 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVEN: An Event-Based Framework for Monocular Depth Estimation at Adverse Night Conditions
Feb 08, 2023



Accurate depth estimation under adverse night conditions has practical impact and applications, such as on autonomous driving and rescue robots. In this work, we studied monocular depth estimation at night time in which various adverse weather, light, and different road conditions exist, with data captured in both RGB and event modalities. Event camera can better capture intensity changes by virtue of its high dynamic range (HDR), which is particularly suitable to be applied at adverse night conditions in which the amount of light is limited in the scene. Although event data can retain visual perception that conventional RGB camera may fail to capture, the lack of texture and color information of event data hinders its applicability to accurately estimate depth alone. To tackle this problem, we propose an event-vision based framework that integrates low-light enhancement for the RGB source, and exploits the complementary merits of RGB and event data. A dataset that includes paired RGB and event streams, and ground truth depth maps has been constructed. Comprehensive experiments have been conducted, and the impact of different adverse weather combinations on the performance of framework has also been investigated. The results have shown that our proposed framework can better estimate monocular depth at adverse nights than six baselines.
MenuAI: Restaurant Food Recommendation System via a Transformer-based Deep Learning Model
Oct 15, 2022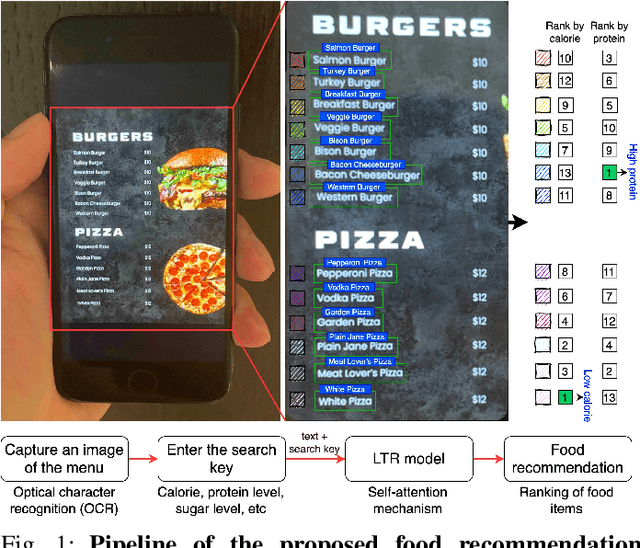
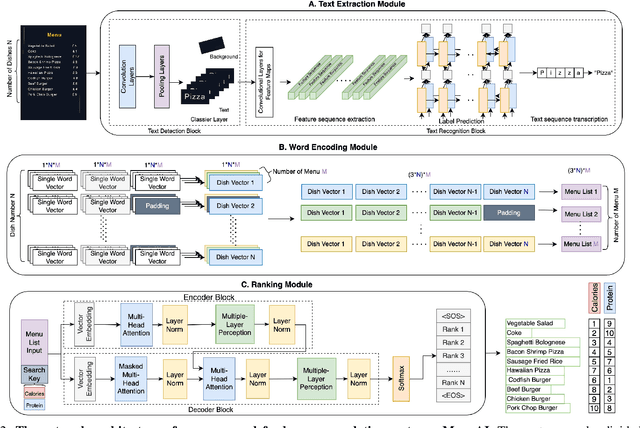
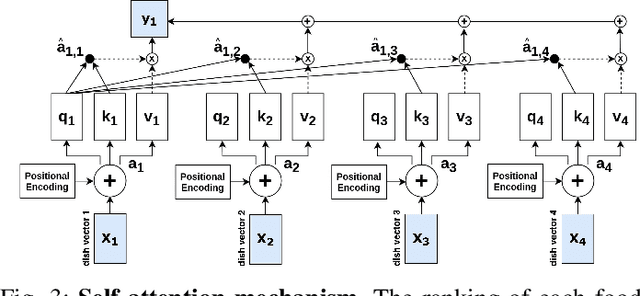
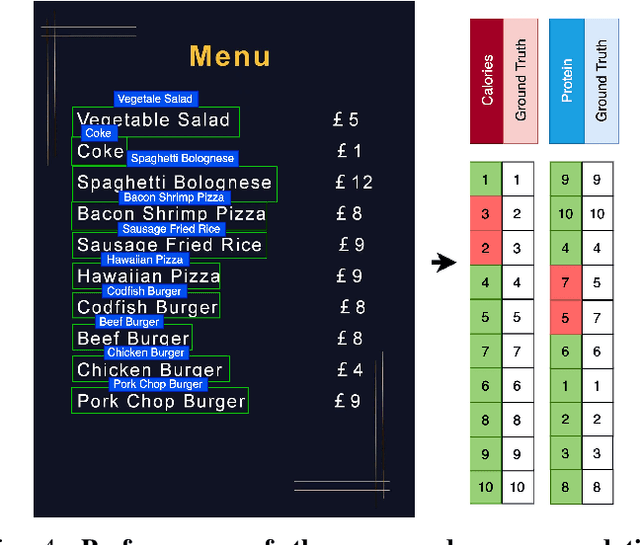
Food recommendation system has proven as an effective technology to provide guidance on dietary choices, and this is especially important for patients suffering from chronic diseases. Unlike other multimedia recommendations, such as books and movies, food recommendation task is highly relied on the context at the moment, since users' food preference can be highly dynamic over time. For example, individuals tend to eat more calories earlier in the day and eat a little less at dinner. However, there are still limited research works trying to incorporate both current context and nutritional knowledge for food recommendation. Thus, a novel restaurant food recommendation system is proposed in this paper to recommend food dishes to users according to their special nutritional needs. Our proposed system utilises Optical Character Recognition (OCR) technology and a transformer-based deep learning model, Learning to Rank (LTR) model, to conduct food recommendation. Given a single RGB image of the menu, the system is then able to rank the food dishes in terms of the input search key (e.g., calorie, protein level). Due to the property of the transformer, our system can also rank unseen food dishes. Comprehensive experiments are conducted to validate our methods on a self-constructed menu dataset, known as MenuRank dataset. The promising results, with accuracy ranging from 77.2% to 99.5%, have demonstrated the great potential of LTR model in addressing food recommendation problems.
Occlusion-Invariant Rotation-Equivariant Semi-Supervised Depth Based Cross-View Gait Pose Estimation
Sep 03, 2021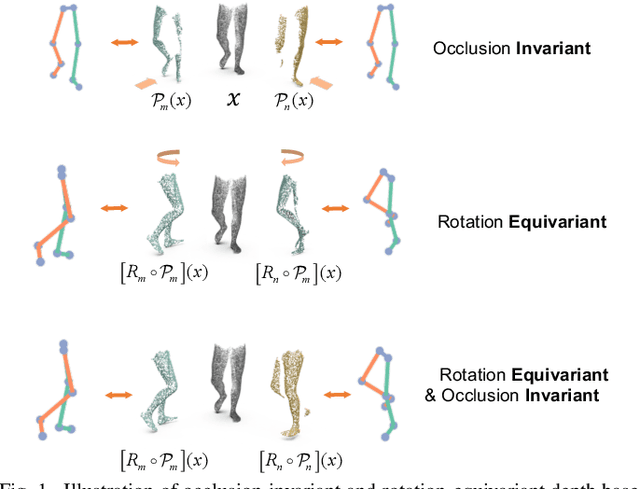
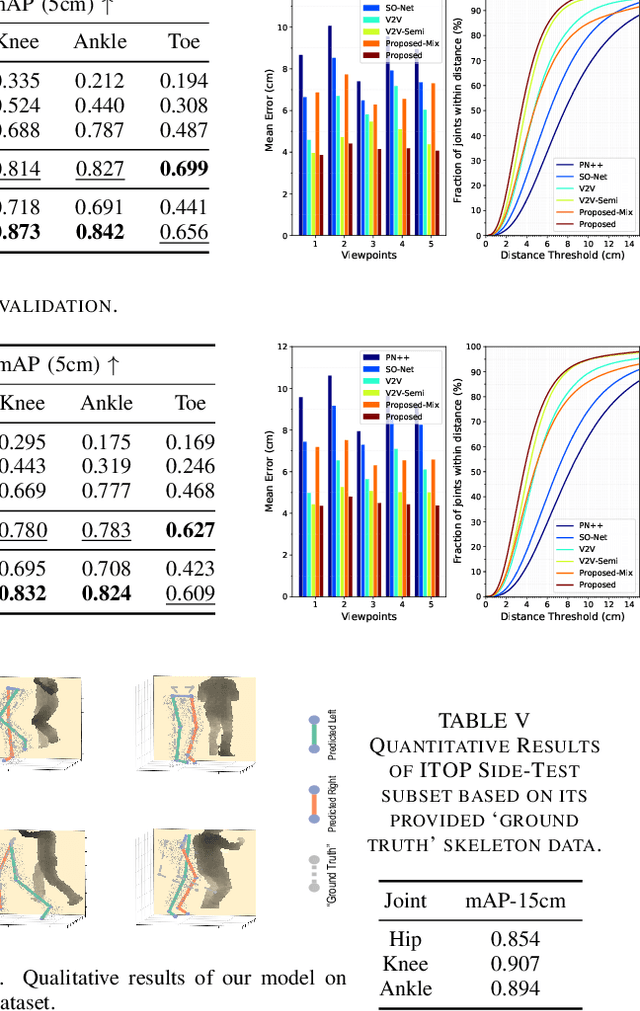
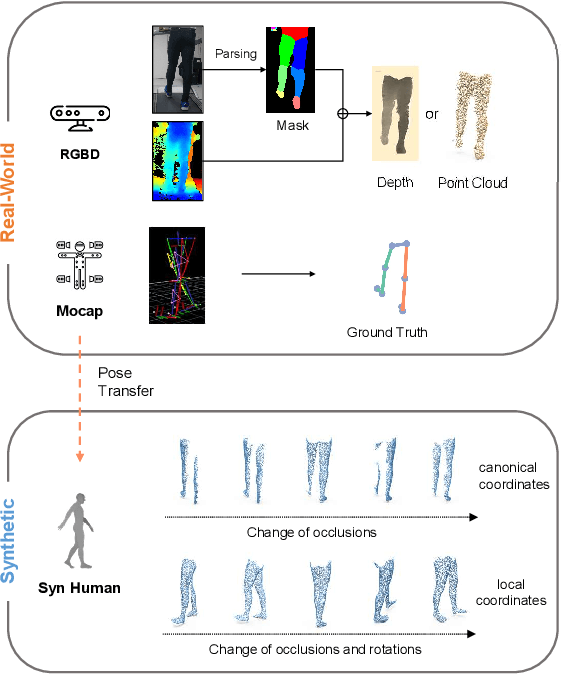
Accurate estimation of three-dimensional human skeletons from depth images can provide important metrics for healthcare applications, especially for biomechanical gait analysis. However, there exist inherent problems associated with depth images captured from a single view. The collected data is greatly affected by occlusions where only partial surface data can be recorded. Furthermore, depth images of human body exhibit heterogeneous characteristics with viewpoint changes, and the estimated poses under local coordinate systems are expected to go through equivariant rotations. Most existing pose estimation models are sensitive to both issues. To address this, we propose a novel approach for cross-view generalization with an occlusion-invariant semi-supervised learning framework built upon a novel rotation-equivariant backbone. Our model was trained with real-world data from a single view and unlabelled synthetic data from multiple views. It can generalize well on the real-world data from all the other unseen views. Our approach has shown superior performance on gait analysis on our ICL-Gait dataset compared to other state-of-the-arts and it can produce more convincing keypoints on ITOP dataset, than its provided "ground truth".
An Intelligent Passive Food Intake Assessment System with Egocentric Cameras
May 07, 2021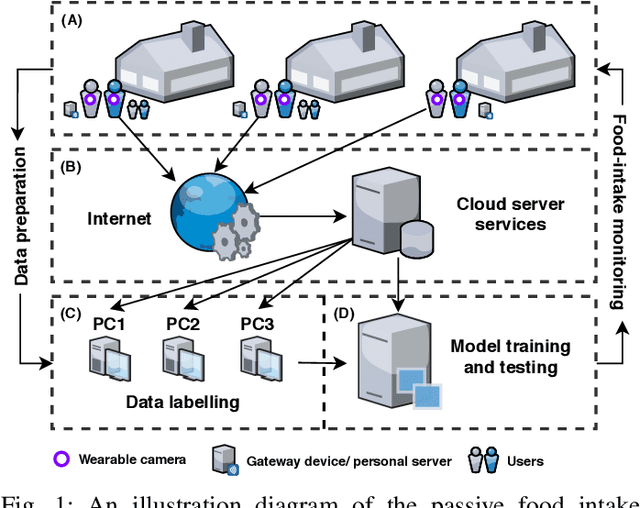
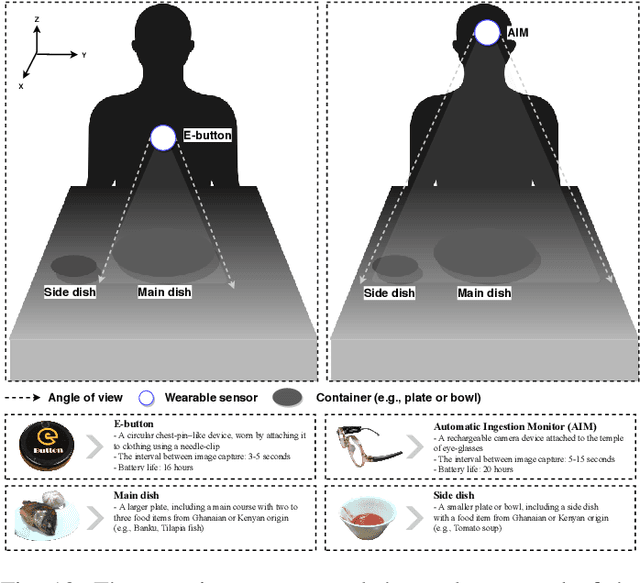

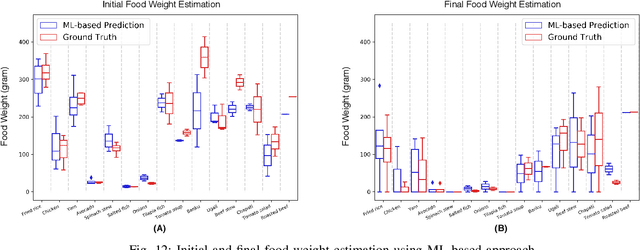
Malnutrition is a major public health concern in low-and-middle-income countries (LMICs). Understanding food and nutrient intake across communities, households and individuals is critical to the development of health policies and interventions. To ease the procedure in conducting large-scale dietary assessments, we propose to implement an intelligent passive food intake assessment system via egocentric cameras particular for households in Ghana and Uganda. Algorithms are first designed to remove redundant images for minimising the storage memory. At run time, deep learning-based semantic segmentation is applied to recognise multi-food types and newly-designed handcrafted features are extracted for further consumed food weight monitoring. Comprehensive experiments are conducted to validate our methods on an in-the-wild dataset captured under the settings which simulate the unique LMIC conditions with participants of Ghanaian and Kenyan origin eating common Ghanaian/Kenyan dishes. To demonstrate the efficacy, experienced dietitians are involved in this research to perform the visual portion size estimation, and their predictions are compared to our proposed method. The promising results have shown that our method is able to reliably monitor food intake and give feedback on users' eating behaviour which provides guidance for dietitians in regular dietary assessment.