 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARE: Towards Bias-Aware and Reasoning-Enhanced One-Tower Visual Grounding
Jan 04, 2026Visual Grounding (VG), which aims to locate a specific region referred to by expressions, is a fundamental yet challenging task in the multimodal understanding fields. While recent grounding transfer works have advanced the field through one-tower architectures, they still suffer from two primary limitations: (1) over-entangled multimodal representations that exacerbate deceptive modality biases, and (2) insufficient semantic reasoning that hinders the comprehension of referential cues. In this paper, we propose BARE, a bias-aware and reasoning-enhanced framework for one-tower visual grounding. BARE introduces a mechanism that preserves modality-specific features and constructs referential semantics through three novel modules: (i) language salience modulator, (ii) visual bias correction and (iii) referential relationship enhancement, which jointly mitigate multimodal distractions and enhance referential comprehension. Extensive experimental results on five benchmarks demonstrate that BARE not only achieves state-of-the-art performance but also delivers superior computational efficiency compared to existing approaches. The code is publicly accessible at https://github.com/Marloweeee/BARE.
Adaptive Dual-Weighted Gravitational Point Cloud Denoising Method
Dec 11, 2025High-quality point cloud data is a critical foundation for tasks such as autonomous driving and 3D reconstruction. However, LiDAR-based point cloud acquisition is often affected by various disturbances, resulting in a large number of noise points that degrade the accuracy of subsequent point cloud object detection and recognition. Moreover, existing point cloud denoising methods typically sacrifice computational efficiency in pursuit of higher denoising accuracy, or, conversely, improve processing speed at the expense of preserving object boundaries and fine structural details, making it difficult to simultaneously achieve high denoising accuracy, strong edge preservation, and real-time performance. To address these limitations, this paper proposes an adaptive dual-weight gravitational-based point cloud denoising method. First, an octree is employed to perform spatial partitioning of the global point cloud, enabling parallel acceleration. Then, within each leaf node, adaptive voxel-based occupancy statistics and k-nearest neighbor (kNN) density estimation are applied to rapidly remove clearly isolated and low-density noise points, thereby reducing the effective candidate set. Finally, a gravitational scoring function that combines density weights with adaptive distance weights is constructed to finely distinguish noise points from object points. Experiments conducted on the Stanford 3D Scanning Repository, the Canadian Adverse Driving Conditions (CADC) dataset, and in-house FMCW LiDAR point clouds acquired in our laboratory demonstrate that, compared with existing methods, the proposed approach achieves consistent improvements in F1, PSNR, and Chamfer Distance (CD) across various noise conditions while reducing the single-frame processing time, thereby validating its high accuracy, robustness, and real-time performance in multi-noise scenarios.
DenoiseRotator: Enhance Pruning Robustness for LLMs via Importance Concentration
May 29, 2025Pruning is a widely used technique to compress large language models (LLMs) by removing unimportant weights, but it often suffers from significant performance degradation - especially under semi-structured sparsity constraints. Existing pruning methods primarily focus on estimating the importance of individual weights, which limits their ability to preserve critical capabilities of the model. In this work, we propose a new perspective: rather than merely selecting which weights to prune, we first redistribute parameter importance to make the model inherently more amenable to pruning. By minimizing the information entropy of normalized importance scores, our approach concentrates importance onto a smaller subset of weights, thereby enhancing pruning robustness. We instantiate this idea through DenoiseRotator, which applies learnable orthogonal transformations to the model's weight matrices. Our method is model-agnostic and can be seamlessly integrated with existing pruning techniques such as Magnitude, SparseGPT, and Wanda. Evaluated on LLaMA3, Qwen2.5, and Mistral models under 50% unstructured and 2:4 semi-structured sparsity, DenoiseRotator consistently improves perplexity and zero-shot accuracy. For instance, on LLaMA3-70B pruned with SparseGPT at 2:4 semi-structured sparsity, DenoiseRotator reduces the perplexity gap to the dense model by 58%, narrowing the degradation from 8.1 to 3.4 points. Codes are available at https://github.com/Axel-gu/DenoiseRotator.
Multi-Sensor Fusion-Based Mobile Manipulator Remote Control for Intelligent Smart Home Assistance
Apr 17, 2025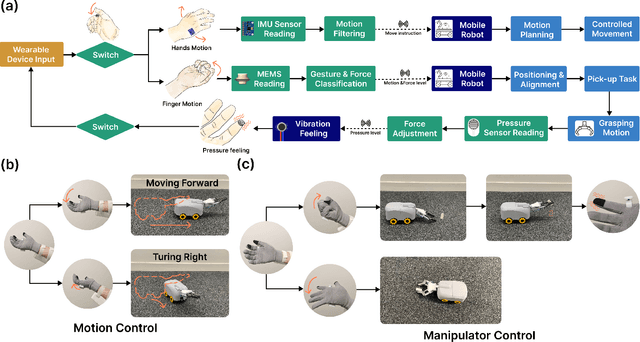
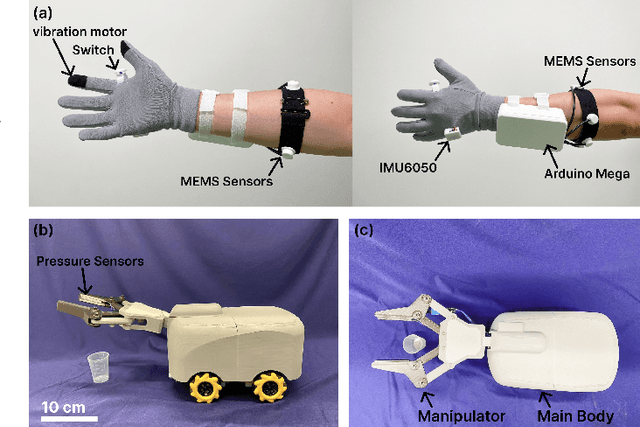
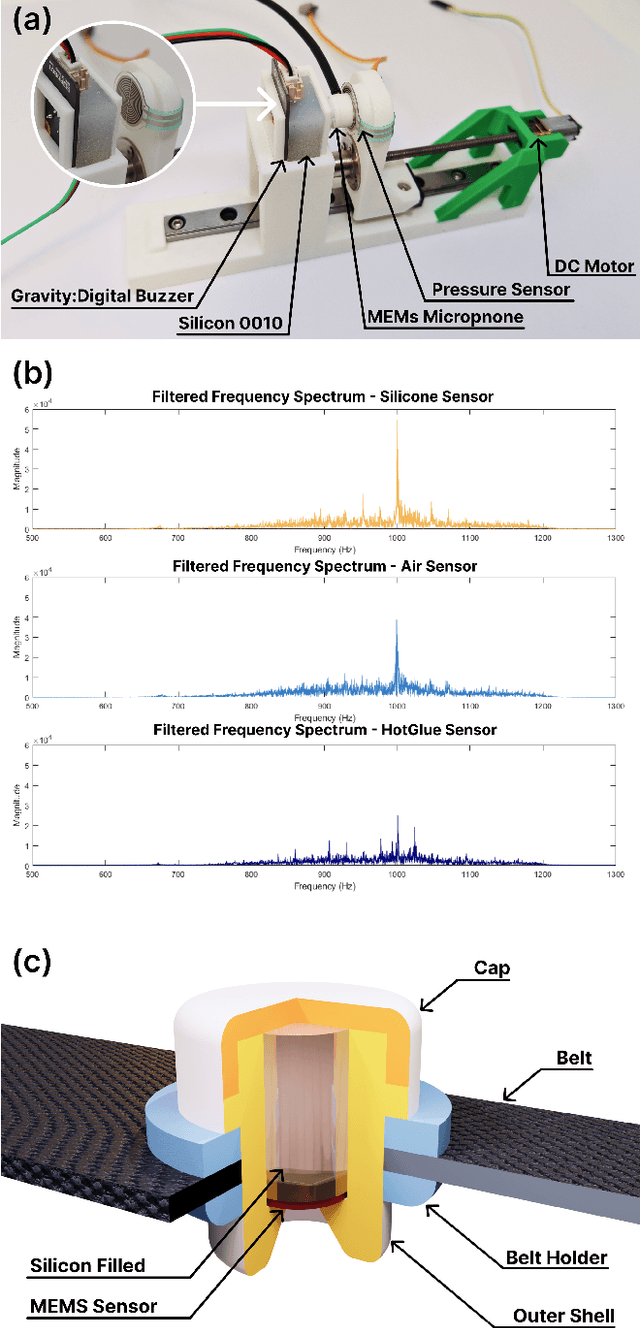
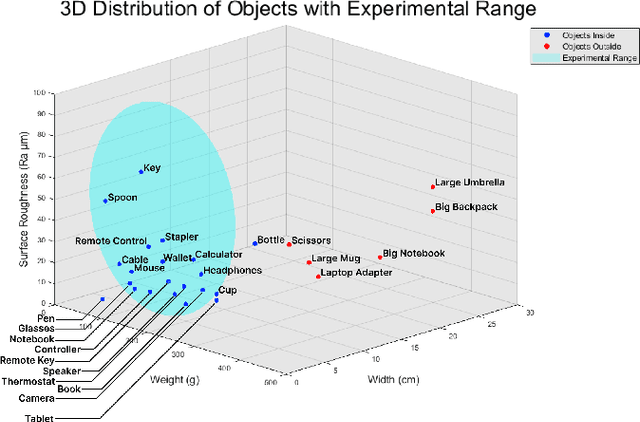
This paper proposes a wearable-controlled mobile manipulator system for intelligent smart home assistance, integrating MEMS capacitive microphones, IMU sensors, vibration motors, and pressure feedback to enhance human-robot interaction. The wearable device captures forearm muscle activity and converts it into real-time control signals for mobile manipulation. The wearable device achieves an offline classification accuracy of 88.33\%\ across six distinct movement-force classes for hand gestures by using a CNN-LSTM model, while real-world experiments involving five participants yield a practical accuracy of 83.33\%\ with an average system response time of 1.2 seconds. In Human-Robot synergy in navigation and grasping tasks, the robot achieved a 98\%\ task success rate with an average trajectory deviation of only 3.6 cm. Finally, the wearable-controlled mobile manipulator system achieved a 93.3\%\ gripping success rate, a transfer success of 95.6\%\, and a full-task success rate of 91.1\%\ during object grasping and transfer tests, in which a total of 9 object-texture combinations were evaluated. These three experiments' results validate the effectiveness of MEMS-based wearable sensing combined with multi-sensor fusion for reliable and intuitive control of assistive robots in smart home scenarios.
PAID: A Framework of Product-Centric Advertising Image Design
Jan 24, 2025In E-commerce platforms, a full advertising image is composed of a background image and marketing taglines. Automatic ad image design reduces human costs and plays a crucial role. For the convenience of users, a novel automatic framework named Product-Centric Advertising Image Design (PAID) is proposed in this work. PAID takes the product foreground image, required taglines, and target size as input and creates an ad image automatically. PAID consists of four sequential stages: prompt generation, layout generation, background image generation, and graphics rendering. Different expert models are trained to conduct these sub-tasks. A visual language model (VLM) based prompt generation model is leveraged to produce a product-matching background prompt. The layout generation model jointly predicts text and image layout according to the background prompt, product, and taglines to achieve the best harmony. An SDXL-based layout-controlled inpainting model is trained to generate an aesthetic background image. Previous ad image design methods take a background image as input and then predict the layout of taglines, which limits the spatial layout due to fixed image content. Innovatively, our PAID adjusts the stages to produce an unrestricted layout. To complete the PAID framework, we created two high-quality datasets, PITA and PIL. Extensive experimental results show that PAID creates more visually pleasing advertising images than previous methods.
MagicDriveDiT: High-Resolution Long Video Generation for Autonomous Driving with Adaptive Control
Nov 21, 2024The rapid advancement of diffusion models has greatly improved video synthesis, especially in controllable video generation, which is essential for applications like autonomous driving. However, existing methods are limited by scalability and how control conditions are integrated, failing to meet the needs for high-resolution and long videos for autonomous driving applications. In this paper, we introduce MagicDriveDiT, a novel approach based on the DiT architecture, and tackle these challenges. Our method enhances scalability through flow matching and employs a progressive training strategy to manage complex scenarios. By incorporating spatial-temporal conditional encoding, MagicDriveDiT achieves precise control over spatial-temporal latents. Comprehensive experiments show its superior performance in generating realistic street scene videos with higher resolution and more frames. MagicDriveDiT significantly improves video generation quality and spatial-temporal controls, expanding its potential applications across various tasks in autonomous driving.
CLAQ: Pushing the Limits of Low-Bit Post-Training Quantization for LLMs
May 27, 2024Parameter quantization for Large Language Models (LLMs) has attracted increasing attentions recently in reducing memory costs and improving computational efficiency. Early approaches have been widely adopted. However, the existing methods suffer from poor performance in low-bit (such as 2 to 3 bits) scenarios. In this paper, we present a novel and effective Column-Level Adaptive weight Quantization (CLAQ) framework by introducing three different types of adaptive strategies for LLM quantization. Firstly, a K-Means clustering based algorithm is proposed that allows dynamic generation of quantization centroids for each column of a parameter matrix. Secondly, we design an outlier-guided adaptive precision search strategy which can dynamically assign varying bit-widths to different columns. Finally, a dynamic outlier reservation scheme is developed to retain some parameters in their original float point precision, in trade off of boosted model performance. Experiments on various mainstream open source LLMs including LLaMA-1, LLaMA-2 and Yi demonstrate that our methods achieve the state-of-the-art results across different bit settings, especially in extremely low-bit scenarios. Code will be released soon.
Dietary Assessment with Multimodal ChatGPT: A Systematic Analysis
Dec 14, 2023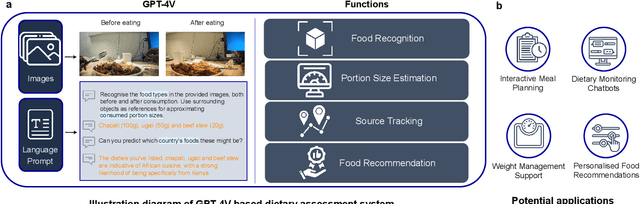

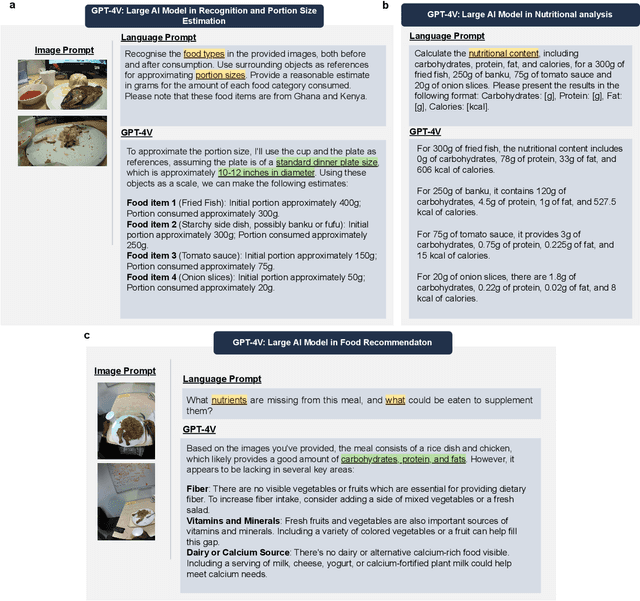

Conventional approaches to dietary assessment are primarily grounded in self-reporting methods or structured interviews conducted under the supervision of dietitians. These methods, however, are often subjective, potentially inaccurate, and time-intensive. Although artificial intelligence (AI)-based solutions have been devised to automate the dietary assessment process, these prior AI methodologies encounter challenges in their ability to generalize across a diverse range of food types, dietary behaviors, and cultural contexts. This results in AI applications in the dietary field that possess a narrow specialization and limited accuracy. Recently, the emergence of multimodal foundation models such as GPT-4V powering the latest ChatGPT has exhibited transformative potential across a wide range of tasks (e.g., Scene understanding and image captioning) in numerous research domains. These models have demonstrated remarkable generalist intelligence and accuracy, capable of processing various data modalities. In this study, we explore the application of multimodal ChatGPT within the realm of dietary assessment. Our findings reveal that GPT-4V excels in food detection under challenging conditions with accuracy up to 87.5% without any fine-tuning or adaptation using food-specific datasets. By guiding the model with specific language prompts (e.g., African cuisine), it shifts from recognizing common staples like rice and bread to accurately identifying regional dishes like banku and ugali. Another GPT-4V's standout feature is its contextual awareness. GPT-4V can leverage surrounding objects as scale references to deduce the portion sizes of food items, further enhancing its accuracy in translating food weight into nutritional content. This alignment with the USDA National Nutrient Database underscores GPT-4V's potential to advance nutritional science and dietary assessment techniques.
Towards Robust and Generalizable Training: An Empirical Study of Noisy Slot Filling for Input Perturbations
Oct 05, 2023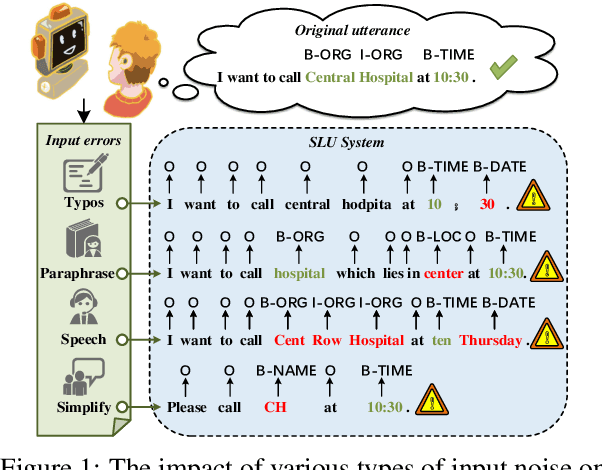

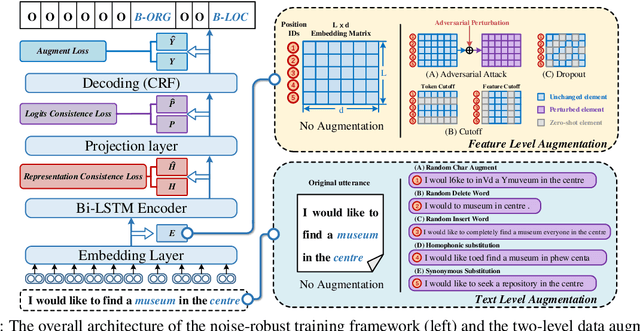
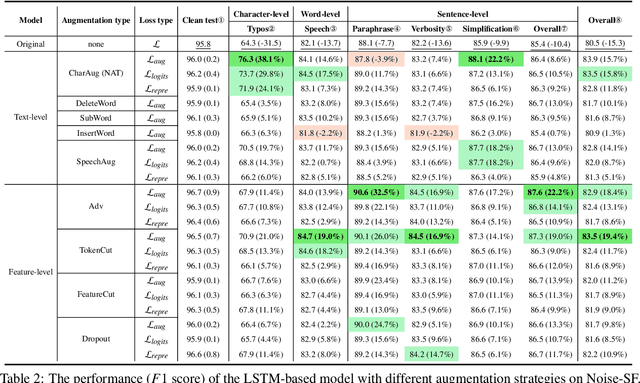
In real dialogue scenarios, as there are unknown input noises in the utterances, existing supervised slot filling models often perform poorly in practical applications. Even though there are some studies on noise-robust models, these works are only evaluated on rule-based synthetic datasets, which is limiting, making it difficult to promote the research of noise-robust methods. In this paper, we introduce a noise robustness evaluation dataset named Noise-SF for slot filling task. The proposed dataset contains five types of human-annotated noise, and all those noises are exactly existed in real extensive robust-training methods of slot filling into the proposed framework. By conducting exhaustive empirical evaluation experiments on Noise-SF, we find that baseline models have poor performance in robustness evaluation, and the proposed framework can effectively improve the robustness of models. Based on the empirical experimental results, we make some forward-looking suggestions to fuel the research in this direction. Our dataset Noise-SF will be released at https://github.com/dongguanting/Noise-SF.
Large AI Models in Health Informatics: Applications, Challenges, and the Future
Mar 21, 2023



Large AI models, or foundation models, are models recently emerging with massive scales both parameter-wise and data-wise, the magnitudes of which often reach beyond billions. Once pretrained, large AI models demonstrate impressive performance in various downstream tasks. A concrete example is the recent debut of ChatGPT, whose capability has compelled people's imagination about the far-reaching influence that large AI models can have and their potential to transform different domains of our life. In health informatics, the advent of large AI models has brought new paradigms for the design of methodologies. The scale of multimodality data in the biomedical and health domain has been ever-expanding especially since the community embraced the era of deep learning, which provides the ground to develop, validate, and advance large AI models for breakthroughs in health-related areas. This article presents an up-to-date comprehensive review of large AI models, from background to their applications. We identify seven key sectors that large AI models are applicable and might have substantial influence, including 1) molecular biology and drug discovery; 2) medical diagnosis and decision-making; 3) medical imaging and vision; 4) medical informatics; 5) medical education; 6) public health; and 7) medical robotics. We examine their challenges in health informatics, followed by a critical discussion about potential future directions and pitfalls of large AI models in transforming the field of health informatics.