 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LLM-enabled Multi-Agent Autonomous Mechatronics Design Framework
Apr 20, 2025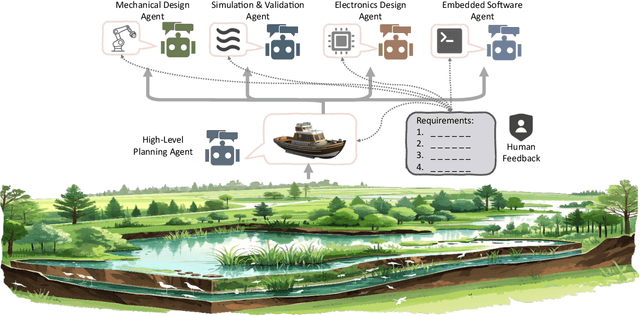

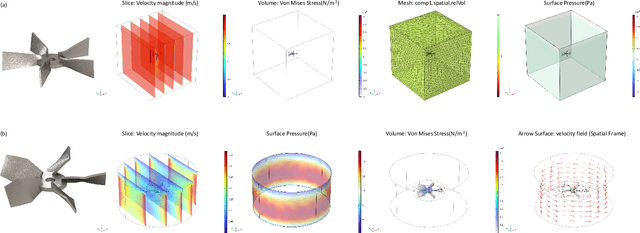
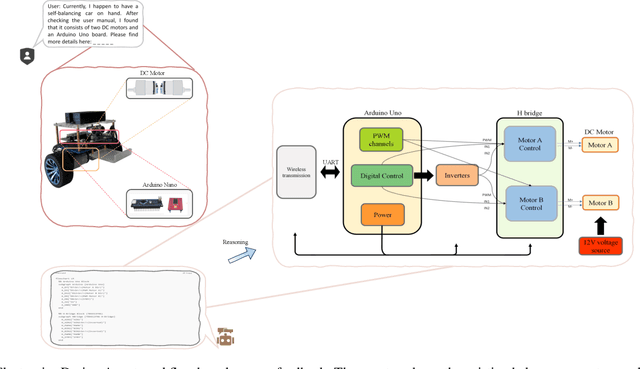
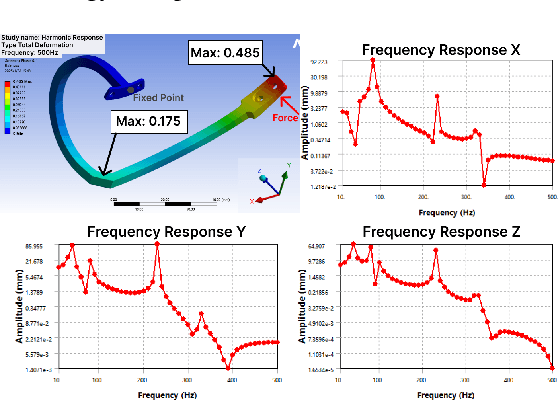
Existing LLM-enabled multi-agent frameworks are predominantly limited to digital or simulated environments and confined to narrowly focused knowledge domain, constraining their applicability to complex engineering tasks that require the design of physical embodiment, cross-disciplinary integration, and constraint-aware reasoning. This work proposes a multi-agent autonomous mechatronics design framework, integrating expertise across mechanical design, optimization, electronics, and software engineering to autonomously generate functional prototypes with minimal direct human design input. Operating primarily through a language-driven workflow, the framework incorporates structured human feedback to ensure robust performance under real-world constraints. To validate its capabilities, the framework is applied to a real-world challenge involving autonomous water-quality monitoring and sampling, where traditional methods are labor-intensive and ecologically disruptive. Leveraging the proposed system, a fully functional autonomous vessel was developed with optimized propulsion, cost-effective electronics, and advanced control. The design process was carried out by specialized agents, including a high-level planning agent responsible for problem abstraction and dedicated agents for structural, electronics, control, and software development. This approach demonstrates the potential of LLM-based multi-agent systems to automate real-world engineering workflows and reduce reliance on extensive domain expertise.
Physical Reservoir Computing in Hook-Shaped Rover Wheel Spokes for Real-Time Terrain Identification
Apr 17, 2025
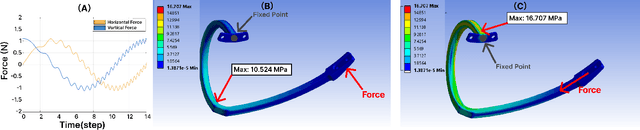
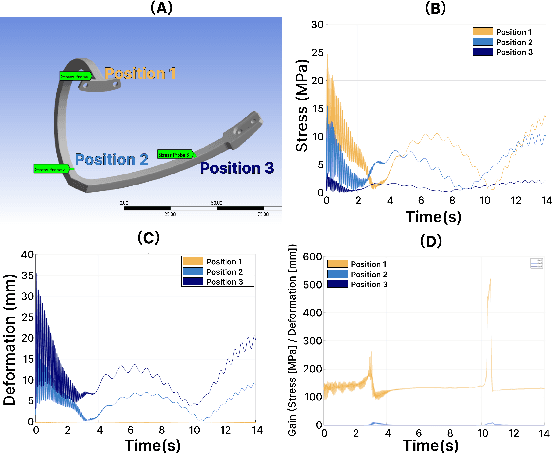
Effective terrain detection in unknown environments is crucial for safe and efficient robotic navigation. Traditional methods often rely on computationally intensive data processing, requiring extensive onboard computational capacity and limiting real-time performance for rovers. This study presents a novel approach that combines physical reservoir computing with piezoelectric sensors embedded in rover wheel spokes for real-time terrain identification. By leveraging wheel dynamics, terrain-induced vibrations are transformed into high-dimensional features for machine learning-based classification. Experimental results show that strategically placing three sensors on the wheel spokes achieves 90$\%$ classification accuracy, which demonstrates the accuracy and feasibility of the proposed method. The experiment results also showed that the system can effectively distinguish known terrains and identify unknown terrains by analyzing their similarity to learned categories. This method provides a robust, low-power framework for real-time terrain classification and roughness estimation in unstructured environments, enhancing rover autonomy and adaptability.
Multi-Sensor Fusion-Based Mobile Manipulator Remote Control for Intelligent Smart Home Assistance
Apr 17, 2025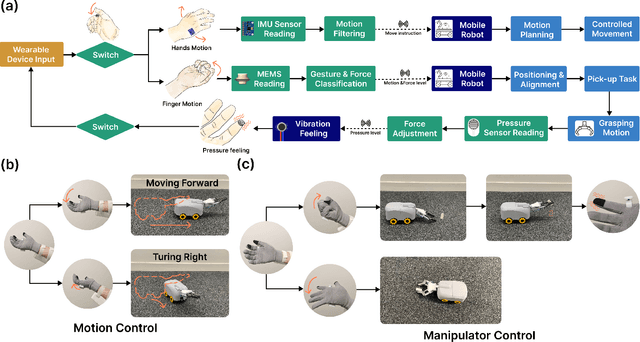
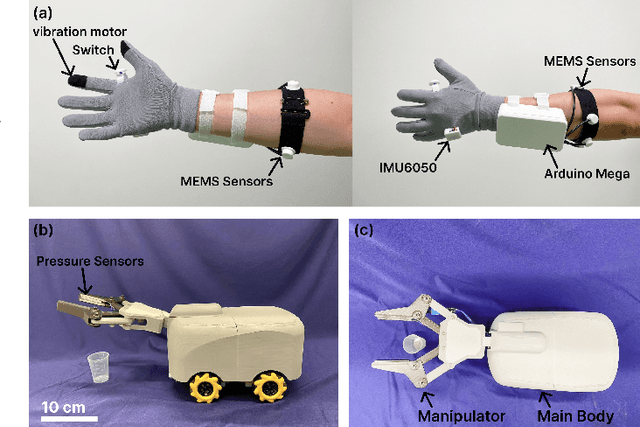
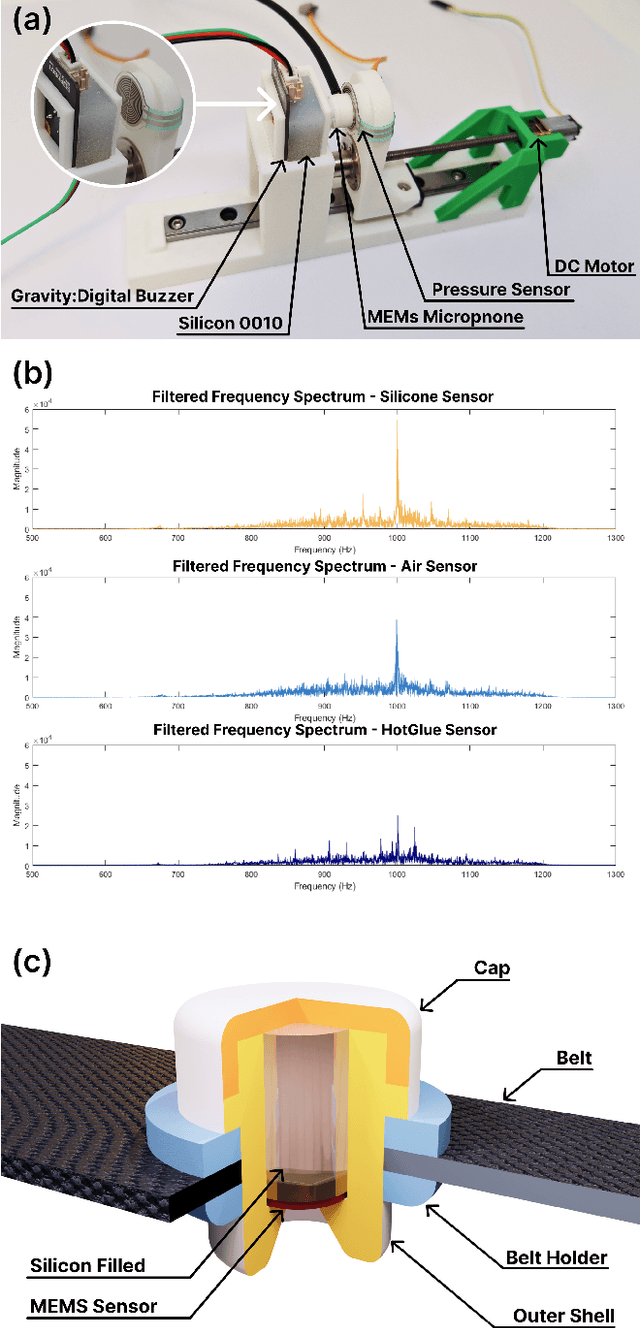
This paper proposes a wearable-controlled mobile manipulator system for intelligent smart home assistance, integrating MEMS capacitive microphones, IMU sensors, vibration motors, and pressure feedback to enhance human-robot interaction. The wearable device captures forearm muscle activity and converts it into real-time control signals for mobile manipulation. The wearable device achieves an offline classification accuracy of 88.33\%\ across six distinct movement-force classes for hand gestures by using a CNN-LSTM model, while real-world experiments involving five participants yield a practical accuracy of 83.33\%\ with an average system response time of 1.2 seconds. In Human-Robot synergy in navigation and grasping tasks, the robot achieved a 98\%\ task success rate with an average trajectory deviation of only 3.6 cm. Finally, the wearable-controlled mobile manipulator system achieved a 93.3\%\ gripping success rate, a transfer success of 95.6\%\, and a full-task success rate of 91.1\%\ during object grasping and transfer tests, in which a total of 9 object-texture combinations were evaluated. These three experiments' results validate the effectiveness of MEMS-based wearable sensing combined with multi-sensor fusion for reliable and intuitive control of assistive robots in smart home scenarios.
PARF-Net: integrating pixel-wise adaptive receptive fields into hybrid Transformer-CNN network for medical image segmentation
Jan 06, 2025



Convolutional neural networks (CNNs) excel in local feature extraction while Transformers are superior in processing global semantic information. By leveraging the strengths of both, hybrid Transformer-CNN networks have become the major architectures in medical image segmentation tasks. However, existing hybrid methods still suffer deficient learning of local semantic features due to the fixed receptive fields of convolutions, and also fall short in effectively integrating local and long-range dependencies. To address these issues, we develop a new method PARF-Net to integrate convolutions of Pixel-wise Adaptive Receptive Fields (Conv-PARF) into hybrid Network for medical image segmentation. The Conv-PARF is introduced to cope with inter-pixel semantic differences and dynamically adjust convolutional receptive fields for each pixel, thus providing distinguishable features to disentangle the lesions with varying shapes and scales from the background. The features derived from the Conv-PARF layers are further processed using hybrid Transformer-CNN blocks under a lightweight manner, to effectively capture local and long-range dependencies, thus boosting the segmentation performance. By assessing PARF-Net on four widely used medical image datasets including MoNuSeg, GlaS, DSB2018 and multi-organ Synapse, we showcase the advantages of our method over the state-of-the-arts. For instance, PARF-Net achieves 84.27% mean Dice on the Synapse dataset, surpassing existing methods by a large margin.
Towards the Neuromorphic Computing for Offroad Robot Environment Perception and Navigation
May 05, 2023
My research objective is to explicitly bridge the gap between high computational performance and low power dissipation of robot on-board hardware by designing a bio-inspired tapered whisker neuromorphic computing (also called reservoir computing) system for offroad robot environment perception and navigation, that centres the interaction between a robot's body and its environment. Mobile robots performing tasks in unknown environments need to traverse a variety of complex terrains, and they must be able to reliably and quickly identify and characterize these terrains to avoid getting into potentially challenging or catastrophic circumstances. To solve this problem, I drew inspiration from animals like rats and seals, just relying on whiskers to perceive surroundings information and survive in dark and narrow environments. Additionally, I looked to the human cochlear which can separate different frequencies of sound. Based on these insights, my work addresses this need by exploring the physical whisker-based reservoir computing for quick and cost-efficient mobile robots environment perception and navigation step by step. This research could help us understand how the compliance of the biological counterparts helps robots to dynamically interact with the environment and provides a new solution compared with current methods for robot environment perception and navigation with limited computational resources, such as Mars.
CAP: instance complexity-aware network pruning
Sep 08, 2022
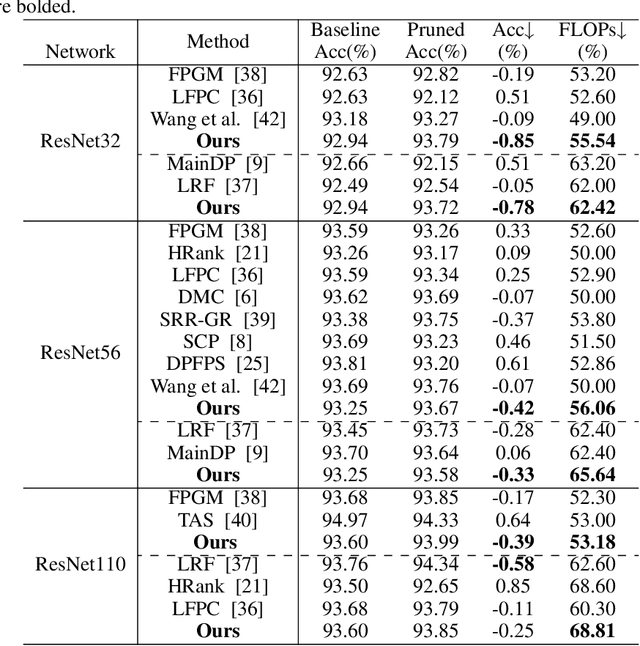
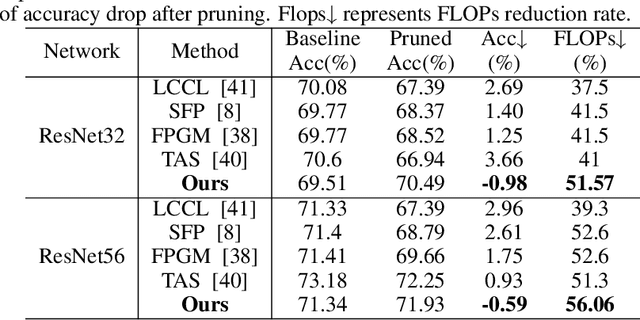
Existing differentiable channel pruning methods often attach scaling factors or masks behind channels to prune filters with less importance, and assume uniform contribution of input samples to filter importance. Specifically, the effects of instance complexity on pruning performance are not yet fully investigated. In this paper, we propose a simple yet effective differentiable network pruning method CAP based on instance complexity-aware filter importance scores. We define instance complexity related weight for each sample by giving higher weights to hard samples, and measure the weighted sum of sample-specific soft masks to model non-uniform contribution of different inputs, which encourages hard samples to dominate the pruning process and the model performance to be well preserved. In addition, we introduce a new regularizer to encourage polarization of the masks, such that a sweet spot can be easily found to identify the filters to be pruned. Performance evaluations on various network architectures and datasets demonstrate CAP has advantages over the state-of-the-arts in pruning large networks. For instance, CAP improves the accuracy of ResNet56 on CIFAR-10 dataset by 0.33% aftering removing 65.64% FLOPs, and prunes 87.75% FLOPs of ResNet50 on ImageNet dataset with only 0.89% Top-1 accuracy loss.
A Method to use Nonlinear Dynamics in a Whisker Sensor for Terrain Identification by Mobile Robots
Aug 04, 2021
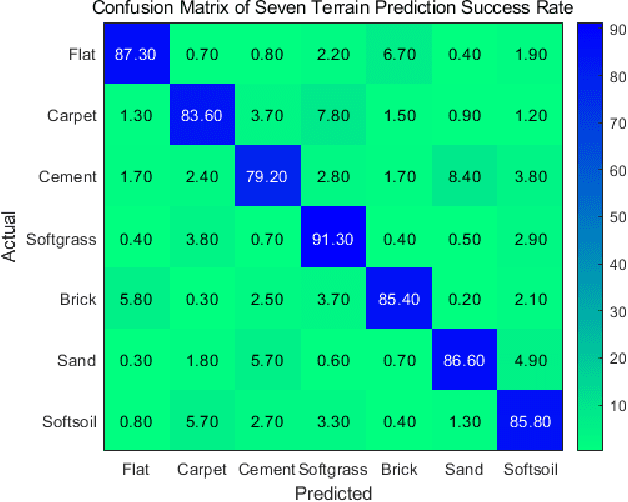
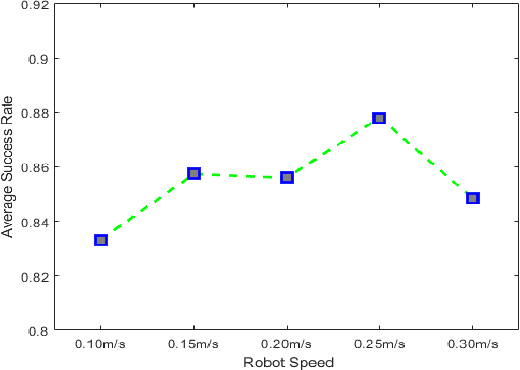
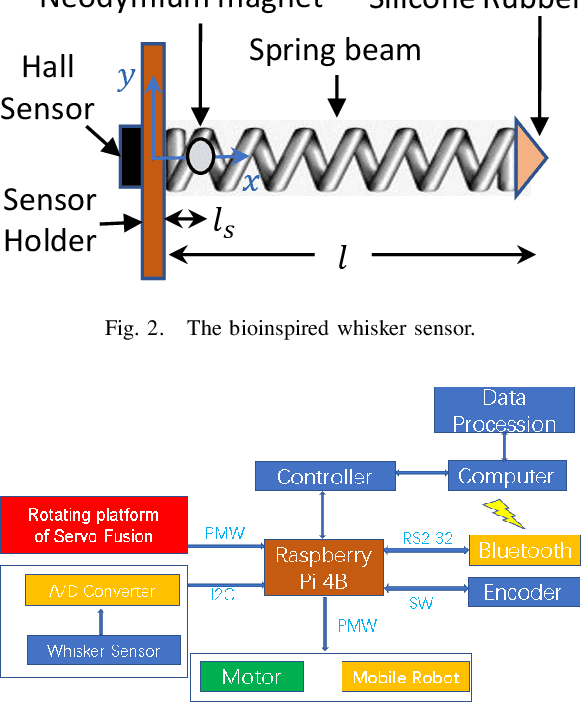
This paper shows analytical and experimental evidence of using the vibration dynamics of a compliant whisker for accurate terrain classification during steady state motion of a mobile robot. A Hall effect sensor was used to measure whisker vibrations due to perturbations from the ground. Analytical results predict that the whisker vibrations will have a dominant frequency at the vertical perturbation frequency of the mobile robot sandwiched by two other less dominant but distinct frequency components. These frequency components may come from bifurcation of vibration frequency due to nonlinear interaction dynamics at steady state. Experimental results also exhibit distinct dominant frequency components unique to the speed of the robot and the terrain roughness. This nonlinear dynamic feature is used in a deep multi-layer perceptron neural network to classify terrains. We achieved 85.6\% prediction success rate for seven flat terrain surfaces with different textures.
Towards Omni-Supervised Face Alignment for Large Scale Unlabeled Videos
Dec 16, 2019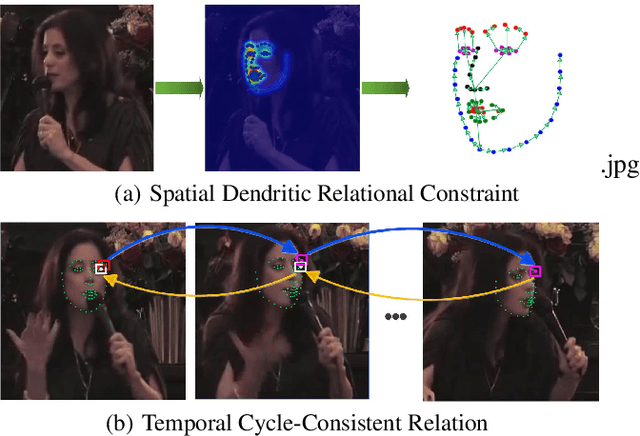
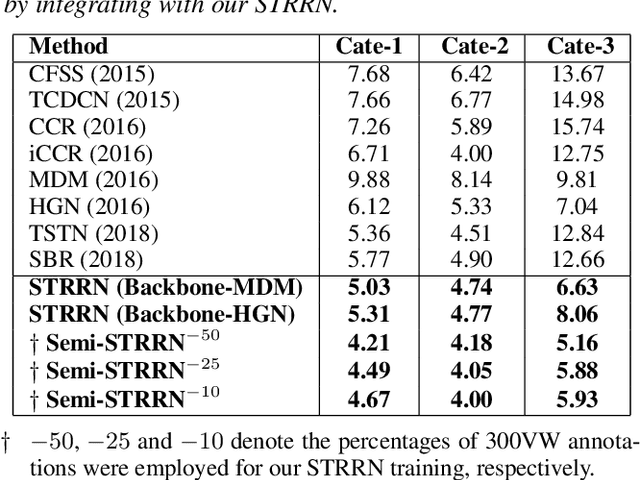
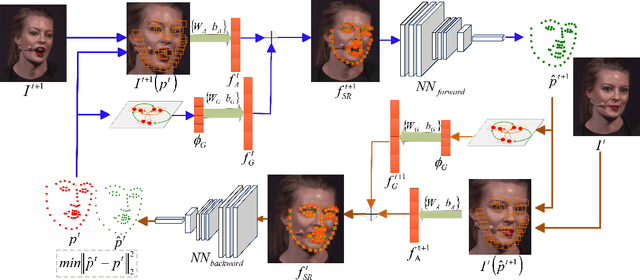
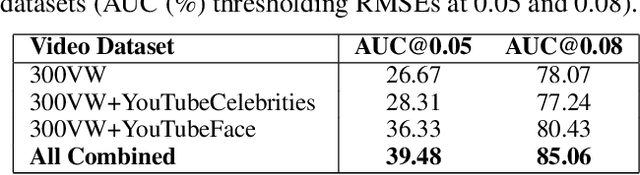
In this paper, we propose a spatial-temporal relational reasoning networks (STRRN) approach to investigate the problem of omni-supervised face alignment in videos. Unlike existing fully supervised methods which rely on numerous annotations by hand, our learner exploits large scale unlabeled videos plus available labeled data to generate auxiliary plausible training annotations. Motivated by the fact that neighbouring facial landmarks are usually correlated and coherent across consecutive frames, our approach automatically reasons about discriminative spatial-temporal relationships among landmarks for stable face tracking. Specifically, we carefully develop an interpretable and efficient network module, which disentangles facial geometry relationship for every static frame and simultaneously enforces the bi-directional cycle-consistency across adjacent frames, thus allowing the modeling of intrinsic spatial-temporal relations from raw face sequences. Extensive experimental results demonstrate that our approach surpasses the performance of most fully supervised state-of-the-arts.