 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGE: A Multi-task Architecture for Gaze Estimation with an Efficient Calibration Module
May 22, 2025Eye gaze can provide rich information on human psychological activities, and has garnered significant attention in the field of Human-Robot Interaction (HRI). However, existing gaze estimation methods merely predict either the gaze direction or the Point-of-Gaze (PoG) on the screen, failing to provide sufficient information for a comprehensive six Degree-of-Freedom (DoF) gaze analysis in 3D space. Moreover, the variations of eye shape and structure among individuals also impede the generalization capability of these methods. In this study, we propose MAGE, a Multi-task Architecture for Gaze Estimation with an efficient calibration module, to predict the 6-DoF gaze information that is applicable for the real-word HRI. Our basic model encodes both the directional and positional features from facial images, and predicts gaze results with dedicated information flow and multiple decoders. To reduce the impact of individual variations, we propose a novel calibration module, namely Easy-Calibration, to fine-tune the basic model with subject-specific data, which is efficient to implement without the need of a screen. Experimental results demonstrate that our method achieves state-of-the-art performance on the public MPIIFaceGaze, EYEDIAP, and our built IMRGaze datasets.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Qwen2.5 Technical Report
Dec 19, 2024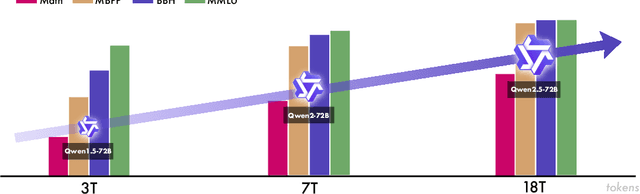

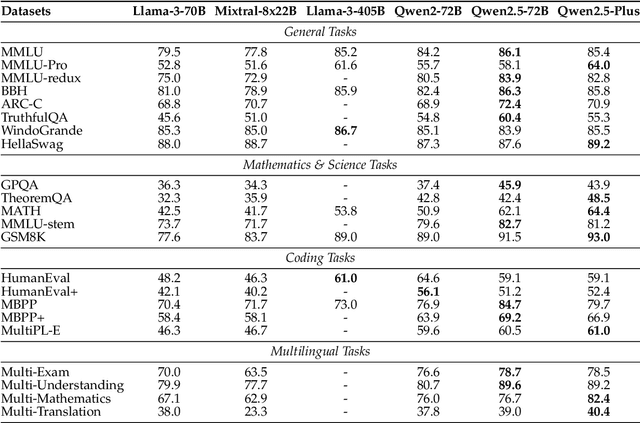
In this report, we introduce Qwen2.5, a comprehensive series of large language models (LLMs) designed to meet diverse needs. Compared to previous iterations, Qwen 2.5 has been significantly improved during both the pre-training and post-training stages. In terms of pre-training, we have scaled the high-quality pre-training datasets from the previous 7 trillion tokens to 18 trillion tokens. This provides a strong foundation for common sense, expert knowledge, and reasoning capabilities. In terms of post-training, we implement intricate supervised finetuning with over 1 million samples, as well as multistage reinforcement learning. Post-training techniques enhance human preference, and notably improve long text generation, structural data analysis, and instruction following. To handle diverse and varied use cases effectively, we present Qwen2.5 LLM series in rich sizes. Open-weight offerings include base and instruction-tuned models, with quantized versions available. In addition, for hosted solutions, the proprietary models currently include two mixture-of-experts (MoE) variants: Qwen2.5-Turbo and Qwen2.5-Plus, both available from Alibaba Cloud Model Studio. Qwen2.5 has demonstrated top-tier performance on a wide range of benchmarks evaluating language understanding, reasoning, mathematics, coding, human preference alignment, etc. Specifically, the open-weight flagship Qwen2.5-72B-Instruct outperforms a number of open and proprietary models and demonstrates competitive performance to the state-of-the-art open-weight model, Llama-3-405B-Instruct, which is around 5 times larger. Qwen2.5-Turbo and Qwen2.5-Plus offer superior cost-effectiveness while performing competitively against GPT-4o-mini and GPT-4o respectively. Additionally, as the foundation, Qwen2.5 models have been instrumental in training specialized models such as Qwen2.5-Math, Qwen2.5-Coder, QwQ, and multimodal models.
HiLight: A Hierarchy-aware Light Global Model with Hierarchical Local ConTrastive Learning
Aug 11, 2024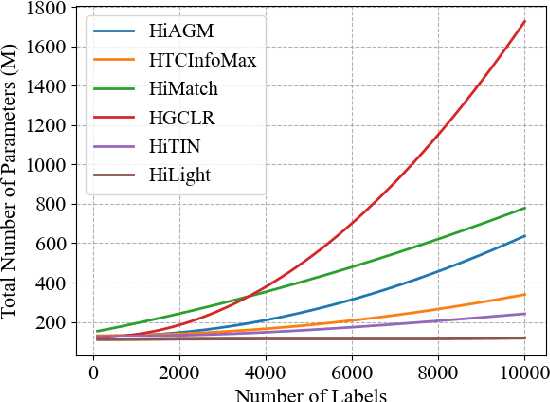

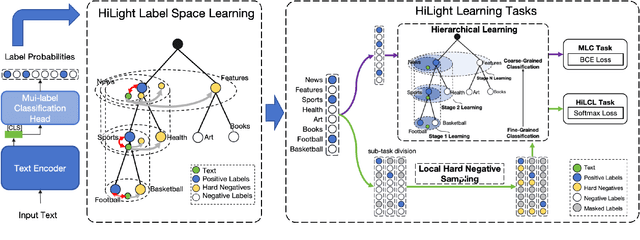
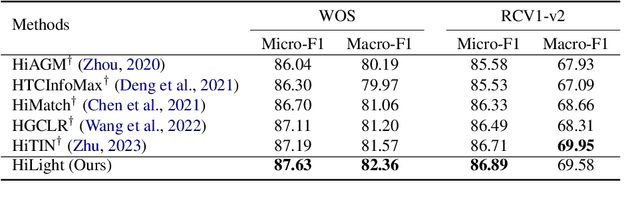
Hierarchical text classification (HTC) is a special sub-task of multi-label classification (MLC) whose taxonomy is constructed as a tree and each sample is assigned with at least one path in the tree. Latest HTC models contain three modules: a text encoder, a structure encoder and a multi-label classification head. Specially, the structure encoder is designed to encode the hierarchy of taxonomy. However, the structure encoder has scale problem. As the taxonomy size increases, the learnable parameters of recent HTC works grow rapidly. Recursive regularization is another widely-used method to introduce hierarchical information but it has collapse problem and generally relaxed by assigning with a small weight (ie. 1e-6). In this paper, we propose a Hierarchy-aware Light Global model with Hierarchical local conTrastive learning (HiLight), a lightweight and efficient global model only consisting of a text encoder and a multi-label classification head. We propose a new learning task to introduce the hierarchical information, called Hierarchical Local Contrastive Learning (HiLCL). Extensive experiments are conducted on two benchmark datasets to demonstrate the effectiveness of our model.
Semantic Human Mesh Reconstruction with Textures
Mar 05, 2024The field of 3D detailed human mesh reconstruction has made significant progress in recent years. However, current methods still face challenges when used in industrial applications due to unstable results, low-quality meshes, and a lack of UV unwrapping and skinning weights. In this paper, we present SHERT, a novel pipeline that can reconstruct semantic human meshes with textures and high-precision details. SHERT applies semantic- and normal-based sampling between the detailed surface (eg mesh and SDF) and the corresponding SMPL-X model to obtain a partially sampled semantic mesh and then generates the complete semantic mesh by our specifically designed self-supervised completion and refinement networks. Using the complete semantic mesh as a basis, we employ a texture diffusion model to create human textures that are driven by both images and texts. Our reconstructed meshes have stable UV unwrapping, high-quality triangle meshes, and consistent semantic information. The given SMPL-X model provides semantic information and shape priors, allowing SHERT to perform well even with incorrect and incomplete inputs. The semantic information also makes it easy to substitute and animate different body parts such as the face, body, and hands. Quantitative and qualitative experiments demonstrate that SHERT is capable of producing high-fidelity and robust semantic meshes that outperform state-of-the-art methods.
LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models
Nov 09, 2023We present LongQLoRA, an efficient and effective method to extend context length of large language models with less training resources. LongQLoRA combines the advantages of Position Interpolation, QLoRA and Shift Short Attention of LongLoRA. With a single 32GB V100 GPU, LongQLoRA can extend the context length of LLaMA2 7B and 13B from 4096 to 8192 and even to 12k within 1000 finetuning steps. LongQLoRA achieves competitive perplexity performance on PG19 and Proof-pile datasets, our model outperforms LongLoRA and is very close to MPT-7B-8K within the evaluation context length of 8192. We collect and build 39k long instruction data to extend context length of Vicuna-13B from 4096 to 8192 and achieve good performance both in long and short context generation task. We also do some ablation experiments to study the effect of LoRA rank, finetuning steps and attention patterns in inference.The model weights, training data and code are avaliable at https://github.com/yangjianxin1/LongQLoRA.
FashionSAP: Symbols and Attributes Prompt for Fine-grained Fashion Vision-Language Pre-training
Apr 11, 2023
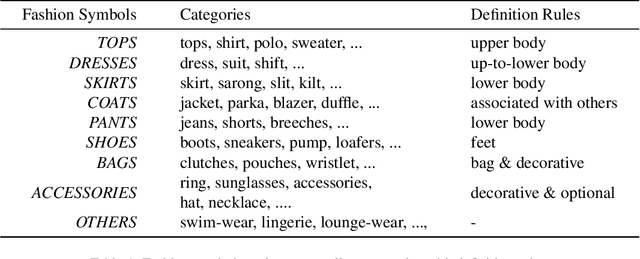
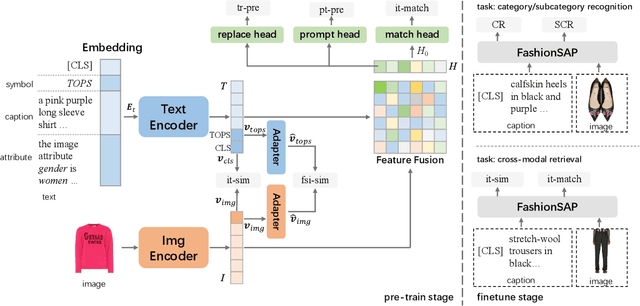
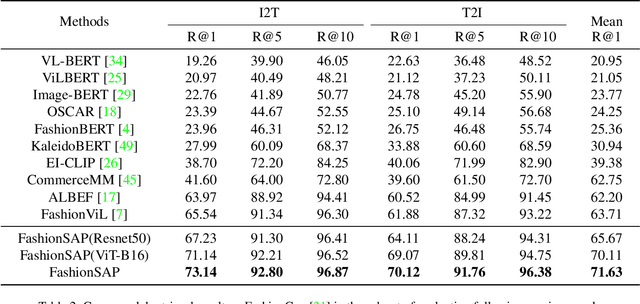
Fashion vision-language pre-training models have shown efficacy for a wide range of downstream tasks. However, general vision-language pre-training models pay less attention to fine-grained domain features, while these features are important in distinguishing the specific domain tasks from general tasks. We propose a method for fine-grained fashion vision-language pre-training based on fashion Symbols and Attributes Prompt (FashionSAP) to model fine-grained multi-modalities fashion attributes and characteristics. Firstly, we propose the fashion symbols, a novel abstract fashion concept layer, to represent different fashion items and to generalize various kinds of fine-grained fashion features, making modelling fine-grained attributes more effective. Secondly, the attributes prompt method is proposed to make the model learn specific attributes of fashion items explicitly. We design proper prompt templates according to the format of fashion data. Comprehensive experiments are conducted on two public fashion benchmarks, i.e., FashionGen and FashionIQ, and FashionSAP gets SOTA performances for four popular fashion tasks. The ablation study also shows the proposed abstract fashion symbols, and the attribute prompt method enables the model to acquire fine-grained semantics in the fashion domain effectively. The obvious performance gains from FashionSAP provide a new baseline for future fashion task research.
Occlusion-Invariant Rotation-Equivariant Semi-Supervised Depth Based Cross-View Gait Pose Estimation
Sep 03, 2021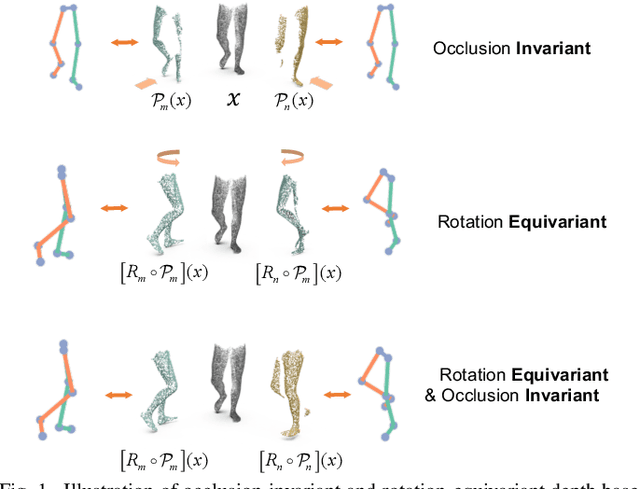
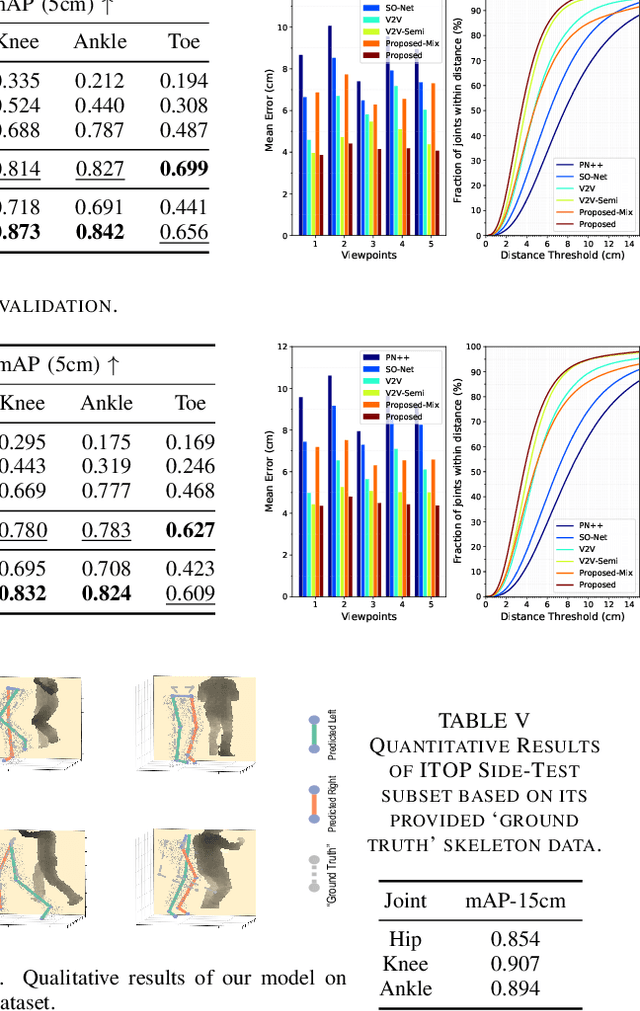
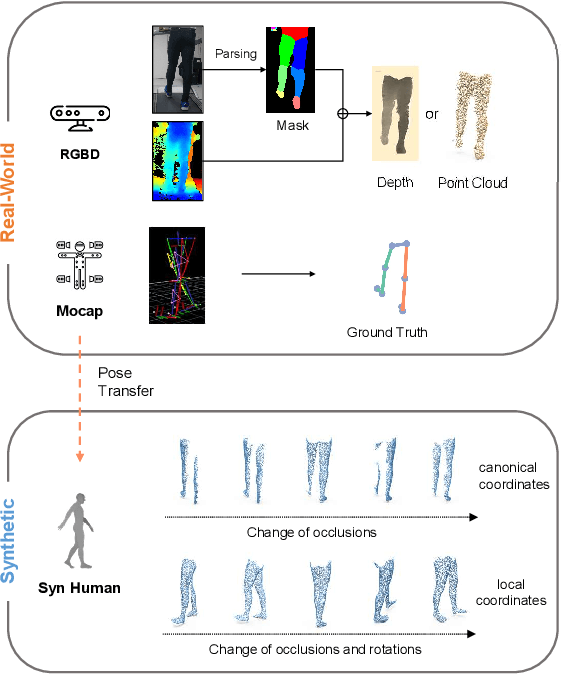
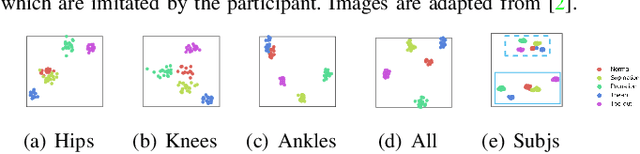
Accurate estimation of three-dimensional human skeletons from depth images can provide important metrics for healthcare applications, especially for biomechanical gait analysis. However, there exist inherent problems associated with depth images captured from a single view. The collected data is greatly affected by occlusions where only partial surface data can be recorded. Furthermore, depth images of human body exhibit heterogeneous characteristics with viewpoint changes, and the estimated poses under local coordinate systems are expected to go through equivariant rotations. Most existing pose estimation models are sensitive to both issues. To address this, we propose a novel approach for cross-view generalization with an occlusion-invariant semi-supervised learning framework built upon a novel rotation-equivariant backbone. Our model was trained with real-world data from a single view and unlabelled synthetic data from multiple views. It can generalize well on the real-world data from all the other unseen views. Our approach has shown superior performance on gait analysis on our ICL-Gait dataset compared to other state-of-the-arts and it can produce more convincing keypoints on ITOP dataset, than its provided "ground truth".