 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSAL: Few-shot Text Segmentation Based on Attribute Learning
Apr 15, 2025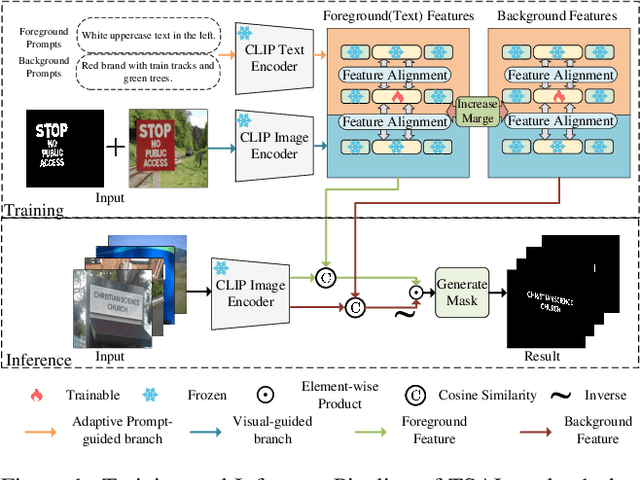
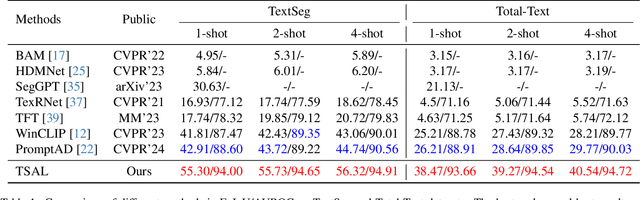
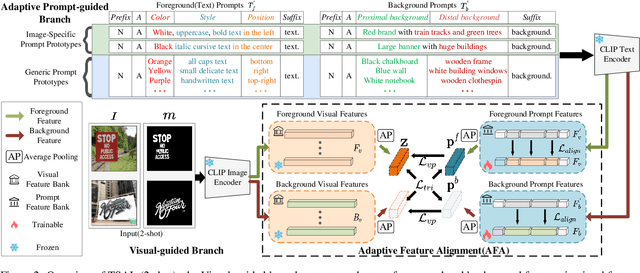
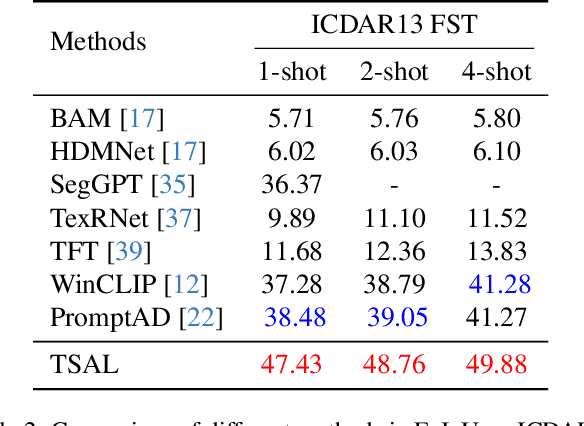
Recently supervised learning rapidly develops in scene text segmentation. However, the lack of high-quality datasets and the high cost of pixel annotation greatly limit the development of them. Considering the well-performed few-shot learning methods for downstream tasks, we investigate the application of the few-shot learning method to scene text segmentation. We propose TSAL, which leverages CLIP's prior knowledge to learn text attributes for segmentation. To fully utilize the semantic and texture information in the image, a visual-guided branch is proposed to separately extract text and background features. To reduce data dependency and improve text detection accuracy, the adaptive prompt-guided branch employs effective adaptive prompt templates to capture various text attributes. To enable adaptive prompts capture distinctive text features and complex background distribution, we propose Adaptive Feature Alignment module(AFA). By aligning learnable tokens of different attributes with visual features and prompt prototypes, AFA enables adaptive prompts to capture both general and distinctive attribute information. TSAL can capture the unique attributes of text and achieve precise segmentation using only few images. Experiments demonstrate that our method achieves SOTA performance on multiple text segmentation datasets under few-shot settings and show great potential in text-related domains.
Cross Contrasting Feature Perturbation for Domain Generalization
Aug 16, 2023Domain generalization (DG) aims to learn a robust model from source domains that generalize well on unseen target domains. Recent studies focus on generating novel domain samples or features to diversify distributions complementary to source domains. Yet, these approaches can hardly deal with the restriction that the samples synthesized from various domains can cause semantic distortion. In this paper, we propose an online one-stage Cross Contrasting Feature Perturbation (CCFP) framework to simulate domain shift by generating perturbed features in the latent space while regularizing the model prediction against domain shift. Different from the previous fixed synthesizing strategy, we design modules with learnable feature perturbations and semantic consistency constraints. In contrast to prior work, our method does not use any generative-based models or domain labels. We conduct extensive experiments on a standard DomainBed benchmark with a strict evaluation protocol for a fair comparison. Comprehensive experiments show that our method outperforms the previous state-of-the-art, and quantitative analyses illustrate that our approach can alleviate the domain shift problem in out-of-distribution (OOD) scenarios.
Aggregation of Disentanglement: Reconsidering Domain Variations in Domain Generalization
Feb 05, 2023Domain Generalization (DG) is a fundamental challenge for machine learning models, which aims to improve model generalization on various domains. Previous methods focus on generating domain invariant features from various source domains. However, we argue that the domain variantions also contain useful information, ie, classification-aware information, for downstream tasks, which has been largely ignored. Different from learning domain invariant features from source domains, we decouple the input images into Domain Expert Features and noise. The proposed domain expert features lie in a learned latent space where the images in each domain can be classified independently, enabling the implicit use of classification-aware domain variations. Based on the analysis, we proposed a novel paradigm called Domain Disentanglement Network (DDN) to disentangle the domain expert features from the source domain images and aggregate the source domain expert features for representing the target test domain. We also propound a new contrastive learning method to guide the domain expert features to form a more balanced and separable feature space. Experiments on the widely-used benchmarks of PACS, VLCS, OfficeHome, DomainNet, and TerraIncognita demonstrate the competitive performance of our method compared to the recently proposed alternatives.
Rethinking Alignment and Uniformity in Unsupervised Image Semantic Segmentation
Nov 26, 2022Unsupervised image semantic segmentation(UISS) aims to match low-level visual features with semantic-level representations without outer supervision. In this paper, we address the critical properties from the view of feature alignments and feature uniformity for UISS models. We also make a comparison between UISS and image-wise representation learning. Based on the analysis, we argue that the existing MI-based methods in UISS suffer from representation collapse. By this, we proposed a robust network called Semantic Attention Network(SAN), in which a new module Semantic Attention(SEAT) is proposed to generate pixel-wise and semantic features dynamically. Experimental results on multiple semantic segmentation benchmarks show that our unsupervised segmentation framework specializes in catching semantic representations, which outperforms all the unpretrained and even several pretrained methods.
BiAIT*: Symmetrical Bidirectional Optimal Path Planning with Adaptive Heuristic
May 14, 2022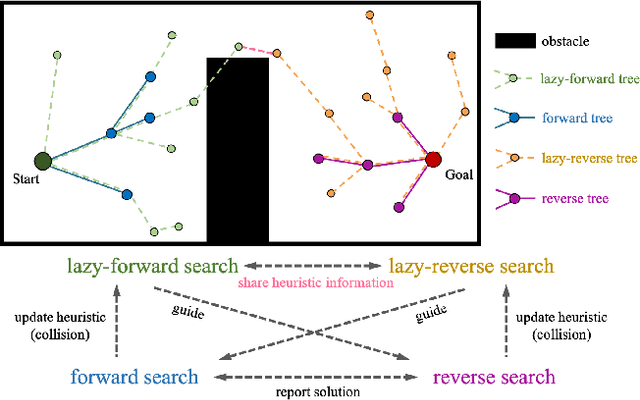
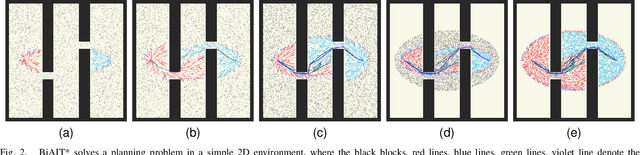
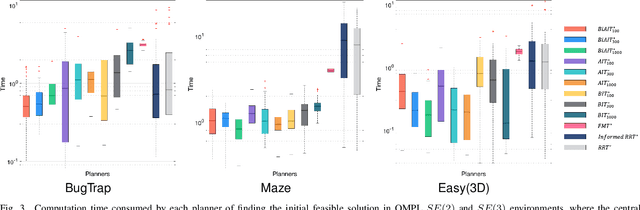

Adaptively Informed Trees (AIT*) develops the problem-specific heuristic under the current topological abstraction of the state space with a lazy-reverse tree that is constructed without collision checking. AIT* can avoid unnecessary searching with the heuristic, which significantly improves the algorithm performance, especially when collision checking is expensive. However, the heuristic estimation in AIT* consumes lots of computation resources, and its asymmetric bidirectional searching strategy cannot fully exploit the potential of the bidirectional method. In this article, we extend AIT* from the asymmetric bidirectional search to the symmetrical bidirectional search, namely BiAIT*. Both the heuristic and space searching in BiAIT* are calculated bidirectionally. The path planner can find the initial solution faster with our proposed method. In addition, when a collision happens, BiAIT* can update the heuristic with less computation. Simulations are carried out to evaluate the performance of the proposed algorithm, and the results show that our algorithm can find the solution faster than the state of the arts. We also analyze the reason for different performances between BiAIT* and AIT*. Furthermore, we discuss two simple but effective modifications to fully exploit the potential of the adaptively heuristic method.
Enhance Connectivity of Promising Regions for Sampling-based Path Planning
Dec 15, 2021
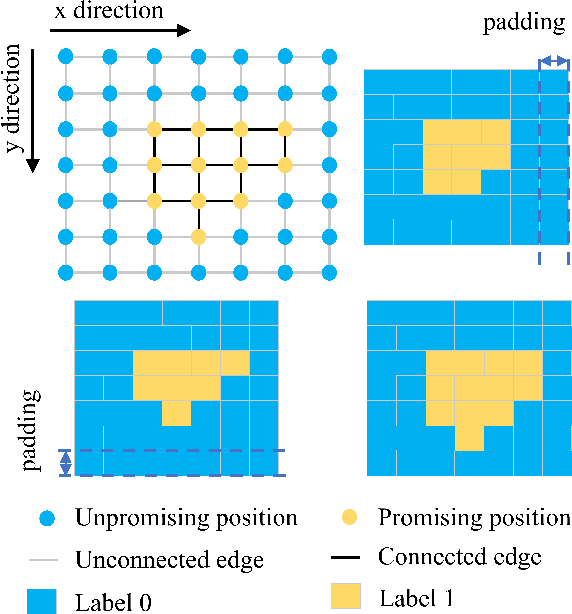
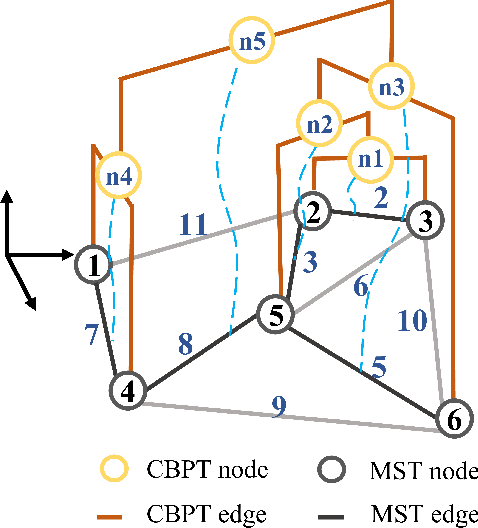
Sampling-based path planning algorithms usually implement uniform sampling methods to search the state space. However, uniform sampling may lead to unnecessary exploration in many scenarios, such as the environment with a few dead ends. Our previous work proposes to use the promising region to guide the sampling process to address the issue. However, the predicted promising regions are often disconnected, which means they cannot connect the start and goal state, resulting in a lack of probabilistic completeness. This work focuses on enhancing the connectivity of predicted promising regions. Our proposed method regresses the connectivity probability of the edges in the x and y directions. In addition, it calculates the weight of the promising edges in loss to guide the neural network to pay more attention to the connectivity of the promising regions. We conduct a series of simulation experiments, and the results show that the connectivity of promising regions improves significantly. Furthermore, we analyze the effect of connectivity on sampling-based path planning algorithms and conclude that connectivity plays an essential role in maintaining algorithm performance.
Shallow Network Based on Depthwise Over-Parameterized Convolution for Hyperspectral Image Classification
Dec 01, 2021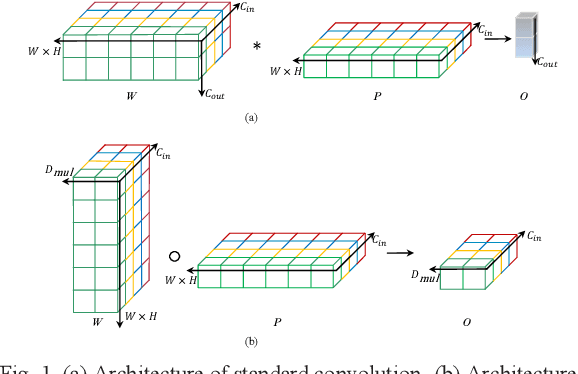
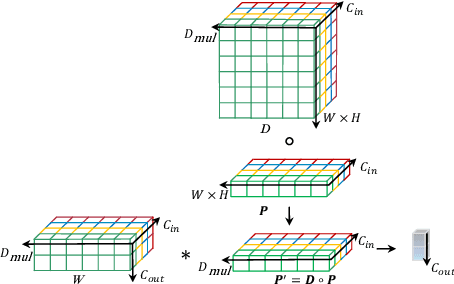
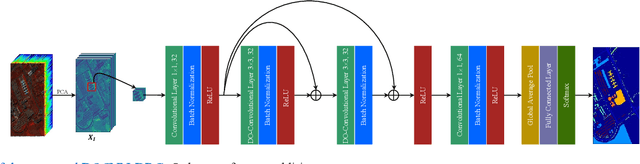
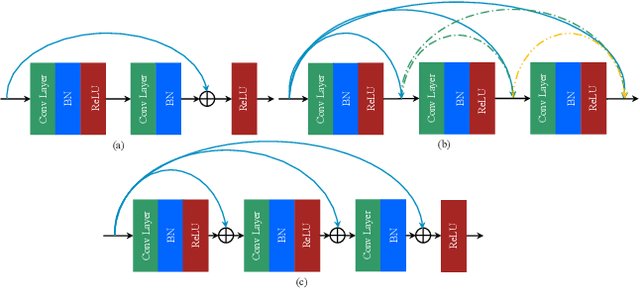
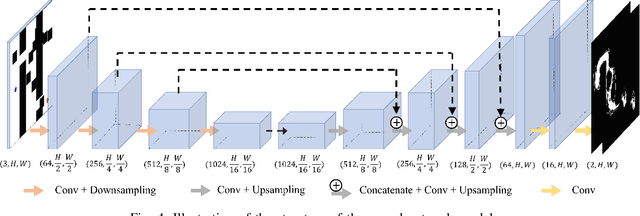
Recently, convolutional neural network (CNN) techniques have gained popularity as a tool for hyperspectral image classification (HSIC). To improve the feature extraction efficiency of HSIC under the condition of limited samples, the current methods generally use deep models with plenty of layers. However, deep network models are prone to overfitting and gradient vanishing problems when samples are limited. In addition, the spatial resolution decreases severely with deeper depth, which is very detrimental to spatial edge feature extraction. Therefore, this letter proposes a shallow model for HSIC, which is called depthwise over-parameterized convolutional neural network (DOCNN). To ensure the effective extraction of the shallow model, the depthwise over-parameterized convolution (DO-Conv) kernel is introduced to extract the discriminative features. The depthwise over-parameterized Convolution kernel is composed of a standard convolution kernel and a depthwise convolution kernel, which can extract the spatial feature of the different channels individually and fuse the spatial features of the whole channels simultaneously. Moreover, to further reduce the loss of spatial edge features due to the convolution operation, a dense residual connection (DRC) structure is proposed to apply to the feature extraction part of the whole network. Experimental results obtained from three benchmark data sets show that the proposed method outperforms other state-of-the-art methods in terms of classification accuracy and computational efficiency.
Relevant Region Sampling Strategy with Adaptive Heuristic Estimation for Asymptotically Optimal Motion Planning
Oct 31, 2021
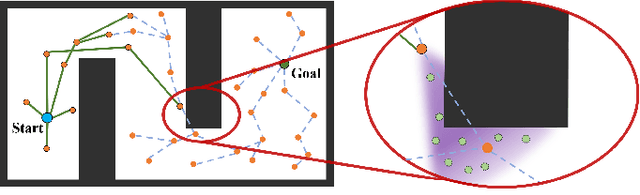
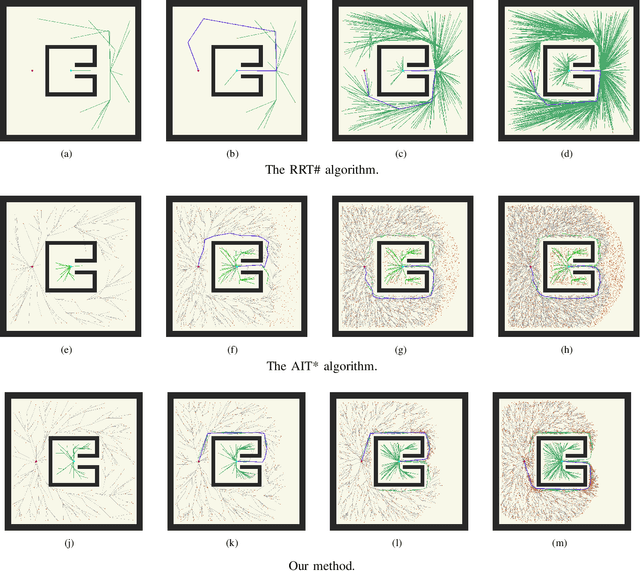
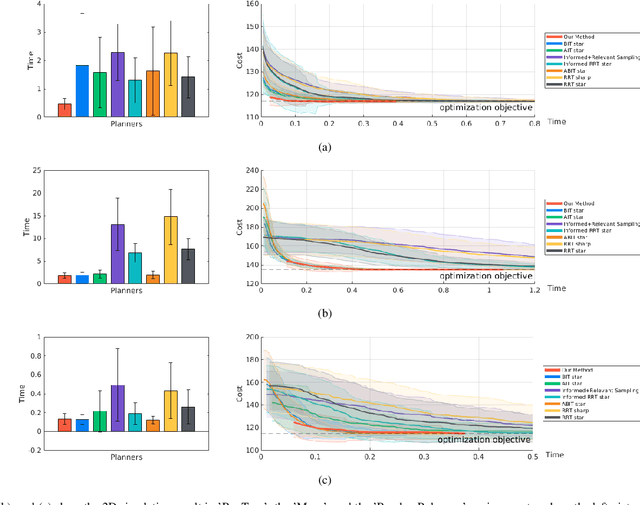
The sampling-based motion planning algorithms can solve the motion planning problem in high-dimensional state space efficiently. This article presents a novel approach to sample in the promising region and reduce planning time remarkably. The RRT# defines the Relevant Region according to the cost-to-come provided by the optimal forward-searching tree; however, it takes the cumulative cost of a direct connection between the current state and the goal state as the cost-to-go. We propose a batch sampling method that samples in the refined Relevant Region, which is defined according to the optimal cost-to-come and the adaptive cost-to-go. In our method, the cost-to-come and the cost-to-go of a specific vertex are estimated by the valid optimal forward-searching tree and the lazy reverse-searching tree, respectively. New samples are generated with a direct sampling method, which can take advantage of the heuristic estimation result. We carry on several simulations in both SE(2) and SE(3) state spaces to validate the effectiveness of our method. Simulation results demonstrate that the proposed algorithm can find a better initial solution and consumes less planning time than related work.
HouseExpo: A Large-scale 2D Indoor Layout Dataset for Learning-based Algorithms on Mobile Robots
Mar 23, 2019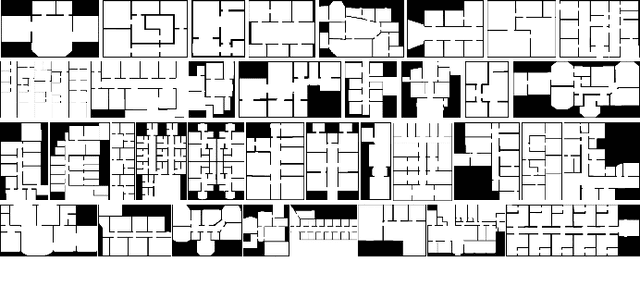
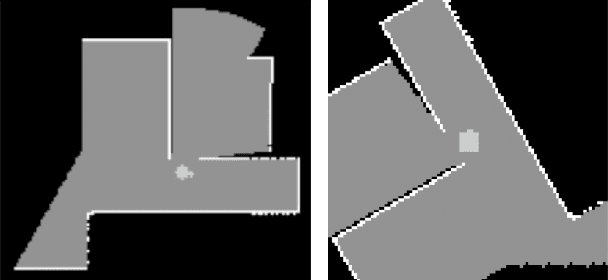
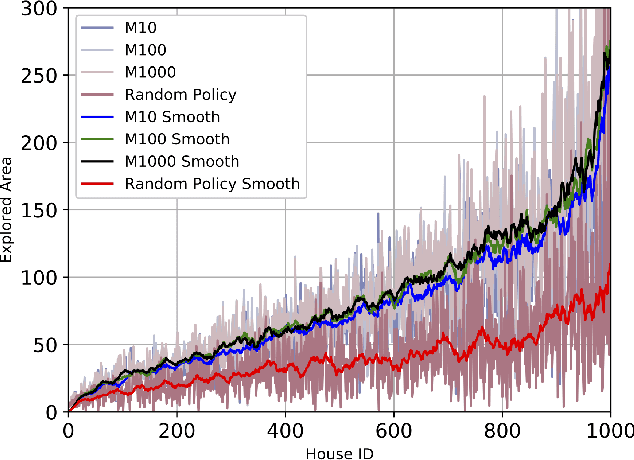
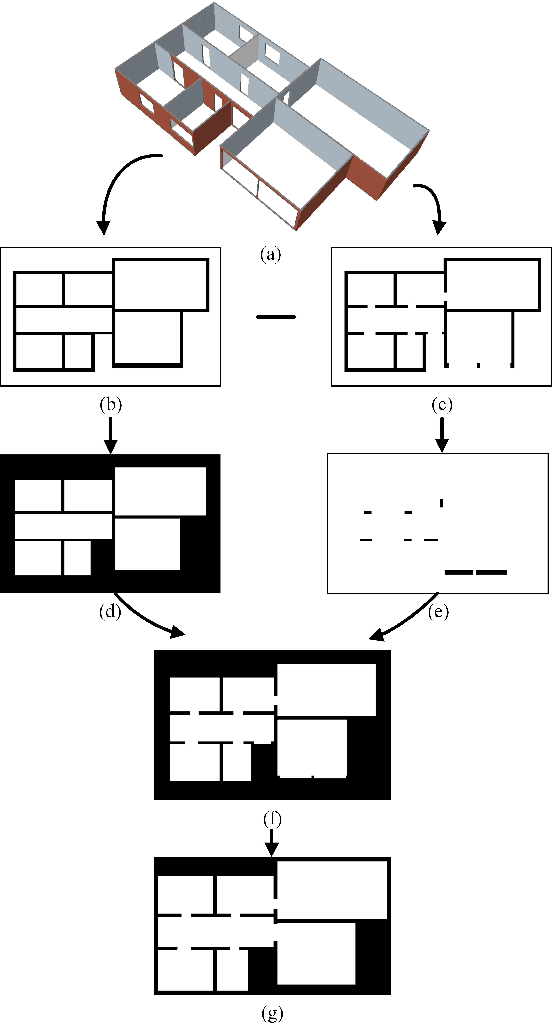
As one of the most promising areas, mobile robots draw much attention these years. Current work in this field is often evaluated in a few manually designed scenarios, due to the lack of a common experimental platform. Meanwhile, with the recent development of deep learning techniques, some researchers attempt to apply learning-based methods to mobile robot tasks, which requires a substantial amount of data. To satisfy the underlying demand, in this paper we build HouseExpo, a large-scale indoor layout dataset containing 35,357 2D floor plans including 252,550 rooms in total. Together we develop Pseudo-SLAM, a lightweight and efficient simulation platform to accelerate the data generation procedure, thereby speeding up the training process. In our experiments, we build models to tackle obstacle avoidance and autonomous exploration from a learning perspective in simulation as well as real-world experiments to verify the effectiveness of our simulator and dataset. All the data and codes are available online and we hope HouseExpo and Pseudo-SLAM can feed the need for data and benefits the whole community.