 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM for Large-Scale Optimization Model Auto-Formulation: A Lightweight Few-Shot Learning Approach
Jan 14, 2026Large-scale optimization is a key backbone of modern business decision-making. However, building these models is often labor-intensive and time-consuming. We address this by proposing LEAN-LLM-OPT, a LightwEight AgeNtic workflow construction framework for LLM-assisted large-scale OPTimization auto-formulation. LEAN-LLM-OPT takes as input a problem description together with associated datasets and orchestrates a team of LLM agents to produce an optimization formulation. Specifically, upon receiving a query, two upstream LLM agents dynamically construct a workflow that specifies, step-by-step, how optimization models for similar problems can be formulated. A downstream LLM agent then follows this workflow to generate the final output. Leveraging LLMs' text-processing capabilities and common modeling practices, the workflow decomposes the modeling task into a sequence of structured sub-tasks and offloads mechanical data-handling operations to auxiliary tools. This design alleviates the downstream agent's burden related to planning and data handling, allowing it to focus on the most challenging components that cannot be readily standardized. Extensive simulations show that LEAN-LLM-OPT, instantiated with GPT-4.1 and the open source gpt-oss-20B, achieves strong performance on large-scale optimization modeling tasks and is competitive with state-of-the-art approaches. In addition, in a Singapore Airlines choice-based revenue management use case, LEAN-LLM-OPT demonstrates practical value by achieving leading performance across a range of scenarios. Along the way, we introduce Large-Scale-OR and Air-NRM, the first comprehensive benchmarks for large-scale optimization auto-formulation. The code and data of this work is available at https://github.com/CoraLiang01/lean-llm-opt.
CCAD: Compressed Global Feature Conditioned Anomaly Detection
Dec 25, 2025Anomaly detection holds considerable industrial significance, especially in scenarios with limited anomalous data. Currently, reconstruction-based and unsupervised representation-based approaches are the primary focus. However, unsupervised representation-based methods struggle to extract robust features under domain shift, whereas reconstruction-based methods often suffer from low training efficiency and performance degradation due to insufficient constraints. To address these challenges, we propose a novel method named Compressed Global Feature Conditioned Anomaly Detection (CCAD). CCAD synergizes the strengths of both paradigms by adapting global features as a new modality condition for the reconstruction model. Furthermore, we design an adaptive compression mechanism to enhance both generalization and training efficiency. Extensive experiments demonstrate that CCAD consistently outperforms state-of-the-art methods in terms of AUC while achieving faster convergence. In addition, we contribute a reorganized and re-annotated version of the DAGM 2007 dataset with new annotations to further validate our method's effectiveness. The code for reproducing main results is available at https://github.com/chloeqxq/CCAD.
TAP: Parameter-efficient Task-Aware Prompting for Adverse Weather Removal
Aug 11, 2025Image restoration under adverse weather conditions has been extensively explored, leading to numerous high-performance methods. In particular, recent advances in All-in-One approaches have shown impressive results by training on multi-task image restoration datasets. However, most of these methods rely on dedicated network modules or parameters for each specific degradation type, resulting in a significant parameter overhead. Moreover, the relatedness across different restoration tasks is often overlooked. In light of these issues, we propose a parameter-efficient All-in-One image restoration framework that leverages task-aware enhanced prompts to tackle various adverse weather degradations.Specifically, we adopt a two-stage training paradigm consisting of a pretraining phase and a prompt-tuning phase to mitigate parameter conflicts across tasks. We first employ supervised learning to acquire general restoration knowledge, and then adapt the model to handle specific degradation via trainable soft prompts. Crucially, we enhance these task-specific prompts in a task-aware manner. We apply low-rank decomposition to these prompts to capture both task-general and task-specific characteristics, and impose contrastive constraints to better align them with the actual inter-task relatedness. These enhanced prompts not only improve the parameter efficiency of the restoration model but also enable more accurate task modeling, as evidenced by t-SNE analysis. Experimental results on different restoration tasks demonstrate that the proposed method achieves superior performance with only 2.75M parameters.
Multi-Sensor Fusion-Based Mobile Manipulator Remote Control for Intelligent Smart Home Assistance
Apr 17, 2025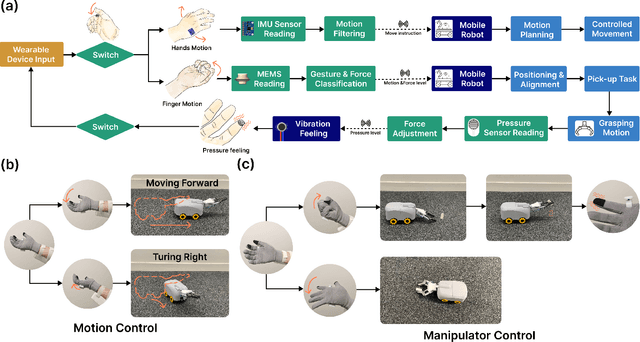
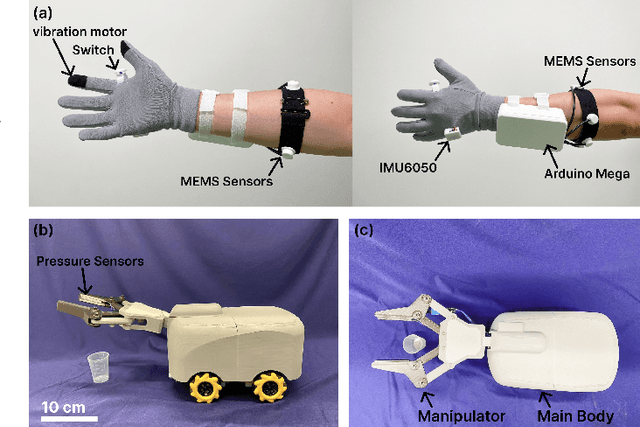
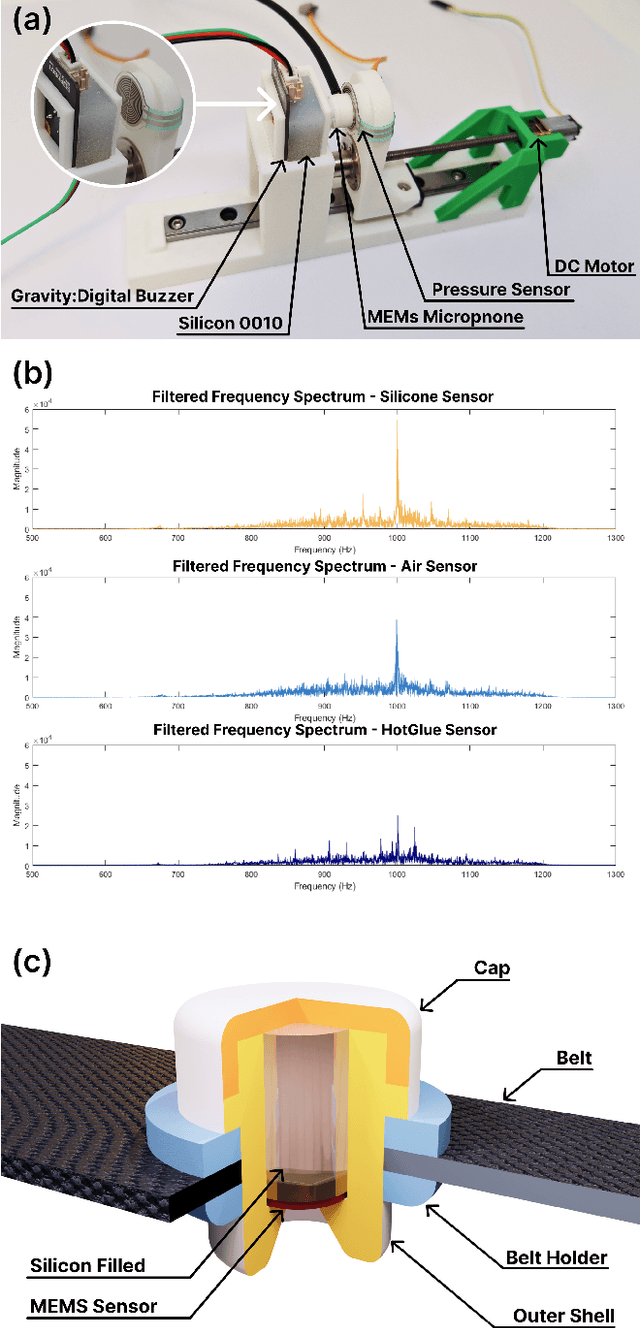
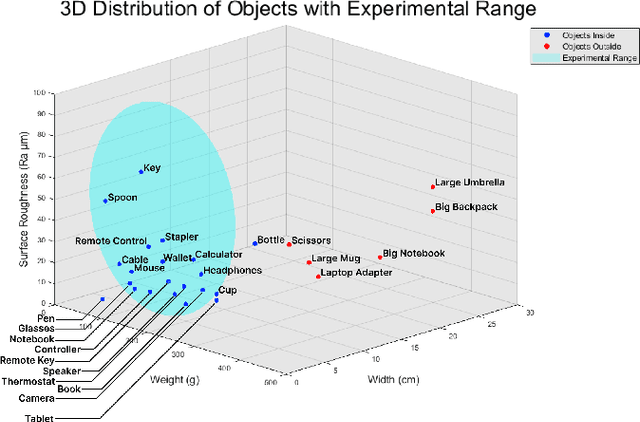
This paper proposes a wearable-controlled mobile manipulator system for intelligent smart home assistance, integrating MEMS capacitive microphones, IMU sensors, vibration motors, and pressure feedback to enhance human-robot interaction. The wearable device captures forearm muscle activity and converts it into real-time control signals for mobile manipulation. The wearable device achieves an offline classification accuracy of 88.33\%\ across six distinct movement-force classes for hand gestures by using a CNN-LSTM model, while real-world experiments involving five participants yield a practical accuracy of 83.33\%\ with an average system response time of 1.2 seconds. In Human-Robot synergy in navigation and grasping tasks, the robot achieved a 98\%\ task success rate with an average trajectory deviation of only 3.6 cm. Finally, the wearable-controlled mobile manipulator system achieved a 93.3\%\ gripping success rate, a transfer success of 95.6\%\, and a full-task success rate of 91.1\%\ during object grasping and transfer tests, in which a total of 9 object-texture combinations were evaluated. These three experiments' results validate the effectiveness of MEMS-based wearable sensing combined with multi-sensor fusion for reliable and intuitive control of assistive robots in smart home scenarios.
Physical Reservoir Computing in Hook-Shaped Rover Wheel Spokes for Real-Time Terrain Identification
Apr 17, 2025
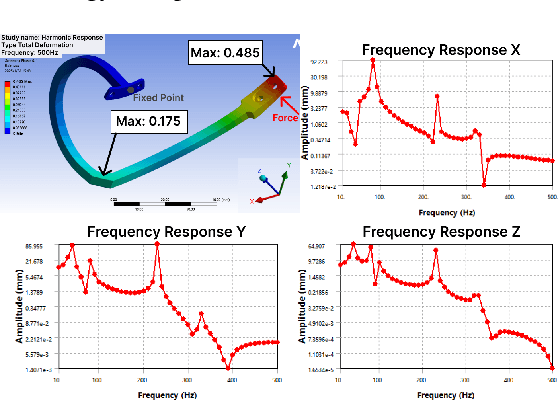
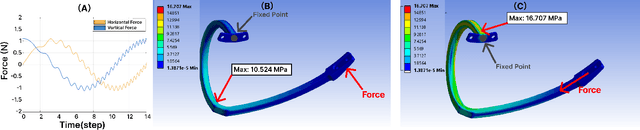
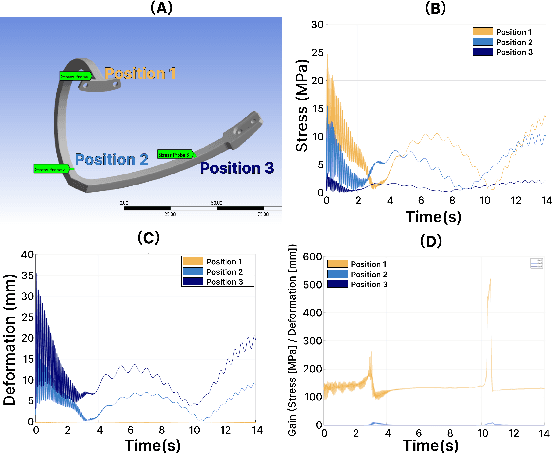
Effective terrain detection in unknown environments is crucial for safe and efficient robotic navigation. Traditional methods often rely on computationally intensive data processing, requiring extensive onboard computational capacity and limiting real-time performance for rovers. This study presents a novel approach that combines physical reservoir computing with piezoelectric sensors embedded in rover wheel spokes for real-time terrain identification. By leveraging wheel dynamics, terrain-induced vibrations are transformed into high-dimensional features for machine learning-based classification. Experimental results show that strategically placing three sensors on the wheel spokes achieves 90$\%$ classification accuracy, which demonstrates the accuracy and feasibility of the proposed method. The experiment results also showed that the system can effectively distinguish known terrains and identify unknown terrains by analyzing their similarity to learned categories. This method provides a robust, low-power framework for real-time terrain classification and roughness estimation in unstructured environments, enhancing rover autonomy and adaptability.
TSAL: Few-shot Text Segmentation Based on Attribute Learning
Apr 15, 2025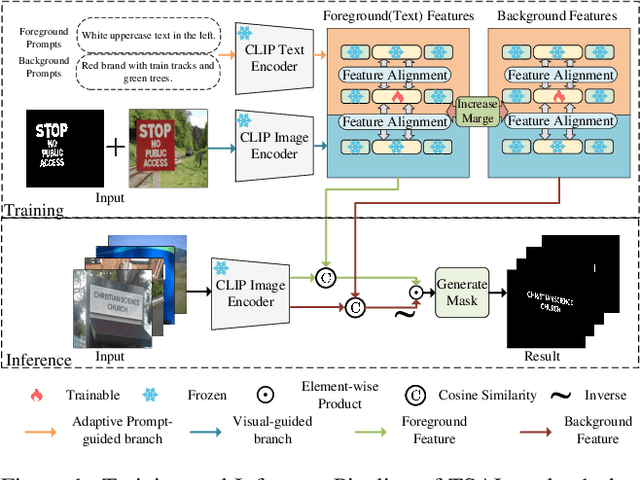
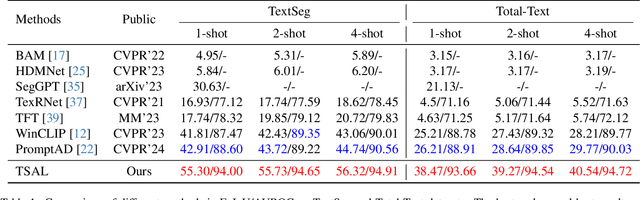
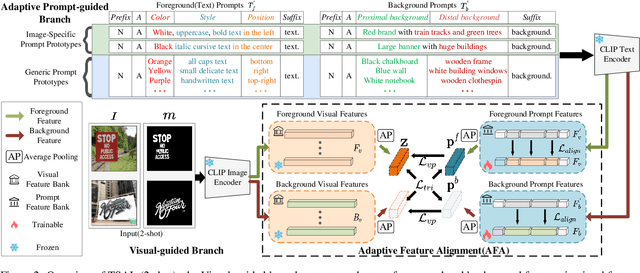
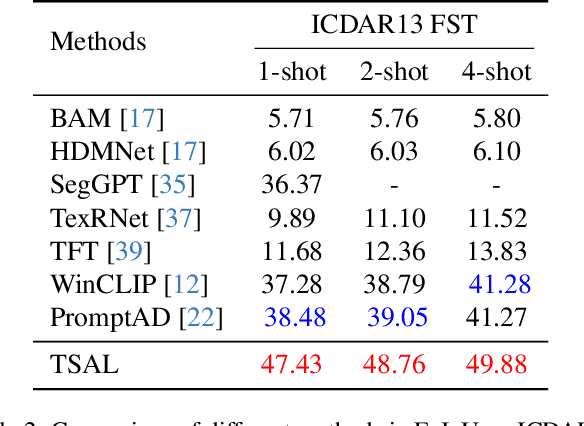
Recently supervised learning rapidly develops in scene text segmentation. However, the lack of high-quality datasets and the high cost of pixel annotation greatly limit the development of them. Considering the well-performed few-shot learning methods for downstream tasks, we investigate the application of the few-shot learning method to scene text segmentation. We propose TSAL, which leverages CLIP's prior knowledge to learn text attributes for segmentation. To fully utilize the semantic and texture information in the image, a visual-guided branch is proposed to separately extract text and background features. To reduce data dependency and improve text detection accuracy, the adaptive prompt-guided branch employs effective adaptive prompt templates to capture various text attributes. To enable adaptive prompts capture distinctive text features and complex background distribution, we propose Adaptive Feature Alignment module(AFA). By aligning learnable tokens of different attributes with visual features and prompt prototypes, AFA enables adaptive prompts to capture both general and distinctive attribute information. TSAL can capture the unique attributes of text and achieve precise segmentation using only few images. Experiments demonstrate that our method achieves SOTA performance on multiple text segmentation datasets under few-shot settings and show great potential in text-related domains.
Exploring Few-Shot Defect Segmentation in General Industrial Scenarios with Metric Learning and Vision Foundation Models
Feb 03, 2025



Industrial defect segmentation is critical for manufacturing quality control. Due to the scarcity of training defect samples, few-shot semantic segmentation (FSS) holds significant value in this field. However, existing studies mostly apply FSS to tackle defects on simple textures, without considering more diverse scenarios. This paper aims to address this gap by exploring FSS in broader industrial products with various defect types. To this end, we contribute a new real-world dataset and reorganize some existing datasets to build a more comprehensive few-shot defect segmentation (FDS) benchmark. On this benchmark, we thoroughly investigate metric learning-based FSS methods, including those based on meta-learning and those based on Vision Foundation Models (VFMs). We observe that existing meta-learning-based methods are generally not well-suited for this task, while VFMs hold great potential. We further systematically study the applicability of various VFMs in this task, involving two paradigms: feature matching and the use of Segment Anything (SAM) models. We propose a novel efficient FDS method based on feature matching. Meanwhile, we find that SAM2 is particularly effective for addressing FDS through its video track mode. The contributed dataset and code will be available at: https://github.com/liutongkun/GFDS.
Diff-Cleanse: Identifying and Mitigating Backdoor Attacks in Diffusion Models
Jul 31, 2024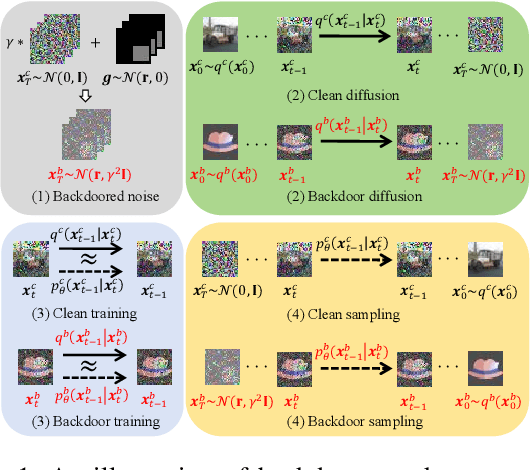
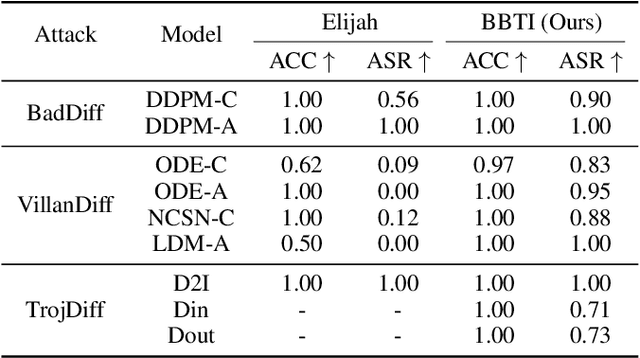
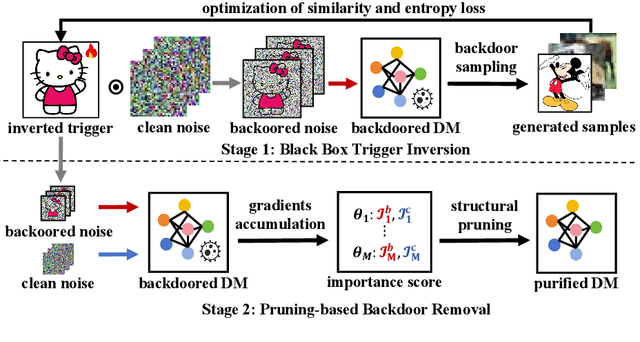
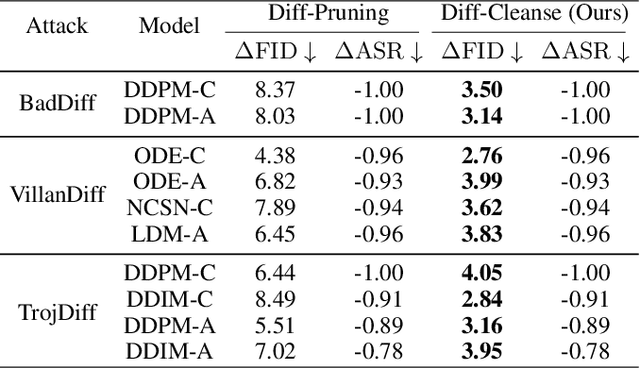
Diffusion models (DM) represent one of the most advanced generative models today, yet recent studies suggest that DMs are vulnerable to backdoor attacks. Backdoor attacks establish hidden associations between particular input patterns and model behaviors, compromising model integrity by triggering undesirable actions with manipulated input data. This vulnerability poses substantial risks, including reputational damage to model owners and the dissemination of harmful content. To mitigate the threat of backdoor attacks, there have been some investigations on backdoor detection and model repair. However, previous work fails to purify the backdoored DMs created by state-of-the-art attacks, rendering the field much underexplored. To bridge this gap, we introduce \textbf{Diff-Cleanse}, a novel two-stage backdoor defense framework specifically designed for DMs. The first stage employs a innovative trigger inversion technique to detect the backdoor and reconstruct the trigger, and the second stage utilizes a structural pruning method to eliminate the backdoor. We evaluate our framework on hundreds of DMs attacked by 3 existing backdoor attack methods. Extensive experiments demonstrate that Diff-Cleanse achieves nearly 100\% detection accuracy and effectively mitigates backdoor impacts, preserving the model's benign performance with minimal compromise. Our code is avaliable at https://github.com/shymuel/diff-cleanse.
HODINet: High-Order Discrepant Interaction Network for RGB-D Salient Object Detection
Jul 03, 2023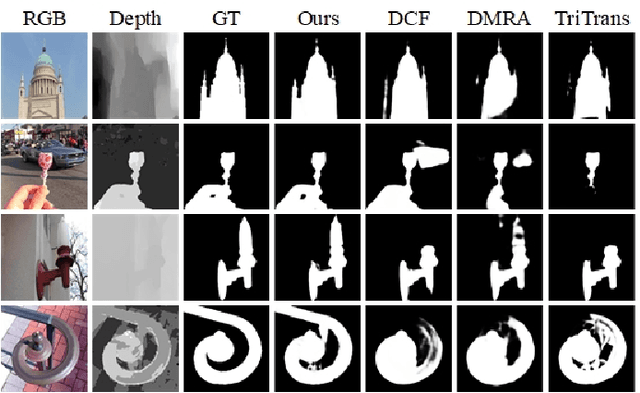
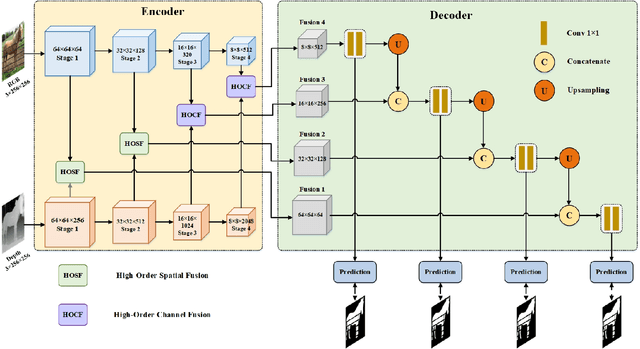
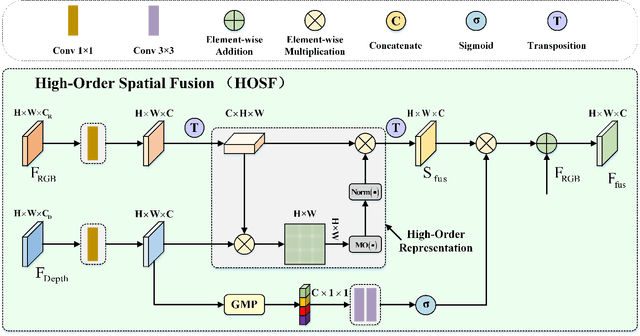
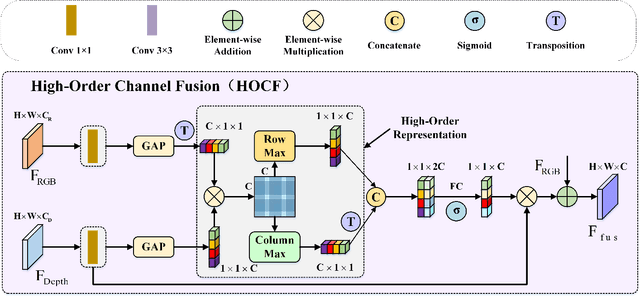
RGB-D salient object detection (SOD) aims to detect the prominent regions by jointly modeling RGB and depth information. Most RGB-D SOD methods apply the same type of backbones and fusion modules to identically learn the multimodality and multistage features. However, these features contribute differently to the final saliency results, which raises two issues: 1) how to model discrepant characteristics of RGB images and depth maps; 2) how to fuse these cross-modality features in different stages. In this paper, we propose a high-order discrepant interaction network (HODINet) for RGB-D SOD. Concretely, we first employ transformer-based and CNN-based architectures as backbones to encode RGB and depth features, respectively. Then, the high-order representations are delicately extracted and embedded into spatial and channel attentions for cross-modality feature fusion in different stages. Specifically, we design a high-order spatial fusion (HOSF) module and a high-order channel fusion (HOCF) module to fuse features of the first two and the last two stages, respectively. Besides, a cascaded pyramid reconstruction network is adopted to progressively decode the fused features in a top-down pathway. Extensive experiments are conducted on seven widely used datasets to demonstrate the effectiveness of the proposed approach. We achieve competitive performance against 24 state-of-the-art methods under four evaluation metrics.
Searching for the Fakes: Efficient Neural Architecture Search for General Face Forgery Detection
Jun 16, 2023As the saying goes, "seeing is believing". However, with the development of digital face editing tools, we can no longer trust what we can see. Although face forgery detection has made promising progress, most current methods are designed manually by human experts, which is labor-consuming. In this paper, we develop an end-to-end framework based on neural architecture search (NAS) for deepfake detection, which can automatically design network architectures without human intervention. First, a forgery-oriented search space is created to choose appropriate operations for this task. Second, we propose a novel performance estimation metric, which guides the search process to select more general models. The cross-dataset search is also considered to develop more general architectures. Eventually, we connect the cells in a cascaded pyramid way for final forgery classification. Compared with state-of-the-art networks artificially designed, our method achieves competitive performance in both in-dataset and cross-dataset scenarios.