 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHODINet: High-Order Discrepant Interaction Network for RGB-D Salient Object Detection
Paper and Code
Jul 03, 2023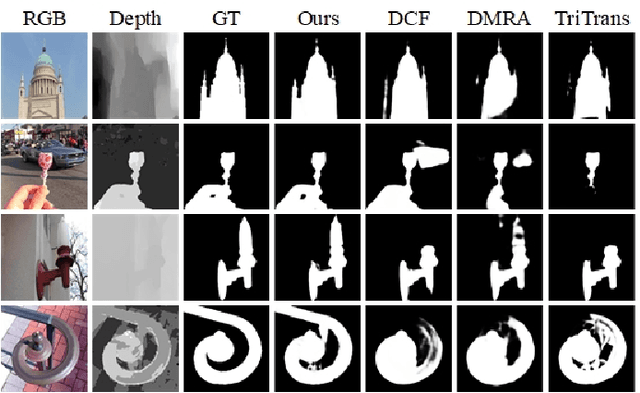
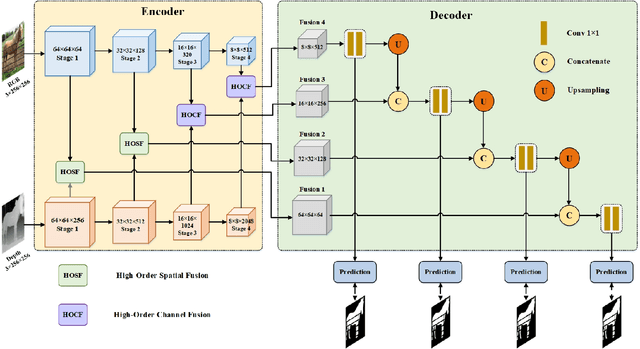
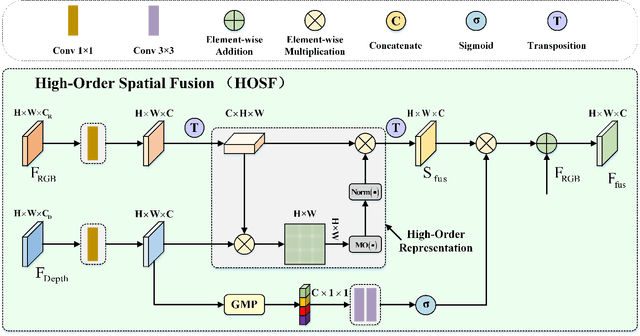
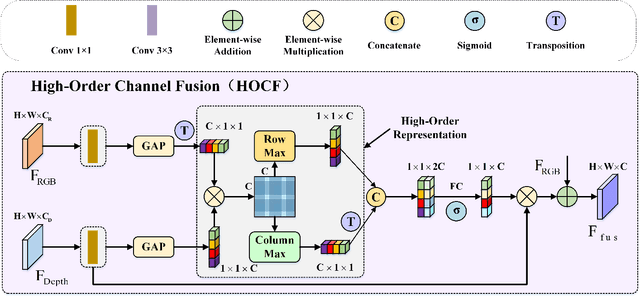
RGB-D salient object detection (SOD) aims to detect the prominent regions by jointly modeling RGB and depth information. Most RGB-D SOD methods apply the same type of backbones and fusion modules to identically learn the multimodality and multistage features. However, these features contribute differently to the final saliency results, which raises two issues: 1) how to model discrepant characteristics of RGB images and depth maps; 2) how to fuse these cross-modality features in different stages. In this paper, we propose a high-order discrepant interaction network (HODINet) for RGB-D SOD. Concretely, we first employ transformer-based and CNN-based architectures as backbones to encode RGB and depth features, respectively. Then, the high-order representations are delicately extracted and embedded into spatial and channel attentions for cross-modality feature fusion in different stages. Specifically, we design a high-order spatial fusion (HOSF) module and a high-order channel fusion (HOCF) module to fuse features of the first two and the last two stages, respectively. Besides, a cascaded pyramid reconstruction network is adopted to progressively decode the fused features in a top-down pathway. Extensive experiments are conducted on seven widely used datasets to demonstrate the effectiveness of the proposed approach. We achieve competitive performance against 24 state-of-the-art methods under four evaluation metrics.