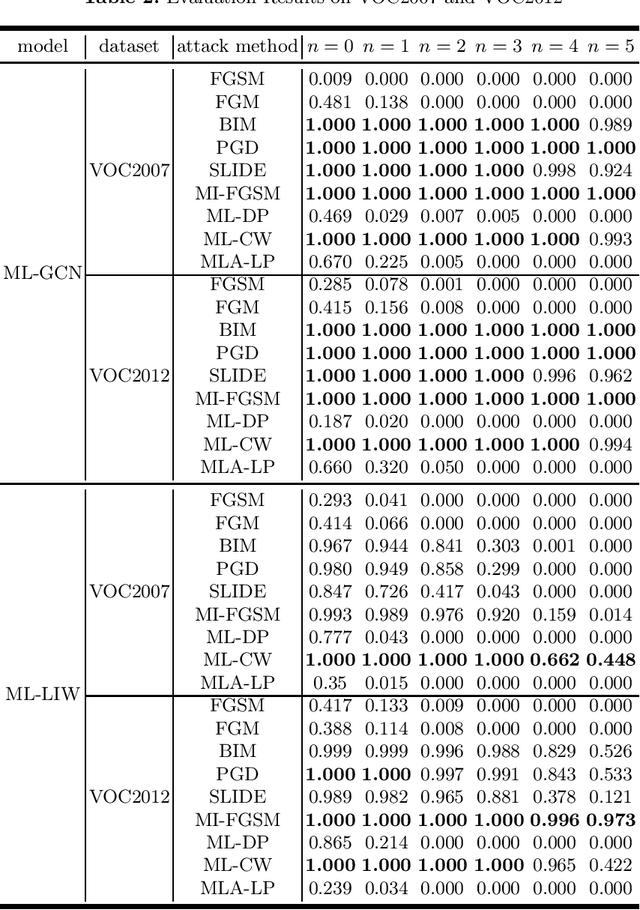
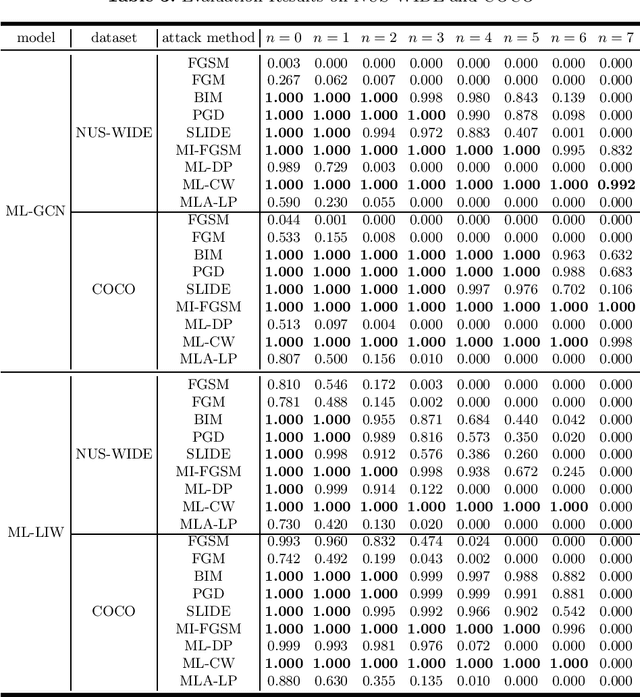
With the rapid development of Deep Neural Networks (DNNs), they have been applied in numerous fields. However, research indicates that DNNs are susceptible to adversarial examples, and this is equally true in the multi-label domain. To further investigate multi-label adversarial examples, we introduce a novel type of attacks, termed "Showing Many Labels". The objective of this attack is to maximize the number of labels included in the classifier's prediction results. In our experiments, we select nine attack algorithms and evaluate their performance under "Showing Many Labels". Eight of the attack algorithms were adapted from the multi-class environment to the multi-label environment, while the remaining one was specifically designed for the multi-label environment. We choose ML-LIW and ML-GCN as target models and train them on four popular multi-label datasets: VOC2007, VOC2012, NUS-WIDE, and COCO. We record the success rate of each algorithm when it shows the expected number of labels in eight different scenarios. Experimental results indicate that under the "Showing Many Labels", iterative attacks perform significantly better than one-step attacks. Moreover, it is possible to show all labels in the dataset.
HiLight: A Hierarchy-aware Light Global Model with Hierarchical Local ConTrastive Learning
Aug 11, 2024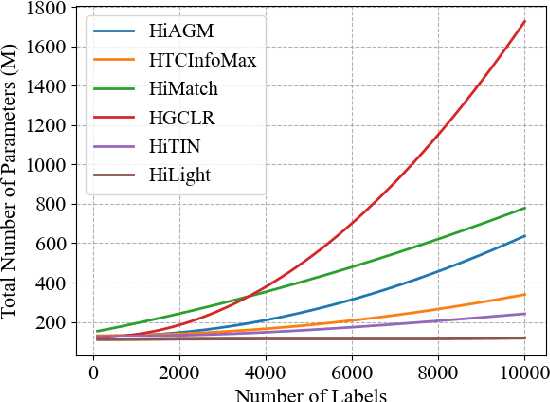

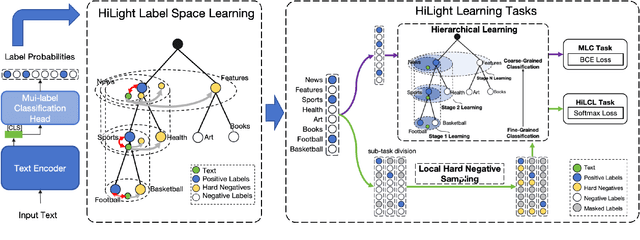
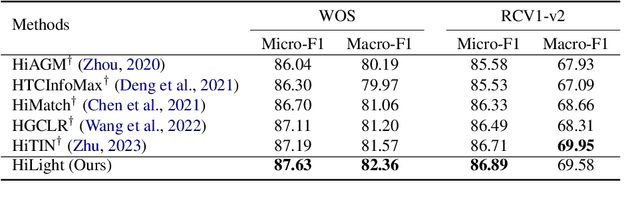
Hierarchical text classification (HTC) is a special sub-task of multi-label classification (MLC) whose taxonomy is constructed as a tree and each sample is assigned with at least one path in the tree. Latest HTC models contain three modules: a text encoder, a structure encoder and a multi-label classification head. Specially, the structure encoder is designed to encode the hierarchy of taxonomy. However, the structure encoder has scale problem. As the taxonomy size increases, the learnable parameters of recent HTC works grow rapidly. Recursive regularization is another widely-used method to introduce hierarchical information but it has collapse problem and generally relaxed by assigning with a small weight (ie. 1e-6). In this paper, we propose a Hierarchy-aware Light Global model with Hierarchical local conTrastive learning (HiLight), a lightweight and efficient global model only consisting of a text encoder and a multi-label classification head. We propose a new learning task to introduce the hierarchical information, called Hierarchical Local Contrastive Learning (HiLCL). Extensive experiments are conducted on two benchmark datasets to demonstrate the effectiveness of our model.
FashionSAP: Symbols and Attributes Prompt for Fine-grained Fashion Vision-Language Pre-training
Apr 11, 2023
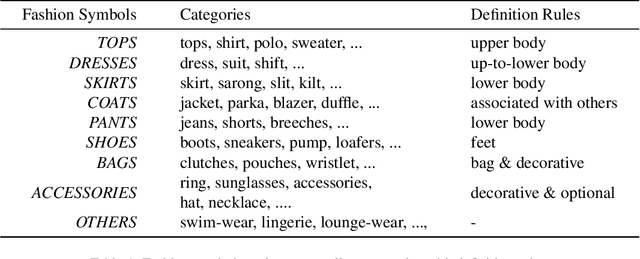
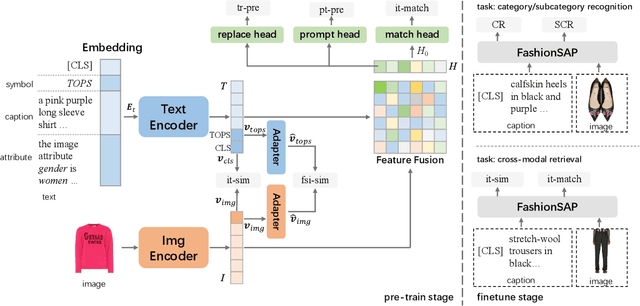
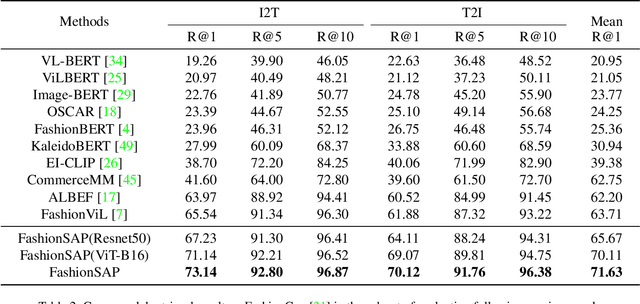
Fashion vision-language pre-training models have shown efficacy for a wide range of downstream tasks. However, general vision-language pre-training models pay less attention to fine-grained domain features, while these features are important in distinguishing the specific domain tasks from general tasks. We propose a method for fine-grained fashion vision-language pre-training based on fashion Symbols and Attributes Prompt (FashionSAP) to model fine-grained multi-modalities fashion attributes and characteristics. Firstly, we propose the fashion symbols, a novel abstract fashion concept layer, to represent different fashion items and to generalize various kinds of fine-grained fashion features, making modelling fine-grained attributes more effective. Secondly, the attributes prompt method is proposed to make the model learn specific attributes of fashion items explicitly. We design proper prompt templates according to the format of fashion data. Comprehensive experiments are conducted on two public fashion benchmarks, i.e., FashionGen and FashionIQ, and FashionSAP gets SOTA performances for four popular fashion tasks. The ablation study also shows the proposed abstract fashion symbols, and the attribute prompt method enables the model to acquire fine-grained semantics in the fashion domain effectively. The obvious performance gains from FashionSAP provide a new baseline for future fashion task research.
Replacement as a Self-supervision for Fine-grained Vision-language Pre-training
Mar 09, 2023



Fine-grained supervision based on object annotations has been widely used for vision and language pre-training (VLP). However, in real-world application scenarios, aligned multi-modal data is usually in the image-caption format, which only provides coarse-grained supervision. It is cost-expensive to collect object annotations and build object annotation pre-extractor for different scenarios. In this paper, we propose a fine-grained self-supervision signal without object annotations from a replacement perspective. First, we propose a homonym sentence rewriting (HSR) algorithm to provide token-level supervision. The algorithm replaces a verb/noun/adjective/quantifier word of the caption with its homonyms from WordNet. Correspondingly, we propose a replacement vision-language modeling (RVLM) framework to exploit the token-level supervision. Two replaced modeling tasks, i.e., replaced language contrastive (RLC) and replaced language modeling (RLM), are proposed to learn the fine-grained alignment. Extensive experiments on several downstream tasks demonstrate the superior performance of the proposed method.
Defending Adversarial Examples by Negative Correlation Ensemble
Jun 11, 2022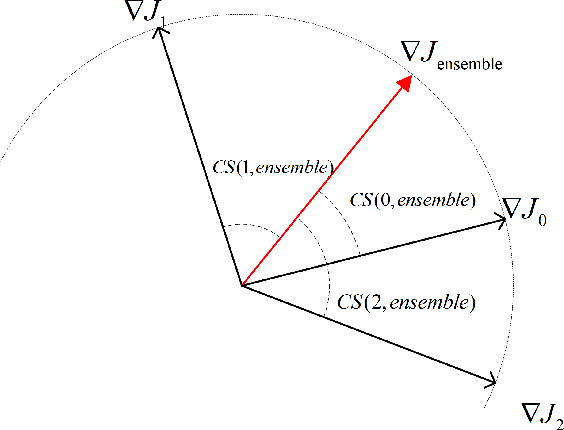
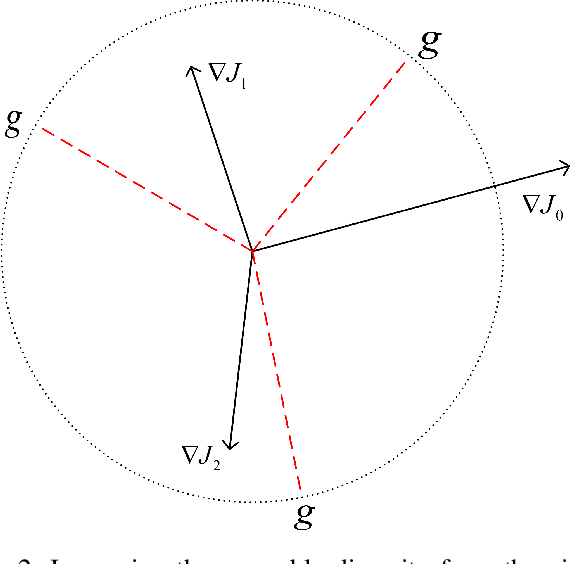
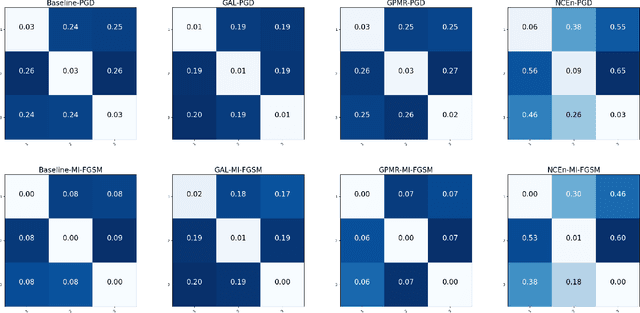
The security issues in DNNs, such as adversarial examples, have attracted much attention. Adversarial examples refer to the examples which are capable to induce the DNNs return completely predictions by introducing carefully designed perturbations. Obviously, adversarial examples bring great security risks to the development of deep learning. Recently, Some defense approaches against adversarial examples have been proposed, however, in our opinion, the performance of these approaches are still limited. In this paper, we propose a new ensemble defense approach named the Negative Correlation Ensemble (NCEn), which achieves compelling results by introducing gradient directions and gradient magnitudes of each member in the ensemble negatively correlated and at the same time, reducing the transferability of adversarial examples among them. Extensive experiments have been conducted, and the results demonstrate that NCEn can improve the adversarial robustness of ensembles effectively.