 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Recall of Software Lessons Learned for Software Project Managers
Oct 11, 2021
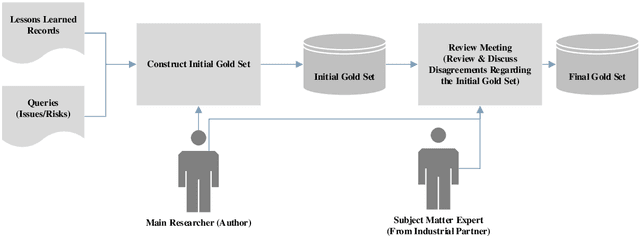

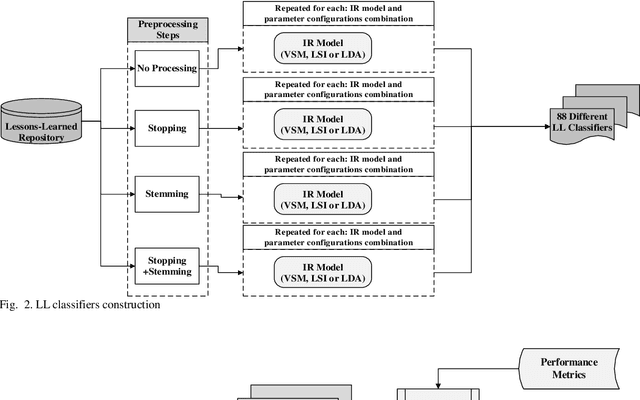
Lessons learned (LL) records constitute the software organization memory of successes and failures. LL are recorded within the organization repository for future reference to optimize planning, gain experience, and elevate market competitiveness. However, manually searching this repository is a daunting task, so it is often disregarded. This can lead to the repetition of previous mistakes or even missing potential opportunities. This, in turn, can negatively affect the profitability and competitiveness of organizations. We aim to present a novel solution that provides an automatic process to recall relevant LL and to push those LL to project managers. This will dramatically save the time and effort of manually searching the unstructured LL repositories and thus encourage the LL exploitation. We exploit existing project artifacts to build the LL search queries on-the-fly in order to bypass the tedious manual searching. An empirical case study is conducted to build the automatic LL recall solution and evaluate its effectiveness. The study employs three of the most popular information retrieval models to construct the solution. Furthermore, a real-world dataset of 212 LL records from 30 different software projects is used for validation. Top-k and MAP well-known accuracy metrics are used as well. Our case study results confirm the effectiveness of the automatic LL recall solution. Also, the results prove the success of using existing project artifacts to dynamically build the search query string. This is supported by a discerning accuracy of about 70% achieved in the case of top-k. The automatic LL recall solution is valid with high accuracy. It will eliminate the effort needed to manually search the LL repository. Therefore, this will positively encourage project managers to reuse the available LL knowledge, which will avoid old pitfalls and unleash hidden business opportunities.
Neural Network Models for Stock Selection Based on Fundamental Analysis
Jun 12, 2019
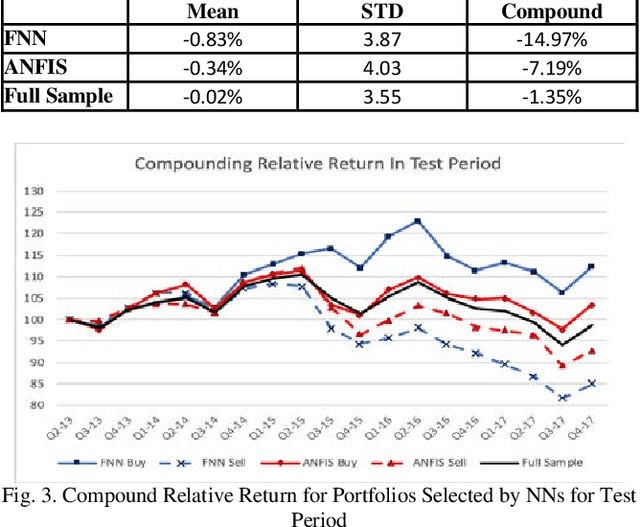
Application of neural network architectures for financial prediction has been actively studied in recent years. This paper presents a comparative study that investigates and compares feed-forward neural network (FNN) and adaptive neural fuzzy inference system (ANFIS) on stock prediction using fundamental financial ratios. The study is designed to evaluate the performance of each architecture based on the relative return of the selected portfolios with respect to the benchmark stock index. The results show that both architectures possess the ability to separate winners and losers from a sample universe of stocks, and the selected portfolios outperform the benchmark. Our study argues that FNN shows superior performance over ANFIS.
* 4 pages
HouseExpo: A Large-scale 2D Indoor Layout Dataset for Learning-based Algorithms on Mobile Robots
Mar 23, 2019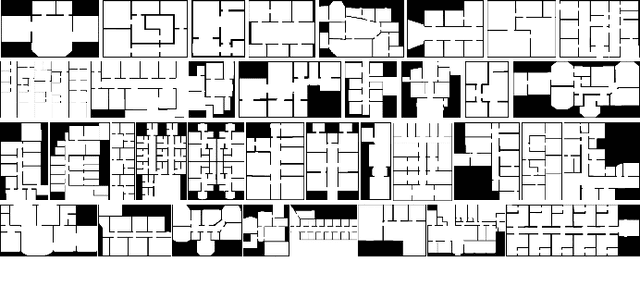
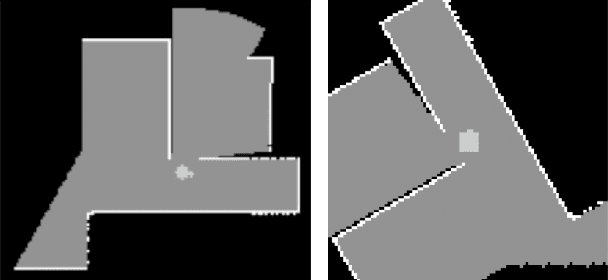
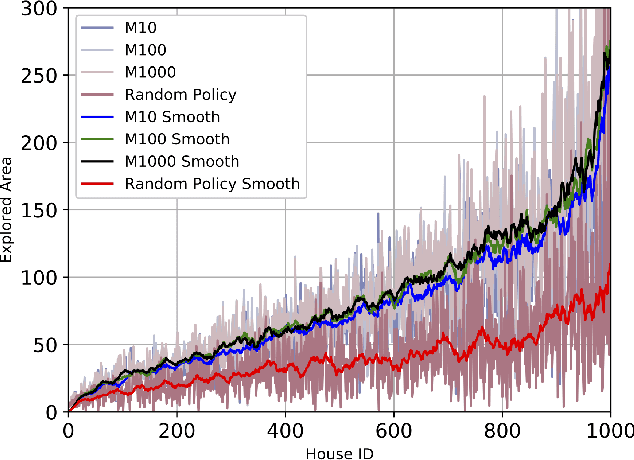
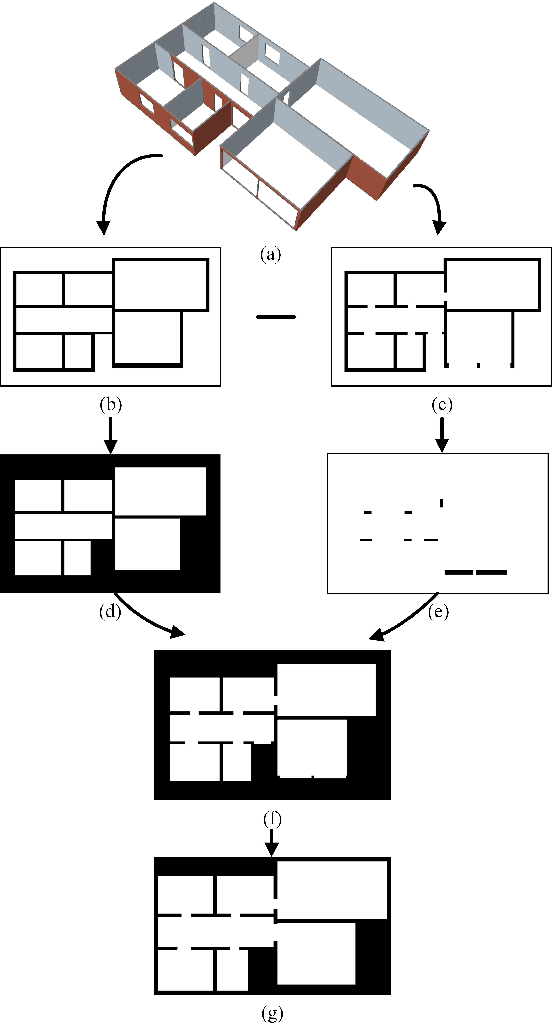
As one of the most promising areas, mobile robots draw much attention these years. Current work in this field is often evaluated in a few manually designed scenarios, due to the lack of a common experimental platform. Meanwhile, with the recent development of deep learning techniques, some researchers attempt to apply learning-based methods to mobile robot tasks, which requires a substantial amount of data. To satisfy the underlying demand, in this paper we build HouseExpo, a large-scale indoor layout dataset containing 35,357 2D floor plans including 252,550 rooms in total. Together we develop Pseudo-SLAM, a lightweight and efficient simulation platform to accelerate the data generation procedure, thereby speeding up the training process. In our experiments, we build models to tackle obstacle avoidance and autonomous exploration from a learning perspective in simulation as well as real-world experiments to verify the effectiveness of our simulator and dataset. All the data and codes are available online and we hope HouseExpo and Pseudo-SLAM can feed the need for data and benefits the whole community.
Enhancing Use Case Points Estimation Method Using Soft Computing Techniques
Dec 04, 2016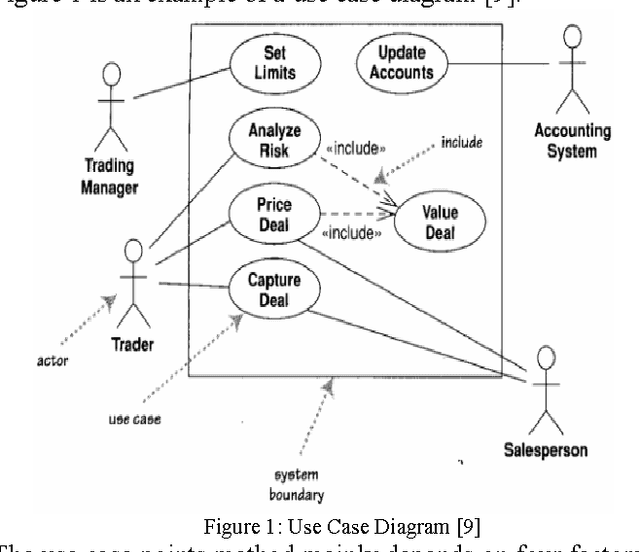


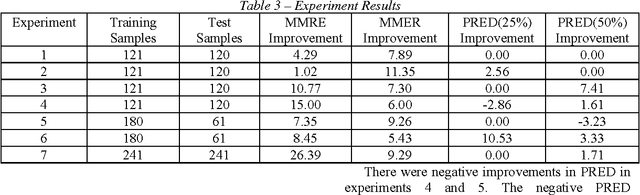
Software estimation is a crucial task in software engineering. Software estimation encompasses cost, effort, schedule, and size. The importance of software estimation becomes critical in the early stages of the software life cycle when the details of software have not been revealed yet. Several commercial and non-commercial tools exist to estimate software in the early stages. Most software effort estimation methods require software size as one of the important metric inputs and consequently, software size estimation in the early stages becomes essential. One of the approaches that has been used for about two decades in the early size and effort estimation is called use case points. Use case points method relies on the use case diagram to estimate the size and effort of software projects. Although the use case points method has been widely used, it has some limitations that might adversely affect the accuracy of estimation. This paper presents some techniques using fuzzy logic and neural networks to improve the accuracy of the use case points method. Results showed that an improvement up to 22% can be obtained using the proposed approach.
A Hybrid Intelligent Model for Software Cost Estimation
Dec 01, 2015

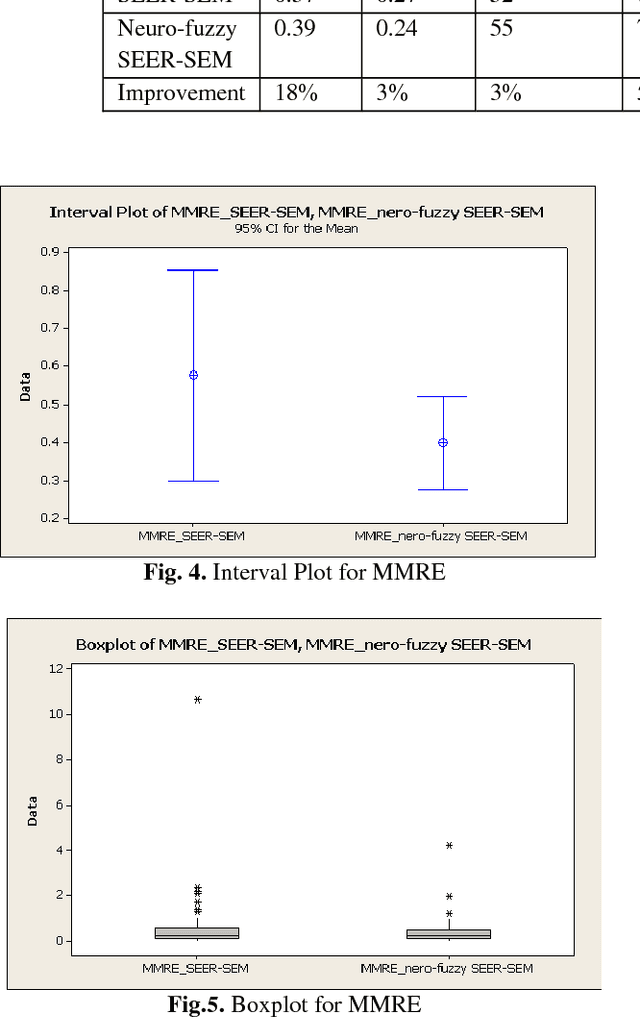
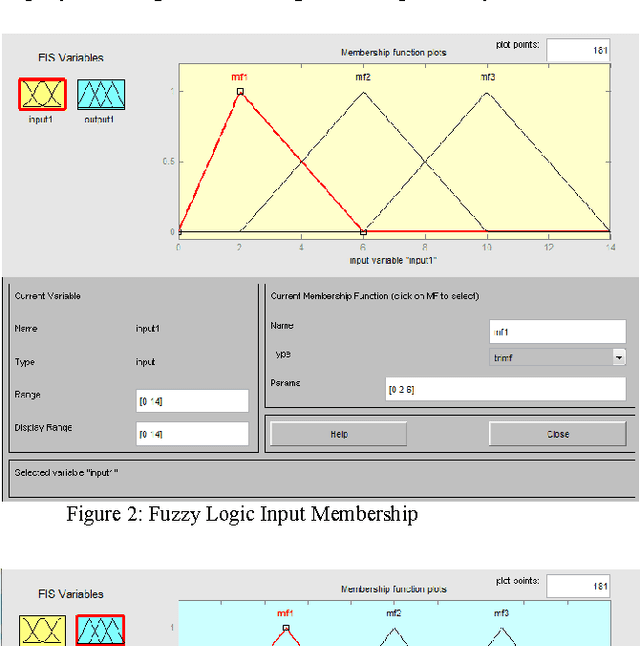
Accurate software development effort estimation is critical to the success of software projects. Although many techniques and algorithmic models have been developed and implemented by practitioners, accurate software development effort prediction is still a challenging endeavor in the field of software engineering, especially in handling uncertain and imprecise inputs and collinear characteristics. In this paper, a hybrid in-telligent model combining a neural network model integrated with fuzzy model (neuro-fuzzy model) has been used to improve the accuracy of estimating software cost. The performance of the proposed model is assessed by designing and conducting evaluation with published project and industrial data. Results have shown that the proposed model demonstrates the ability of improving the estimation accuracy by 18% based on the Mean Magnitude of Relative Error (MMRE) criterion.
A Comparison Between Decision Trees and Decision Tree Forest Models for Software Development Effort Estimation
Aug 28, 2015
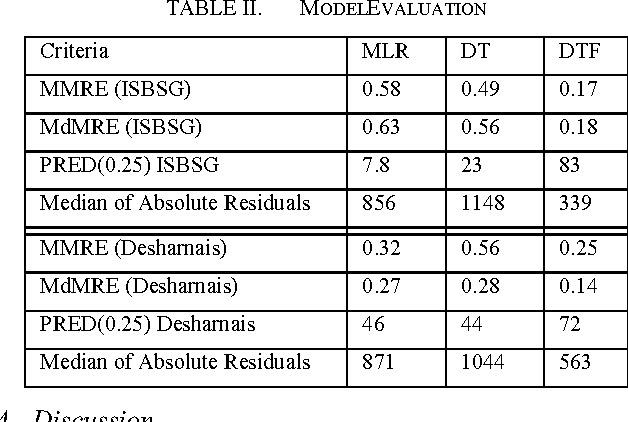
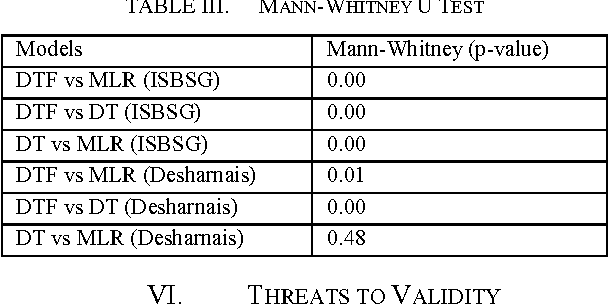
Accurate software effort estimation has been a challenge for many software practitioners and project managers. Underestimation leads to disruption in the projects estimated cost and delivery. On the other hand, overestimation causes outbidding and financial losses in business. Many software estimation models exist; however, none have been proven to be the best in all situations. In this paper, a decision tree forest (DTF) model is compared to a traditional decision tree (DT) model, as well as a multiple linear regression model (MLR). The evaluation was conducted using ISBSG and Desharnais industrial datasets. Results show that the DTF model is competitive and can be used as an alternative in software effort prediction.
A Neuro-Fuzzy Method to Improving Backfiring Conversion Ratios
Aug 25, 2015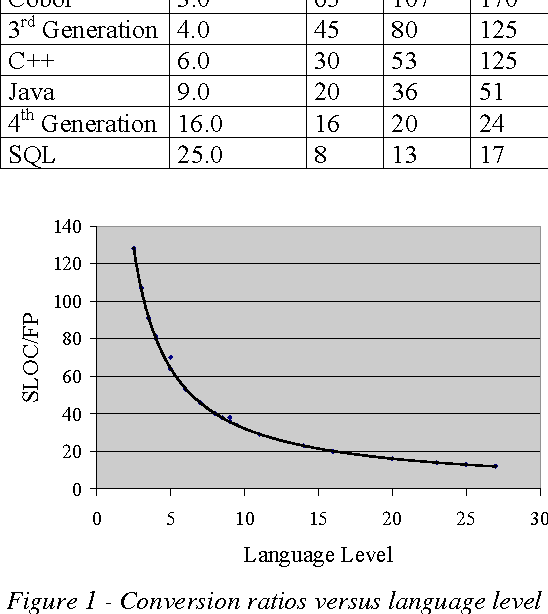

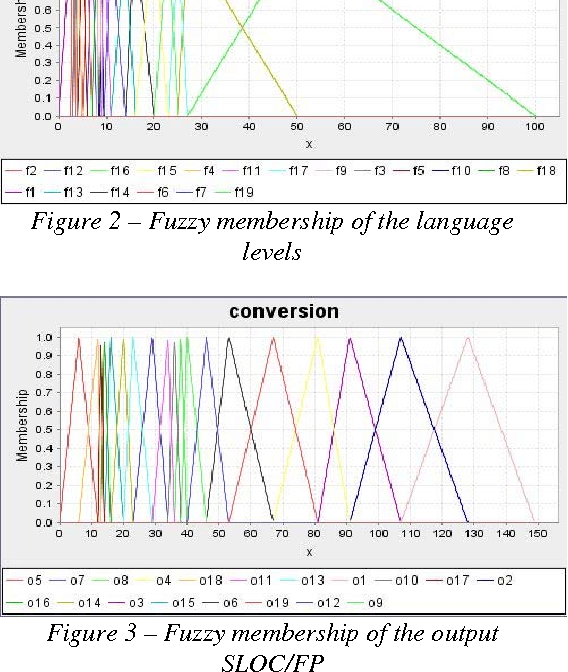
Software project estimation is crucial aspect in delivering software on time and on budget. Software size is an important metric in determining the effort, cost, and productivity. Today, source lines of code and function point are the most used sizing metrics. Backfiring is a well-known technique for converting between function points and source lines of code. However when backfiring is used, there is a high margin of error. This study introduces a method to improve the accuracy of backfiring. Intelligent systems have been used in software prediction models to improve performance over traditional techniques. For this reason, a hybrid Neuro-Fuzzy is used because it takes advantages of the neural networks learning and fuzzy logic human-like reasoning. This paper describes an improved backfiring technique which uses Neuro-Fuzzy and compares the new method against the default conversion ratios currently used by software practitioners.
Neuro-Fuzzy Algorithmic Models and Tools for Estimation
Jul 31, 2015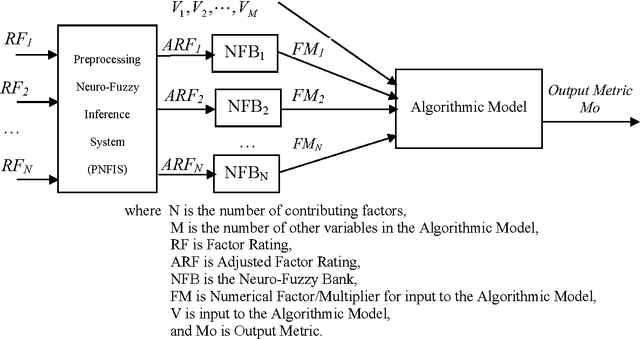

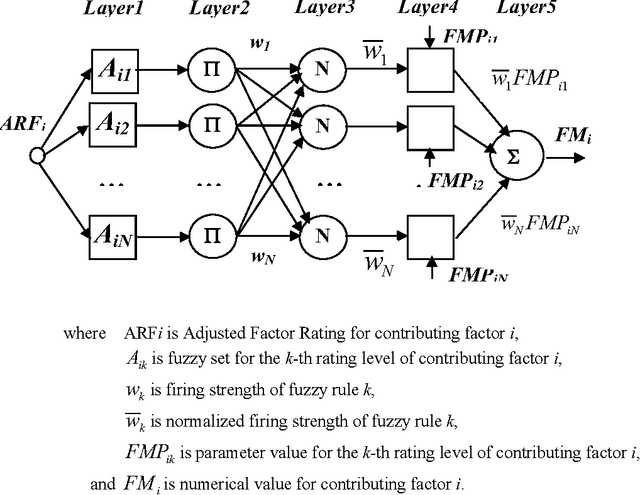
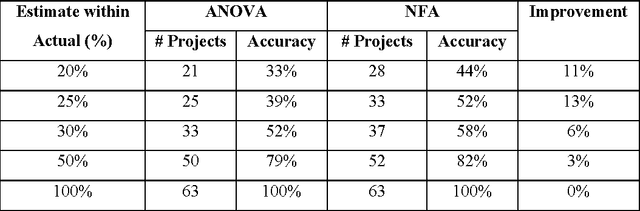
Accurate estimation such as cost estimation, quality estimation and risk analysis is a major issue in management. We propose a patent pending soft computing framework to tackle this challenging problem. Our generic framework is independent of the nature and type of estimation. It consists of neural network, fuzzy logic, and an algorithmic estimation model. We made use of the Constructive Cost Model (COCOMO), Analysis of Variance (ANOVA), and Function Point Analysis as the algorithmic models and validated the accuracy of the Neuro-Fuzzy Algorithmic (NFA) Model in software cost estimation using industrial project data. Our model produces more accurate estimation than using an algorithmic model alone. We also discuss the prototypes of our tools that implement the NFA Model. We conclude with our roadmap and direction to enrich the model in tackling different estimation challenges.