 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermining the utility of ultrafast nonlinear contrast enhanced and super resolution ultrasound for imaging microcirculation in the human small intestine
May 16, 2025The regulation of intestinal blood flow is critical to gastrointestinal function. Imaging the intestinal mucosal micro-circulation in vivo has the potential to provide new insight into the gut physiology and pathophysiology. We aimed to determine whether ultrafast contrast enhanced ultrasound (CEUS) and super-resolution ultrasound localisation microscopy (SRUS/ULM) could be a useful tool for imaging the small intestine microcirculation in vivo non-invasively and for detecting changes in blood flow in the duodenum. Ultrafast CEUS and SRUS/ULM were used to image the small intestinal microcirculation in a cohort of 20 healthy volunteers (BMI<25). Participants were imaged while conscious and either having been fasted, or following ingestion of a liquid meal or water control, or under acute stress. For the first time we have performed ultrafast CEUS and ULM on the human small intestine, providing unprecedented resolution images of the intestinal microcirculation. We evaluated flow speed inside small vessels in healthy volunteers (2.78 +/- 0.05 mm/s, mean +/- SEM) and quantified changes in the perfusion of this microcirculation in response to nutrient ingestion. Perfusion of the microvasculature of the intestinal mucosa significantly increased post-prandially (36.2% +/- 12.2%, mean +/- SEM, p<0.05). The feasibility of 3D SRUS/ULM was also demonstrated. This study demonstrates the potential utility of ultrafast CEUS for assessing perfusion and detecting changes in blood flow in the duodenum. SRUS/ULM also proved a useful tool to image the microvascular blood flow in vivo non-invasively and to evaluate blood speed inside the microvasculature of the human small intestine.
Enhancing super-resolution ultrasound localisation through multi-frame deconvolution exploiting spatiotemporal coherence
Jul 08, 2024Super-resolution ultrasound imaging through microbubble (MB) localisation and tracking, also known as ultrasound localisation microscopy, allows non-invasive sub-diffraction resolution imaging of microvasculature in animals and humans. The number of MBs localised from the acquired contrast-enhanced ultrasound (CEUS) images and the localisation precision directly influence the quality of the resulting super-resolution microvasculature images. However, non-negligible noise present in the CEUS images can make localising MBs challenging. To enhance the MB localisation performance, we propose a Multi-Frame Deconvolution (MF-Decon) framework that can exploit the spatiotemporal coherence inherent in the CEUS data, with new spatial and temporal regularisers designed based on total variation (TV) and regularisation by denoising (RED). Based on the MF-Decon framework, we introduce two novel methods: MF-Decon with spatial and temporal TVs (MF-Decon+3DTV) and MF-Decon with spatial RED and temporal TV (MF-Decon+RED+TV). Results from in silico simulations indicate that our methods outperform two widely used methods using deconvolution or normalised cross-correlation across all evaluation metrics, including precision, recall, $F_1$ score, mean and standard localisation errors. In particular, our methods improve MB localisation precision by up to 39% and recall by up to 12%. Super-resolution microvasculature maps generated with our methods on a publicly available in vivo rat brain dataset show less noise, better contrast, higher resolution and more vessel structures.
Dietary Assessment with Multimodal ChatGPT: A Systematic Analysis
Dec 14, 2023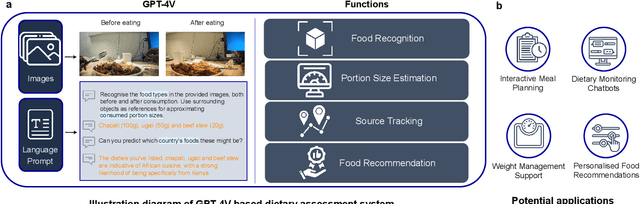

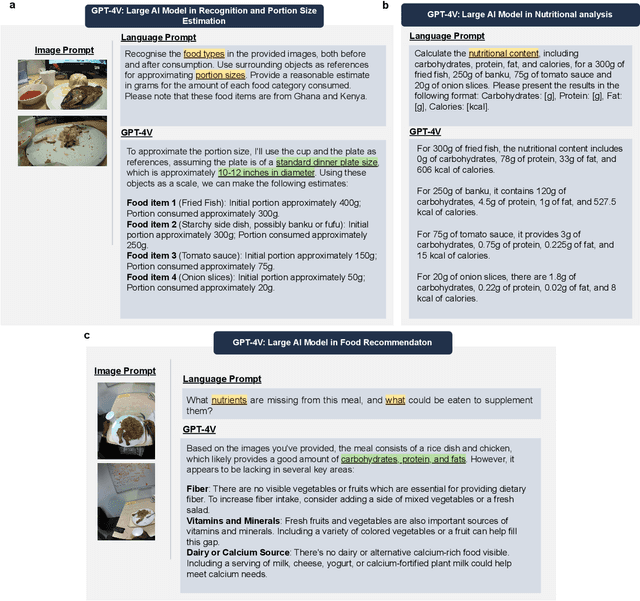

Conventional approaches to dietary assessment are primarily grounded in self-reporting methods or structured interviews conducted under the supervision of dietitians. These methods, however, are often subjective, potentially inaccurate, and time-intensive. Although artificial intelligence (AI)-based solutions have been devised to automate the dietary assessment process, these prior AI methodologies encounter challenges in their ability to generalize across a diverse range of food types, dietary behaviors, and cultural contexts. This results in AI applications in the dietary field that possess a narrow specialization and limited accuracy. Recently, the emergence of multimodal foundation models such as GPT-4V powering the latest ChatGPT has exhibited transformative potential across a wide range of tasks (e.g., Scene understanding and image captioning) in numerous research domains. These models have demonstrated remarkable generalist intelligence and accuracy, capable of processing various data modalities. In this study, we explore the application of multimodal ChatGPT within the realm of dietary assessment. Our findings reveal that GPT-4V excels in food detection under challenging conditions with accuracy up to 87.5% without any fine-tuning or adaptation using food-specific datasets. By guiding the model with specific language prompts (e.g., African cuisine), it shifts from recognizing common staples like rice and bread to accurately identifying regional dishes like banku and ugali. Another GPT-4V's standout feature is its contextual awareness. GPT-4V can leverage surrounding objects as scale references to deduce the portion sizes of food items, further enhancing its accuracy in translating food weight into nutritional content. This alignment with the USDA National Nutrient Database underscores GPT-4V's potential to advance nutritional science and dietary assessment techniques.
Clustering Egocentric Images in Passive Dietary Monitoring with Self-Supervised Learning
Aug 25, 2022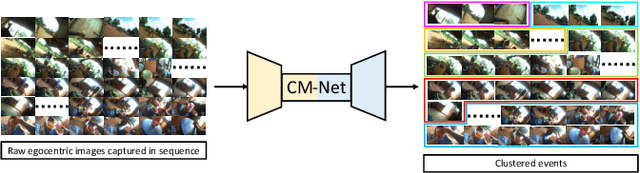
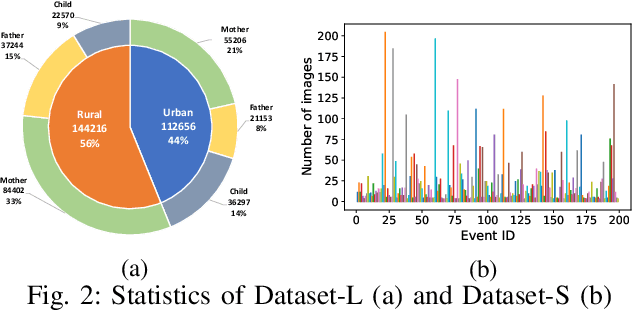
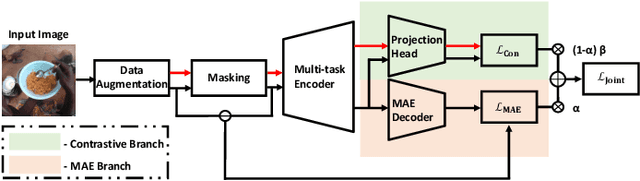
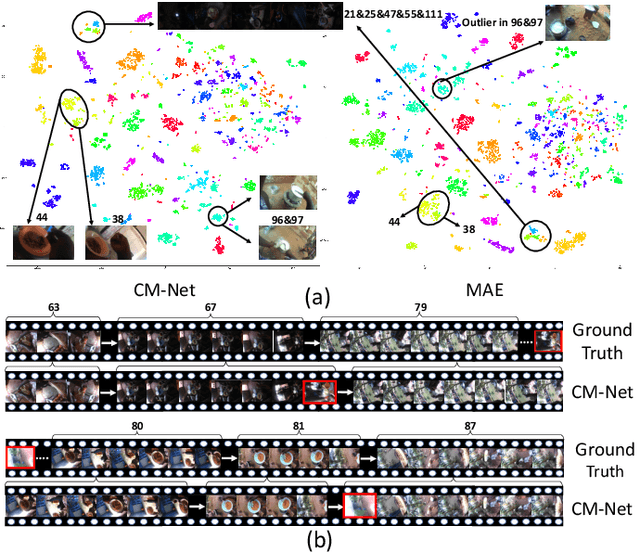
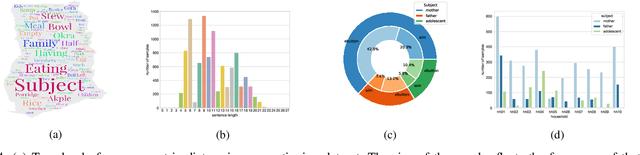
In our recent dietary assessment field studies on passive dietary monitoring in Ghana, we have collected over 250k in-the-wild images. The dataset is an ongoing effort to facilitate accurate measurement of individual food and nutrient intake in low and middle income countries with passive monitoring camera technologies. The current dataset involves 20 households (74 subjects) from both the rural and urban regions of Ghana, and two different types of wearable cameras were used in the studies. Once initiated, wearable cameras continuously capture subjects' activities, which yield massive amounts of data to be cleaned and annotated before analysis is conducted. To ease the data post-processing and annotation tasks, we propose a novel self-supervised learning framework to cluster the large volume of egocentric images into separate events. Each event consists of a sequence of temporally continuous and contextually similar images. By clustering images into separate events, annotators and dietitians can examine and analyze the data more efficiently and facilitate the subsequent dietary assessment processes. Validated on a held-out test set with ground truth labels, the proposed framework outperforms baselines in terms of clustering quality and classification accuracy.
Egocentric Image Captioning for Privacy-Preserved Passive Dietary Intake Monitoring
Jul 01, 2021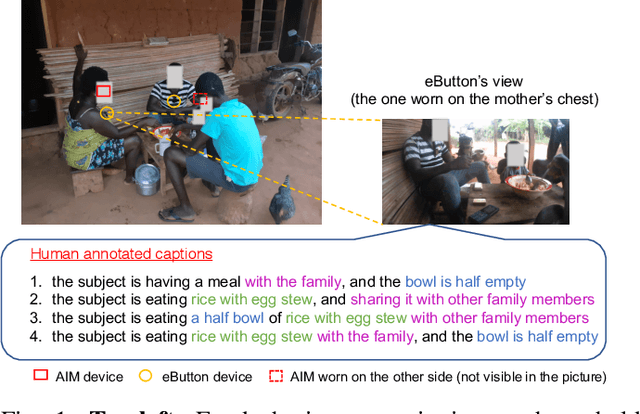
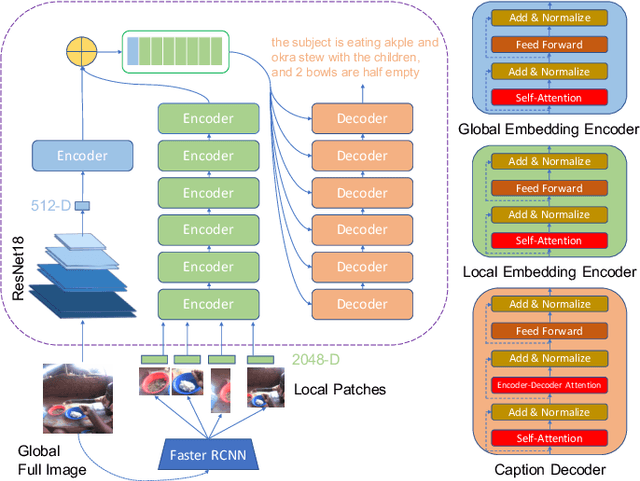
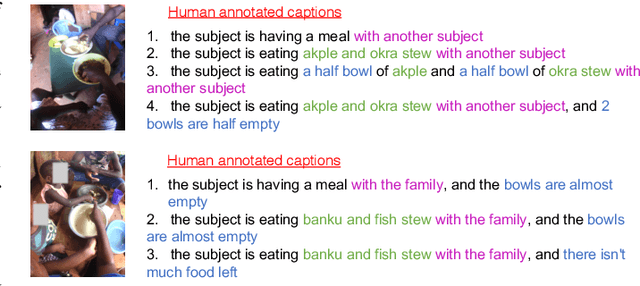
Camera-based passive dietary intake monitoring is able to continuously capture the eating episodes of a subject, recording rich visual information, such as the type and volume of food being consumed, as well as the eating behaviours of the subject. However, there currently is no method that is able to incorporate these visual clues and provide a comprehensive context of dietary intake from passive recording (e.g., is the subject sharing food with others, what food the subject is eating, and how much food is left in the bowl). On the other hand, privacy is a major concern while egocentric wearable cameras are used for capturing. In this paper, we propose a privacy-preserved secure solution (i.e., egocentric image captioning) for dietary assessment with passive monitoring, which unifies food recognition, volume estimation, and scene understanding. By converting images into rich text descriptions, nutritionists can assess individual dietary intake based on the captions instead of the original images, reducing the risk of privacy leakage from images. To this end, an egocentric dietary image captioning dataset has been built, which consists of in-the-wild images captured by head-worn and chest-worn cameras in field studies in Ghana. A novel transformer-based architecture is designed to caption egocentric dietary images. Comprehensive experiments have been conducted to evaluate the effectiveness and to justify the design of the proposed architecture for egocentric dietary image captioning. To the best of our knowledge, this is the first work that applies image captioning to dietary intake assessment in real life settings.
An Intelligent Passive Food Intake Assessment System with Egocentric Cameras
May 07, 2021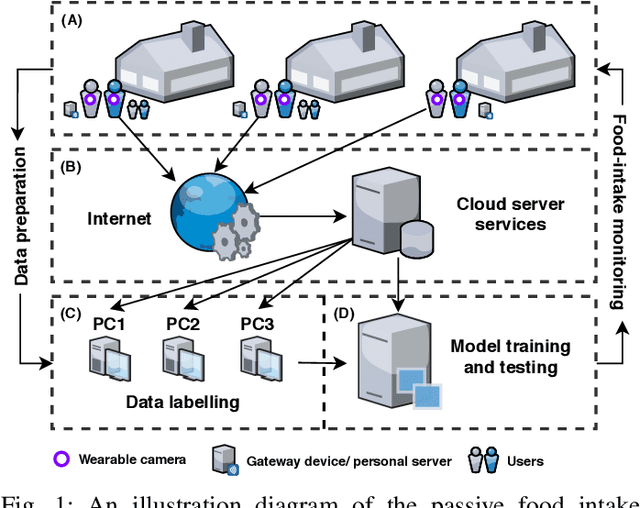
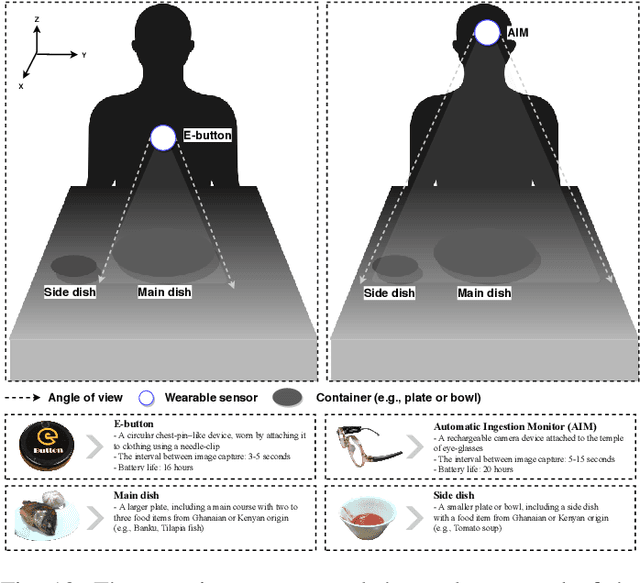

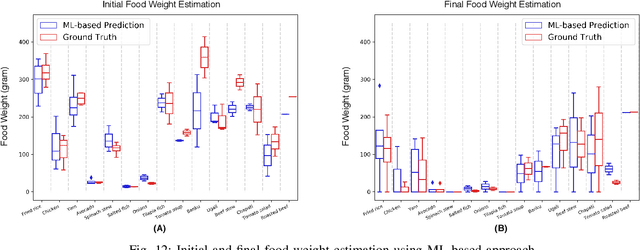
Malnutrition is a major public health concern in low-and-middle-income countries (LMICs). Understanding food and nutrient intake across communities, households and individuals is critical to the development of health policies and interventions. To ease the procedure in conducting large-scale dietary assessments, we propose to implement an intelligent passive food intake assessment system via egocentric cameras particular for households in Ghana and Uganda. Algorithms are first designed to remove redundant images for minimising the storage memory. At run time, deep learning-based semantic segmentation is applied to recognise multi-food types and newly-designed handcrafted features are extracted for further consumed food weight monitoring. Comprehensive experiments are conducted to validate our methods on an in-the-wild dataset captured under the settings which simulate the unique LMIC conditions with participants of Ghanaian and Kenyan origin eating common Ghanaian/Kenyan dishes. To demonstrate the efficacy, experienced dietitians are involved in this research to perform the visual portion size estimation, and their predictions are compared to our proposed method. The promising results have shown that our method is able to reliably monitor food intake and give feedback on users' eating behaviour which provides guidance for dietitians in regular dietary assessment.