 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Vision-Language Models Get Lost in Attention
May 07, 2026Despite the rapid evolution of training paradigms, the decoder backbone of large vision--language models (LVLMs) remains fundamentally rooted in the residual-connection Transformer architecture. Therefore, deciphering the distinct roles of internal modules is critical for understanding model mechanics and guiding architectural optimization. While prior statistical approaches have provided valuable attribution-based insights, they often lack a unified theoretical basis. To bridge this gap, we propose a unified framework grounded in information theory and geometry to quantify the geometric and entropic nature of residual updates. Applying this unified framework reveals a fundamental functional decoupling: Attention acts as a subspace-preserving operator focused on reconfiguration, whereas FFNs serve as subspace-expanding operators driving semantic innovation. Strikingly, further experiments demonstrate that replacing learned attention weights with predefined values (e.g., Gaussian noise) yields comparable or even superior performance across a majority of datasets relative to vanilla models. These results expose severe misallocation and redundancy in current mechanisms, suggesting that state-of-the-art LVLMs effectively ``get lost in attention'' rather than efficiently leveraging visual context.
ClueTracer: Question-to-Vision Clue Tracing for Training-Free Hallucination Suppression in Multimodal Reasoning
Feb 02, 2026Large multimodal reasoning models solve challenging visual problems via explicit long-chain inference: they gather visual clues from images and decode clues into textual tokens. Yet this capability also increases hallucinations, where the model generates content that is not supported by the input image or the question. To understand this failure mode, we identify \emph{reasoning drift}: during clue gathering, the model over-focuses on question-irrelevant entities, diluting focus on task-relevant cues and gradually decoupling the reasoning trace from visual grounding. As a consequence, many inference-time localization or intervention methods developed for non-reasoning models fail to pinpoint the true clues in reasoning settings. Motivated by these insights, we introduce ClueRecall, a metric for assessing visual clue retrieval, and present ClueTracer, a training-free, parameter-free, and architecture-agnostic plugin for hallucination suppression. ClueTracer starts from the question and traces how key clues propagate along the model's reasoning pathway (question $\rightarrow$ outputs $\rightarrow$ visual tokens), thereby localizing task-relevant patches while suppressing spurious attention to irrelevant regions. Remarkably, \textbf{without any additional training}, ClueTracer improves all \textbf{reasoning} architectures (including \texttt{R1-OneVision}, \texttt{Ocean-R1}, \texttt{MM-Eureka}, \emph{etc}.) by $\mathbf{1.21\times}$ on reasoning benchmarks. When transferred to \textbf{non-reasoning} settings, it yields a $\mathbf{1.14\times}$ gain.
CoPHo: Classifier-guided Conditional Topology Generation with Persistent Homology
Dec 17, 2025The structure of topology underpins much of the research on performance and robustness, yet available topology data are typically scarce, necessitating the generation of synthetic graphs with desired properties for testing or release. Prior diffusion-based approaches either embed conditions into the diffusion model, requiring retraining for each attribute and hindering real-time applicability, or use classifier-based guidance post-training, which does not account for topology scale and practical constraints. In this paper, we show from a discrete perspective that gradients from a pre-trained graph-level classifier can be incorporated into the discrete reverse diffusion posterior to steer generation toward specified structural properties. Based on this insight, we propose Classifier-guided Conditional Topology Generation with Persistent Homology (CoPHo), which builds a persistent homology filtration over intermediate graphs and interprets features as guidance signals that steer generation toward the desired properties at each denoising step. Experiments on four generic/network datasets demonstrate that CoPHo outperforms existing methods at matching target metrics, and we further validate its transferability on the QM9 molecular dataset.
SAC-MIL: Spatial-Aware Correlated Multiple Instance Learning for Histopathology Whole Slide Image Classification
Sep 04, 2025



We propose Spatial-Aware Correlated Multiple Instance Learning (SAC-MIL) for performing WSI classification. SAC-MIL consists of a positional encoding module to encode position information and a SAC block to perform full instance correlations. The positional encoding module utilizes the instance coordinates within the slide to encode the spatial relationships instead of the instance index in the input WSI sequence. The positional encoding module can also handle the length extrapolation issue where the training and testing sequences have different lengths. The SAC block is an MLP-based method that performs full instance correlation in linear time complexity with respect to the sequence length. Due to the simple structure of MLP, it is easy to deploy since it does not require custom CUDA kernels, compared to Transformer-based methods for WSI classification. SAC-MIL has achieved state-of-the-art performance on the CAMELYON-16, TCGA-LUNG, and TCGA-BRAC datasets. The code will be released upon acceptance.
Multi-Sensor Fusion-Based Mobile Manipulator Remote Control for Intelligent Smart Home Assistance
Apr 17, 2025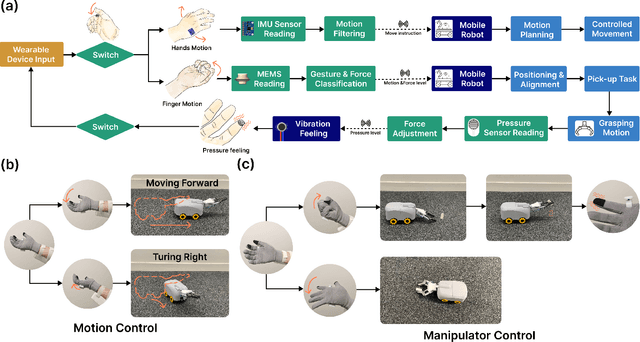
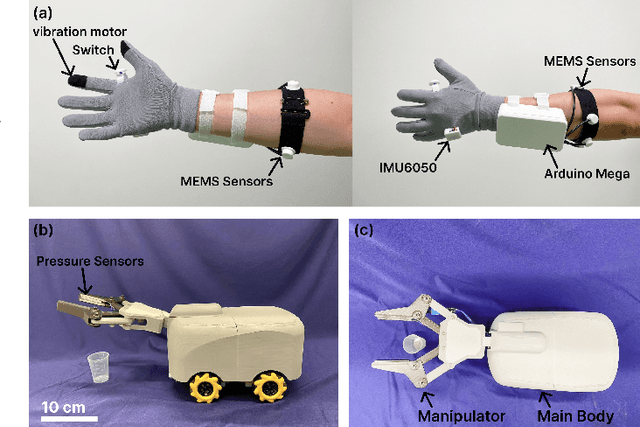
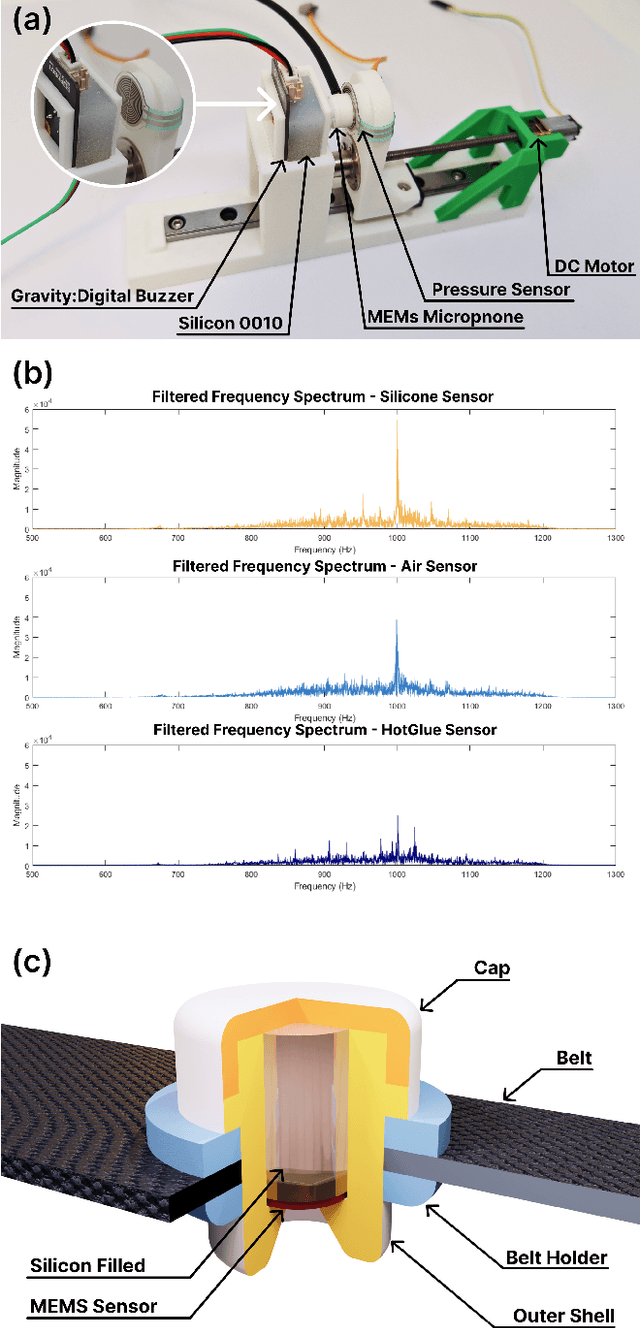
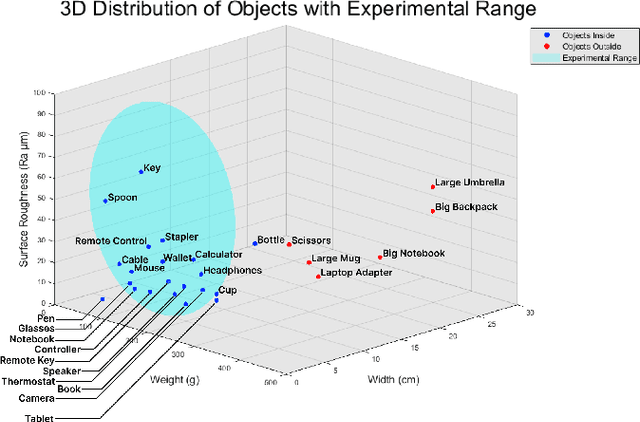
This paper proposes a wearable-controlled mobile manipulator system for intelligent smart home assistance, integrating MEMS capacitive microphones, IMU sensors, vibration motors, and pressure feedback to enhance human-robot interaction. The wearable device captures forearm muscle activity and converts it into real-time control signals for mobile manipulation. The wearable device achieves an offline classification accuracy of 88.33\%\ across six distinct movement-force classes for hand gestures by using a CNN-LSTM model, while real-world experiments involving five participants yield a practical accuracy of 83.33\%\ with an average system response time of 1.2 seconds. In Human-Robot synergy in navigation and grasping tasks, the robot achieved a 98\%\ task success rate with an average trajectory deviation of only 3.6 cm. Finally, the wearable-controlled mobile manipulator system achieved a 93.3\%\ gripping success rate, a transfer success of 95.6\%\, and a full-task success rate of 91.1\%\ during object grasping and transfer tests, in which a total of 9 object-texture combinations were evaluated. These three experiments' results validate the effectiveness of MEMS-based wearable sensing combined with multi-sensor fusion for reliable and intuitive control of assistive robots in smart home scenarios.
DIVD: Deblurring with Improved Video Diffusion Model
Dec 01, 2024



Video deblurring presents a considerable challenge owing to the complexity of blur, which frequently results from a combination of camera shakes, and object motions. In the field of video deblurring, many previous works have primarily concentrated on distortion-based metrics, such as PSNR. However, this approach often results in a weak correlation with human perception and yields reconstructions that lack realism. Diffusion models and video diffusion models have respectively excelled in the fields of image and video generation, particularly achieving remarkable results in terms of image authenticity and realistic perception. However, due to the computational complexity and challenges inherent in adapting diffusion models, there is still uncertainty regarding the potential of video diffusion models in video deblurring tasks. To explore the viability of video diffusion models in the task of video deblurring, we introduce a diffusion model specifically for this purpose. In this field, leveraging highly correlated information between adjacent frames and addressing the challenge of temporal misalignment are crucial research directions. To tackle these challenges, many improvements based on the video diffusion model are introduced in this work. As a result, our model outperforms existing models and achieves state-of-the-art results on a range of perceptual metrics. Our model preserves a significant amount of detail in the images while maintaining competitive distortion metrics. Furthermore, to the best of our knowledge, this is the first time the diffusion model has been applied in video deblurring to overcome the limitations mentioned above.
AdaViPro: Region-based Adaptive Visual Prompt for Large-Scale Models Adapting
Mar 20, 2024



Recently, prompt-based methods have emerged as a new alternative `parameter-efficient fine-tuning' paradigm, which only fine-tunes a small number of additional parameters while keeping the original model frozen. However, despite achieving notable results, existing prompt methods mainly focus on `what to add', while overlooking the equally important aspect of `where to add', typically relying on the manually crafted placement. To this end, we propose a region-based Adaptive Visual Prompt, named AdaViPro, which integrates the `where to add' optimization of the prompt into the learning process. Specifically, we reconceptualize the `where to add' optimization as a problem of regional decision-making. During inference, AdaViPro generates a regionalized mask map for the whole image, which is composed of 0 and 1, to designate whether to apply or discard the prompt in each specific area. Therefore, we employ Gumbel-Softmax sampling to enable AdaViPro's end-to-end learning through standard back-propagation. Extensive experiments demonstrate that our AdaViPro yields new efficiency and accuracy trade-offs for adapting pre-trained models.
View while Moving: Efficient Video Recognition in Long-untrimmed Videos
Aug 09, 2023



Recent adaptive methods for efficient video recognition mostly follow the two-stage paradigm of "preview-then-recognition" and have achieved great success on multiple video benchmarks. However, this two-stage paradigm involves two visits of raw frames from coarse-grained to fine-grained during inference (cannot be parallelized), and the captured spatiotemporal features cannot be reused in the second stage (due to varying granularity), being not friendly to efficiency and computation optimization. To this end, inspired by human cognition, we propose a novel recognition paradigm of "View while Moving" for efficient long-untrimmed video recognition. In contrast to the two-stage paradigm, our paradigm only needs to access the raw frame once. The two phases of coarse-grained sampling and fine-grained recognition are combined into unified spatiotemporal modeling, showing great performance. Moreover, we investigate the properties of semantic units in video and propose a hierarchical mechanism to efficiently capture and reason about the unit-level and video-level temporal semantics in long-untrimmed videos respectively. Extensive experiments on both long-untrimmed and short-trimmed videos demonstrate that our approach outperforms state-of-the-art methods in terms of accuracy as well as efficiency, yielding new efficiency and accuracy trade-offs for video spatiotemporal modeling.
Tensor Restricted Isometry Property Analysis For a Large Class of Random Measurement Ensembles
Jun 04, 2019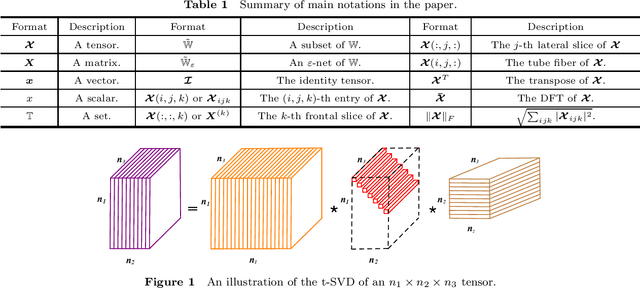
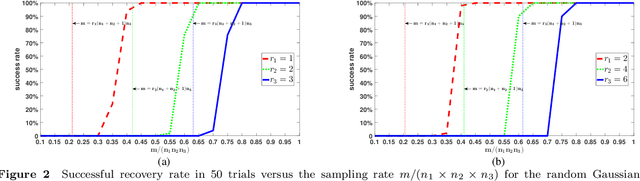
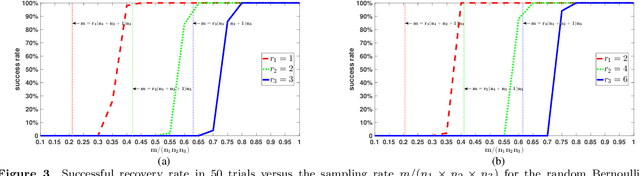
In previous work, theoretical analysis based on the tensor Restricted Isometry Property (t-RIP) established the robust recovery guarantees of a low-tubal-rank tensor. The obtained sufficient conditions depend strongly on the assumption that the linear measurement maps satisfy the t-RIP. In this paper, by exploiting the probabilistic arguments, we prove that such linear measurement maps exist under suitable conditions on the number of measurements in terms of the tubal rank r and the size of third-order tensor n1, n2, n3. And the obtained minimal possible number of linear measurements is nearly optimal compared with the degrees of freedom of a tensor with tubal rank r. Specially, we consider a random sub-Gaussian distribution that includes Gaussian, Bernoulli and all bounded distributions and construct a large class of linear maps that satisfy a t-RIP with high probability. Moreover, the validity of the required number of measurements is verified by numerical experiments.