 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Mutual Learning Network with Global-local Awareness for RGB-D Salient Object Detection
Jan 03, 2025



RGB-D salient object detection (SOD), aiming to highlight prominent regions of a given scene by jointly modeling RGB and depth information, is one of the challenging pixel-level prediction tasks. Recently, the dual-attention mechanism has been devoted to this area due to its ability to strengthen the detection process. However, most existing methods directly fuse attentional cross-modality features under a manual-mandatory fusion paradigm without considering the inherent discrepancy between the RGB and depth, which may lead to a reduction in performance. Moreover, the long-range dependencies derived from global and local information make it difficult to leverage a unified efficient fusion strategy. Hence, in this paper, we propose the GL-DMNet, a novel dual mutual learning network with global-local awareness. Specifically, we present a position mutual fusion module and a channel mutual fusion module to exploit the interdependencies among different modalities in spatial and channel dimensions. Besides, we adopt an efficient decoder based on cascade transformer-infused reconstruction to integrate multi-level fusion features jointly. Extensive experiments on six benchmark datasets demonstrate that our proposed GL-DMNet performs better than 24 RGB-D SOD methods, achieving an average improvement of ~3% across four evaluation metrics compared to the second-best model (S3Net). Codes and results are available at https://github.com/kingkung2016/GL-DMNet.
HODINet: High-Order Discrepant Interaction Network for RGB-D Salient Object Detection
Jul 03, 2023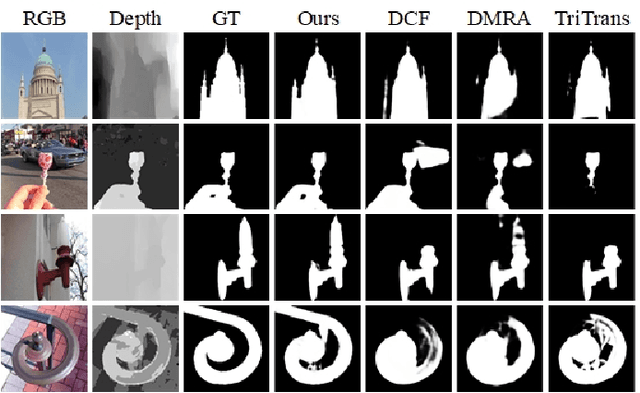
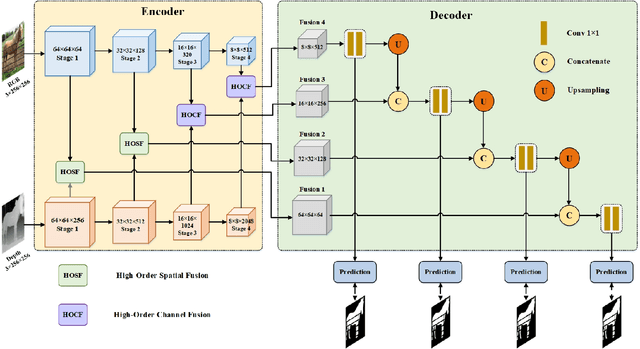
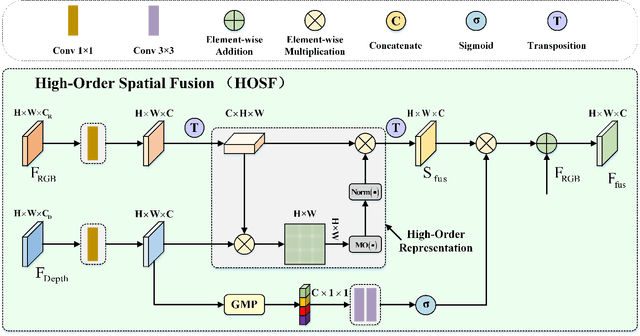
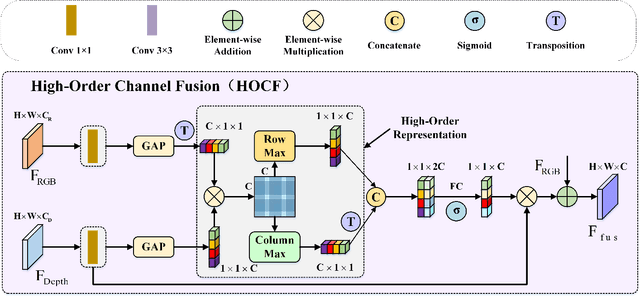
RGB-D salient object detection (SOD) aims to detect the prominent regions by jointly modeling RGB and depth information. Most RGB-D SOD methods apply the same type of backbones and fusion modules to identically learn the multimodality and multistage features. However, these features contribute differently to the final saliency results, which raises two issues: 1) how to model discrepant characteristics of RGB images and depth maps; 2) how to fuse these cross-modality features in different stages. In this paper, we propose a high-order discrepant interaction network (HODINet) for RGB-D SOD. Concretely, we first employ transformer-based and CNN-based architectures as backbones to encode RGB and depth features, respectively. Then, the high-order representations are delicately extracted and embedded into spatial and channel attentions for cross-modality feature fusion in different stages. Specifically, we design a high-order spatial fusion (HOSF) module and a high-order channel fusion (HOCF) module to fuse features of the first two and the last two stages, respectively. Besides, a cascaded pyramid reconstruction network is adopted to progressively decode the fused features in a top-down pathway. Extensive experiments are conducted on seven widely used datasets to demonstrate the effectiveness of the proposed approach. We achieve competitive performance against 24 state-of-the-art methods under four evaluation metrics.