 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Fall Recovery for Armless Bipedal-Wheeled Robots Via Force-Guided Learning
Jun 12, 2026Fall recovery is critical for autonomous legged locomotion. Existing methods have demonstrated that some legged robots, such as humanoids and quadrupeds, are capable of fall recovery from diverse postures by utilizing arms or coordinating multi-legs to generate support forces. Without arms or other legs to provide supportive assistance, a bipedal-wheeled robot must rely solely on the actuation of its legs, making recovery particularly difficult. To address this, we introduce FTSR (Force-guided Teacher-student framework with Stage-wise Rewards). The force-guided method constructs an external auxiliary force during simulation training that correlates directly with the robot's real-time height, explicitly formulating this force as an optimizable constraint. Through constrained reinforcement learning, the policy is guided toward reducing force dependency gradually and increasing the body height, developing internal recovery strategies despite having no arms for support. Height-progressive stage-Wise rewards progressively structure posture stabilization during recovery and transition to sustained locomotion, integrated with teacher-student architecture distilling privileged knowledge of force effects and recovery dynamics. After simulation training, the policy is deployed on a physical armless bipedal-wheeled robot and extensively evaluated. Experiments confirm robust and reliable fall recovery under diverse challenging conditions, demonstrating strong environmental adaptability and motion robustness, while maintaining full post-recovery motion capability. The framework also generalizes effectively to a high-DOF humanoid, confirming its practical generalizability. The project page is available at https://2350575870.github.io/force-guided.github.io/
* 8 pages, 6 figures, accepted by IEEE Robotics and Automation Letters (RA-L)
PoM: A Linear-Time Replacement for Attention with the Polynomial Mixer
Apr 07, 2026This paper introduces the Polynomial Mixer (PoM), a novel token mixing mechanism with linear complexity that serves as a drop-in replacement for self-attention. PoM aggregates input tokens into a compact representation through a learned polynomial function, from which each token retrieves contextual information. We prove that PoM satisfies the contextual mapping property, ensuring that transformers equipped with PoM remain universal sequence-to-sequence approximators. We replace standard self-attention with PoM across five diverse domains: text generation, handwritten text recognition, image generation, 3D modeling, and Earth observation. PoM matches the performance of attention-based models while drastically reducing computational cost when working with long sequences. The code is available at https://github.com/davidpicard/pom.
Provably Safe Trajectory Generation for Manipulators Under Motion and Environmental Uncertainties
Mar 10, 2026Robot manipulators operating in uncertain and non-convex environments present significant challenges for safe and optimal motion planning. Existing methods often struggle to provide efficient and formally certified collision risk guarantees, particularly when dealing with complex geometries and non-Gaussian uncertainties. This article proposes a novel risk-bounded motion planning framework to address this unmet need. Our approach integrates a rigid manipulator deep stochastic Koopman operator (RM-DeSKO) model to robustly predict the robot's state distribution under motion uncertainty. We then introduce an efficient, hierarchical verification method that combines parallelizable physics simulations with sum-of-squares (SOS) programming as a filter for fine-grained, formal certification of collision risk. This method is embedded within a Model Predictive Path Integral (MPPI) controller that uniquely utilizes binary collision information from SOS decomposition to improve its policy. The effectiveness of the proposed framework is validated on two typical robot manipulators through extensive simulations and real-world experiments, including a challenging human-robot collaboration scenario, demonstrating sim-to-real transfer of the learned model and its ability to generate safe and efficient trajectories in complex, uncertain settings.
Beyond Retention: Orchestrating Structural Safety and Plasticity in Continual Learning for LLMs
Jan 26, 2026Continual learning in Large Language Models (LLMs) faces the critical challenge of balancing stability (retaining old knowledge) and plasticity (learning new tasks). While Experience Replay (ER) is a standard countermeasure against catastrophic forgetting, its impact across diverse capabilities remains underexplored. In this work, we uncover a critical dichotomy in ER's behavior: while it induces positive backward transfer on robust, unstructured tasks (e.g., boosting performance on previous NLP classification tasks through repeated rehearsal), it causes severe negative transfer on fragile, structured domains like code generation (e.g., a significant relative drop in coding accuracy). This reveals that ER trades structural integrity for broad consolidation. To address this dilemma, we propose \textbf{Orthogonal Subspace Wake-up (OSW)}. OSW identifies essential parameter subspaces of previous tasks via a brief "wake-up" phase and enforces orthogonal updates for new tasks, providing a mathematically grounded "safety guarantee" for established knowledge structures. Empirical results across a diverse four-task sequence demonstrate that OSW uniquely succeeds in preserving fragile coding abilities where Replay fails, while simultaneously maintaining high plasticity for novel tasks. Our findings emphasize the necessity of evaluating structural safety alongside average retention in LLM continual learning.
Online Time-Informed Kinodynamic Motion Planning of Nonlinear Systems
Jul 03, 2024



Sampling-based kinodynamic motion planners (SKMPs) are powerful in finding collision-free trajectories for high-dimensional systems under differential constraints. Time-informed set (TIS) can provide the heuristic search domain to accelerate their convergence to the time-optimal solution. However, existing TIS approximation methods suffer from the curse of dimensionality, computational burden, and limited system applicable scope, e.g., linear and polynomial nonlinear systems. To overcome these problems, we propose a method by leveraging deep learning technology, Koopman operator theory, and random set theory. Specifically, we propose a Deep Invertible Koopman operator with control U model named DIKU to predict states forward and backward over a long horizon by modifying the auxiliary network with an invertible neural network. A sampling-based approach, ASKU, performing reachability analysis for the DIKU is developed to approximate the TIS of nonlinear control systems online. Furthermore, we design an online time-informed SKMP using a direct sampling technique to draw uniform random samples in the TIS. Simulation experiment results demonstrate that our method outperforms other existing works, approximating TIS in near real-time and achieving superior planning performance in several time-optimal kinodynamic motion planning problems.
NR-RRT: Neural Risk-Aware Near-Optimal Path Planning in Uncertain Nonconvex Environments
May 14, 2022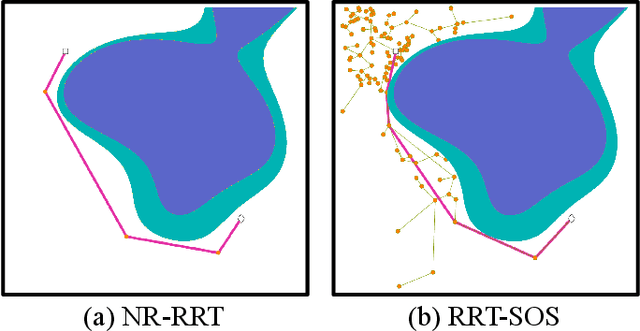

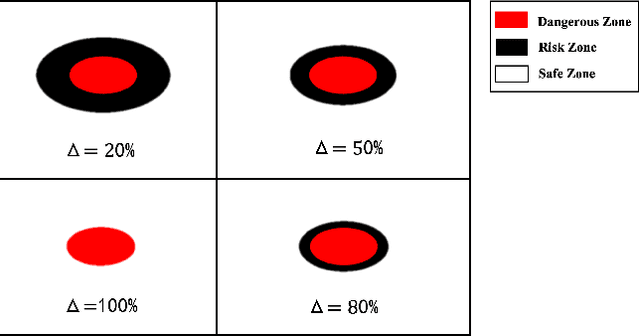
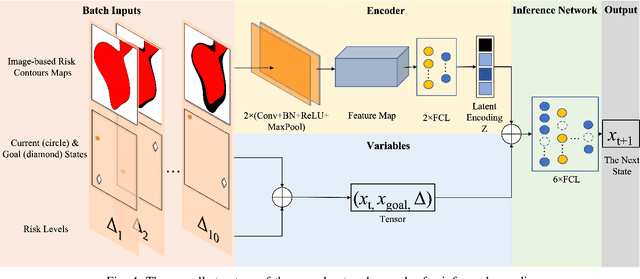
Balancing the trade-off between safety and efficiency is of significant importance for path planning under uncertainty. Many risk-aware path planners have been developed to explicitly limit the probability of collision to an acceptable bound in uncertain environments. However, convex obstacles or Gaussian uncertainties are usually assumed to make the problem tractable in the existing method. These assumptions limit the generalization and application of path planners in real-world implementations. In this article, we propose to apply deep learning methods to the sampling-based planner, developing a novel risk bounded near-optimal path planning algorithm named neural risk-aware RRT (NR-RRT). Specifically, a deterministic risk contours map is maintained by perceiving the probabilistic nonconvex obstacles, and a neural network sampler is proposed to predict the next most-promising safe state. Furthermore, the recursive divide-and-conquer planning and bidirectional search strategies are used to accelerate the convergence to a near-optimal solution with guaranteed bounded risk. Worst-case theoretical guarantees can also be proven owing to a standby safety guaranteed planner utilizing a uniform sampling distribution. Simulation experiments demonstrate that the proposed algorithm outperforms the state-of-the-art remarkably for finding risk bounded low-cost paths in seen and unseen environments with uncertainty and nonconvex constraints.
Relevant Region Sampling Strategy with Adaptive Heuristic Estimation for Asymptotically Optimal Motion Planning
Oct 31, 2021
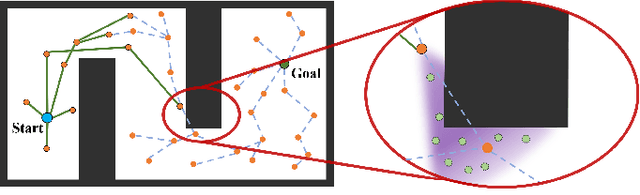
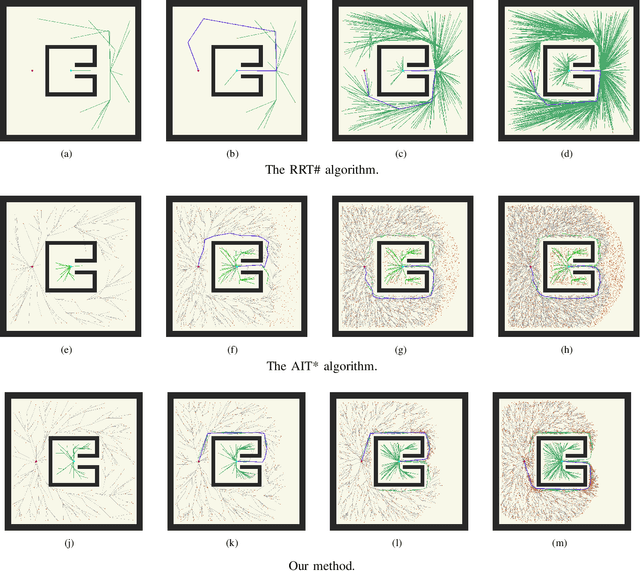
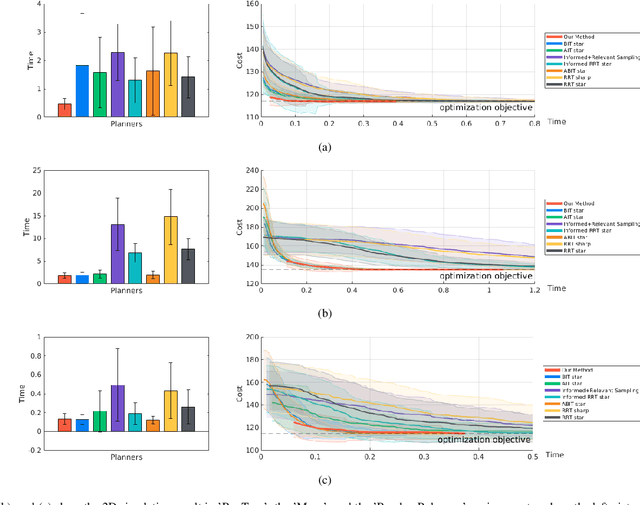
The sampling-based motion planning algorithms can solve the motion planning problem in high-dimensional state space efficiently. This article presents a novel approach to sample in the promising region and reduce planning time remarkably. The RRT# defines the Relevant Region according to the cost-to-come provided by the optimal forward-searching tree; however, it takes the cumulative cost of a direct connection between the current state and the goal state as the cost-to-go. We propose a batch sampling method that samples in the refined Relevant Region, which is defined according to the optimal cost-to-come and the adaptive cost-to-go. In our method, the cost-to-come and the cost-to-go of a specific vertex are estimated by the valid optimal forward-searching tree and the lazy reverse-searching tree, respectively. New samples are generated with a direct sampling method, which can take advantage of the heuristic estimation result. We carry on several simulations in both SE(2) and SE(3) state spaces to validate the effectiveness of our method. Simulation results demonstrate that the proposed algorithm can find a better initial solution and consumes less planning time than related work.
Hierarchical Policy for Non-prehensile Multi-object Rearrangement with Deep Reinforcement Learning and Monte Carlo Tree Search
Sep 18, 2021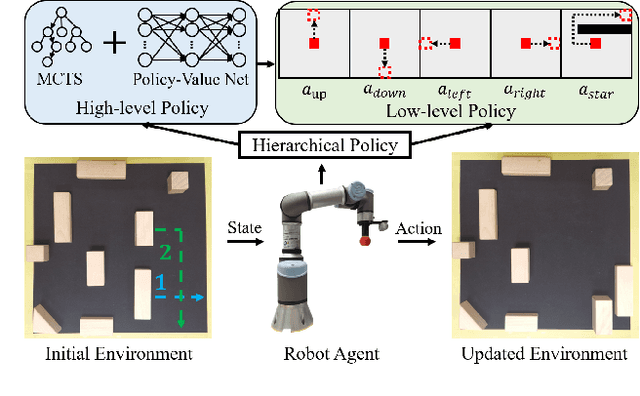
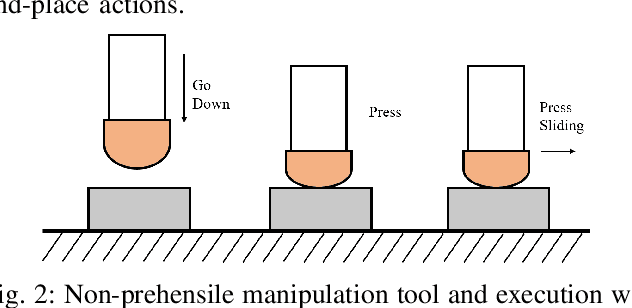
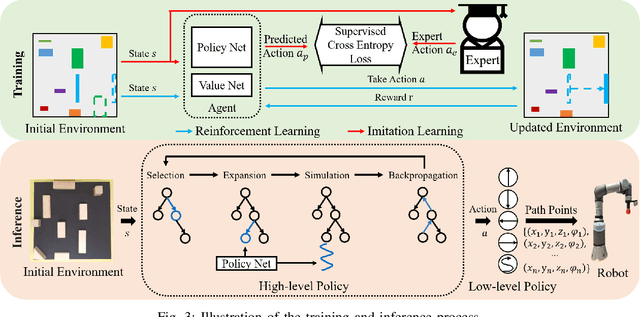

Non-prehensile multi-object rearrangement is a robotic task of planning feasible paths and transferring multiple objects to their predefined target poses without grasping. It needs to consider how each object reaches the target and the order of object movement, which significantly deepens the complexity of the problem. To address these challenges, we propose a hierarchical policy to divide and conquer for non-prehensile multi-object rearrangement. In the high-level policy, guided by a designed policy network, the Monte Carlo Tree Search efficiently searches for the optimal rearrangement sequence among multiple objects, which benefits from imitation and reinforcement. In the low-level policy, the robot plans the paths according to the order of path primitives and manipulates the objects to approach the goal poses one by one. We verify through experiments that the proposed method can achieve a higher success rate, fewer steps, and shorter path length compared with the state-of-the-art.