 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Graph Predictive Coding for Reliable OOD Generalization
Feb 22, 2026Graphs provide a powerful basis for modeling Web-based relational data, with expressive GNNs to support the effective learning in dynamic web environments. However, real-world deployment is hindered by pervasive out-of-distribution (OOD) shifts, where evolving user activity and changing content semantics alter feature distributions and labeling criteria. These shifts often lead to unstable or overconfident predictions, undermining the trustworthiness required for Web4Good applications. Achieving reliable OOD generalization demands principled and interpretable uncertainty estimation; however, existing methods are largely post-hoc, insensitive to distribution shifts, and unable to explain where uncertainty arises especially in high-stakes settings. To address these limitations, we introduce SpIking GrapH predicTive coding (SIGHT), an uncertainty-aware plug-in graph learning module for reliable OOD Generalization. SIGHT performs iterative, error-driven correction over spiking graph states, enabling models to expose internal mismatch signals that reveal where predictions become unreliable. Across multiple graph benchmarks and diverse OOD scenarios, SIGHT consistently enhances predictive accuracy, uncertainty estimation, and interpretability when integrated with GNNs.
Two-Layer Reinforcement Learning-Assisted Joint Beamforming and Trajectory Optimization for Multi-UAV Downlink Communications
Jan 19, 2026Unmanned aerial vehicles (UAVs) are pivotal for future 6G non-terrestrial networks, yet their high mobility creates a complex coupled optimization problem for beamforming and trajectory design. Existing numerical methods suffer from prohibitive latency, while standard deep learning often ignores dynamic interference topology, limiting scalability. To address these issues, this paper proposes a hierarchically decoupled framework synergizing graph neural networks (GNNs) with multi-agent reinforcement learning. Specifically, on the short timescale, we develop a topology-aware GNN beamformer by incorporating GraphNorm. By modeling the dynamic UAV-user association as a time-varying heterogeneous graph, this method explicitly extracts interference patterns to achieve sub-millisecond inference. On the long timescale, trajectory planning is modeled as a decentralized partially observable Markov decision process and solved via the multi-agent proximal policy optimization algorithm under the centralized training with decentralized execution paradigm, facilitating cooperative behaviors. Extensive simulation results demonstrate that the proposed framework significantly outperforms state-of-the-art optimization heuristics and deep learning baselines in terms of system sum rate, convergence speed, and generalization capability.
FairGE: Fairness-Aware Graph Encoding in Incomplete Social Networks
Jan 14, 2026Graph Transformers (GTs) are increasingly applied to social network analysis, yet their deployment is often constrained by fairness concerns. This issue is particularly critical in incomplete social networks, where sensitive attributes are frequently missing due to privacy and ethical restrictions. Existing solutions commonly generate these incomplete attributes, which may introduce additional biases and further compromise user privacy. To address this challenge, FairGE (Fair Graph Encoding) is introduced as a fairness-aware framework for GTs in incomplete social networks. Instead of generating sensitive attributes, FairGE encodes fairness directly through spectral graph theory. By leveraging the principal eigenvector to represent structural information and padding incomplete sensitive attributes with zeros to maintain independence, FairGE ensures fairness without data reconstruction. Theoretical analysis demonstrates that the method suppresses the influence of non-principal spectral components, thereby enhancing fairness. Extensive experiments on seven real-world social network datasets confirm that FairGE achieves at least a 16% improvement in both statistical parity and equality of opportunity compared with state-of-the-art baselines. The source code is shown in https://github.com/LuoRenqiang/FairGE.
When to Invoke: Refining LLM Fairness with Toxicity Assessment
Jan 14, 2026Large Language Models (LLMs) are increasingly used for toxicity assessment in online moderation systems, where fairness across demographic groups is essential for equitable treatment. However, LLMs often produce inconsistent toxicity judgements for subtle expressions, particularly those involving implicit hate speech, revealing underlying biases that are difficult to correct through standard training. This raises a key question that existing approaches often overlook: when should corrective mechanisms be invoked to ensure fair and reliable assessments? To address this, we propose FairToT, an inference-time framework that enhances LLM fairness through prompt-guided toxicity assessment. FairToT identifies cases where demographic-related variation is likely to occur and determines when additional assessment should be applied. In addition, we introduce two interpretable fairness indicators that detect such cases and improve inference consistency without modifying model parameters. Experiments on benchmark datasets show that FairToT reduces group-level disparities while maintaining stable and reliable toxicity predictions, demonstrating that inference-time refinement offers an effective and practical approach for fairness improvement in LLM-based toxicity assessment systems. The source code can be found at https://aisuko.github.io/fair-tot/.
When to Trust: A Causality-Aware Calibration Framework for Accurate Knowledge Graph Retrieval-Augmented Generation
Jan 14, 2026Knowledge Graph Retrieval-Augmented Generation (KG-RAG) extends the RAG paradigm by incorporating structured knowledge from knowledge graphs, enabling Large Language Models (LLMs) to perform more precise and explainable reasoning. While KG-RAG improves factual accuracy in complex tasks, existing KG-RAG models are often severely overconfident, producing high-confidence predictions even when retrieved sub-graphs are incomplete or unreliable, which raises concerns for deployment in high-stakes domains. To address this issue, we propose Ca2KG, a Causality-aware Calibration framework for KG-RAG. Ca2KG integrates counterfactual prompting, which exposes retrieval-dependent uncertainties in knowledge quality and reasoning reliability, with a panel-based re-scoring mechanism that stabilises predictions across interventions. Extensive experiments on two complex QA datasets demonstrate that Ca2KG consistently improves calibration while maintaining or even enhancing predictive accuracy.
Debiasing Large Language Models via Adaptive Causal Prompting with Sketch-of-Thought
Jan 13, 2026Despite notable advancements in prompting methods for Large Language Models (LLMs), such as Chain-of-Thought (CoT), existing strategies still suffer from excessive token usage and limited generalisability across diverse reasoning tasks. To address these limitations, we propose an Adaptive Causal Prompting with Sketch-of-Thought (ACPS) framework, which leverages structural causal models to infer the causal effect of a query on its answer and adaptively select an appropriate intervention (i.e., standard front-door and conditional front-door adjustments). This design enables generalisable causal reasoning across heterogeneous tasks without task-specific retraining. By replacing verbose CoT with concise Sketch-of-Thought, ACPS enables efficient reasoning that significantly reduces token usage and inference cost. Extensive experiments on multiple reasoning benchmarks and LLMs demonstrate that ACPS consistently outperforms existing prompting baselines in terms of accuracy, robustness, and computational efficiency.
BrainMAP: Multimodal Graph Learning For Efficient Brain Disease Localization
Jun 12, 2025Recent years have seen a surge in research focused on leveraging graph learning techniques to detect neurodegenerative diseases. However, existing graph-based approaches typically lack the ability to localize and extract the specific brain regions driving neurodegenerative pathology within the full connectome. Additionally, recent works on multimodal brain graph models often suffer from high computational complexity, limiting their practical use in resource-constrained devices. In this study, we present BrainMAP, a novel multimodal graph learning framework designed for precise and computationally efficient identification of brain regions affected by neurodegenerative diseases. First, BrainMAP utilizes an atlas-driven filtering approach guided by the AAL atlas to pinpoint and extract critical brain subgraphs. Unlike recent state-of-the-art methods, which model the entire brain network, BrainMAP achieves more than 50% reduction in computational overhead by concentrating on disease-relevant subgraphs. Second, we employ an advanced multimodal fusion process comprising cross-node attention to align functional magnetic resonance imaging (fMRI) and diffusion tensor imaging (DTI) data, coupled with an adaptive gating mechanism to blend and integrate these modalities dynamically. Experimental results demonstrate that BrainMAP outperforms state-of-the-art methods in computational efficiency, without compromising predictive accuracy.
Cultural Bias Matters: A Cross-Cultural Benchmark Dataset and Sentiment-Enriched Model for Understanding Multimodal Metaphors
Jun 08, 2025
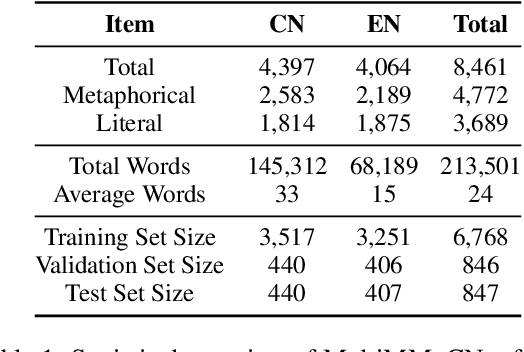

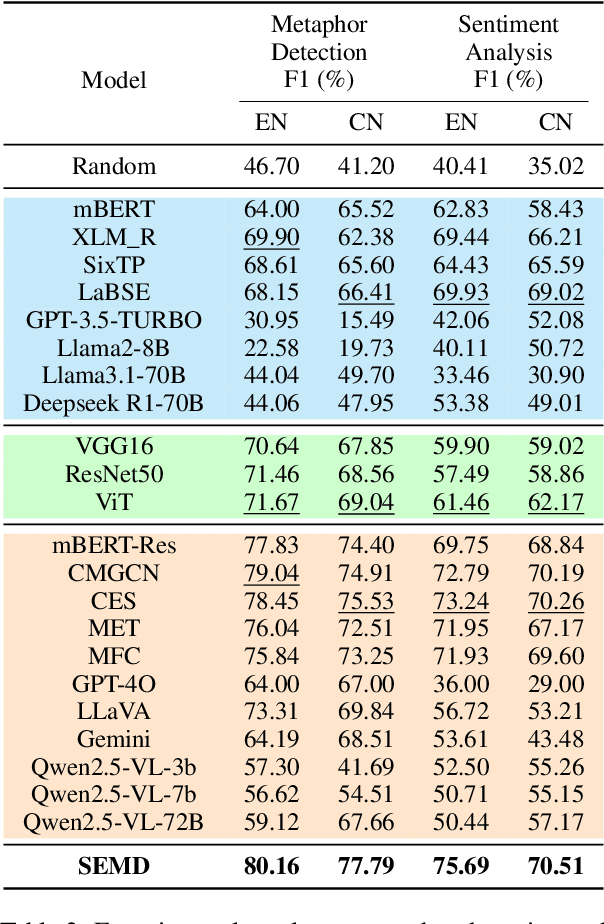
Metaphors are pervasive in communication, making them crucial for natural language processing (NLP). Previous research on automatic metaphor processing predominantly relies on training data consisting of English samples, which often reflect Western European or North American biases. This cultural skew can lead to an overestimation of model performance and contributions to NLP progress. However, the impact of cultural bias on metaphor processing, particularly in multimodal contexts, remains largely unexplored. To address this gap, we introduce MultiMM, a Multicultural Multimodal Metaphor dataset designed for cross-cultural studies of metaphor in Chinese and English. MultiMM consists of 8,461 text-image advertisement pairs, each accompanied by fine-grained annotations, providing a deeper understanding of multimodal metaphors beyond a single cultural domain. Additionally, we propose Sentiment-Enriched Metaphor Detection (SEMD), a baseline model that integrates sentiment embeddings to enhance metaphor comprehension across cultural backgrounds. Experimental results validate the effectiveness of SEMD on metaphor detection and sentiment analysis tasks. We hope this work increases awareness of cultural bias in NLP research and contributes to the development of fairer and more inclusive language models. Our dataset and code are available at https://github.com/DUTIR-YSQ/MultiMM.
HALO: Half Life-Based Outdated Fact Filtering in Temporal Knowledge Graphs
May 12, 2025Outdated facts in temporal knowledge graphs (TKGs) result from exceeding the expiration date of facts, which negatively impact reasoning performance on TKGs. However, existing reasoning methods primarily focus on positive importance of historical facts, neglecting adverse effects of outdated facts. Besides, training on these outdated facts yields extra computational cost. To address these challenges, we propose an outdated fact filtering framework named HALO, which quantifies the temporal validity of historical facts by exploring the half-life theory to filter outdated facts in TKGs. HALO consists of three modules: the temporal fact attention module, the dynamic relation-aware encoder module, and the outdated fact filtering module. Firstly, the temporal fact attention module captures the evolution of historical facts over time to identify relevant facts. Secondly, the dynamic relation-aware encoder module is designed for efficiently predicting the half life of each fact. Finally, we construct a time decay function based on the half-life theory to quantify the temporal validity of facts and filter outdated facts. Experimental results show that HALO outperforms the state-of-the-art TKG reasoning methods on three public datasets, demonstrating its effectiveness in detecting and filtering outdated facts (Codes are available at https://github.com/yushuowiki/K-Half/tree/main ).
EAGLE: Contrastive Learning for Efficient Graph Anomaly Detection
May 12, 2025



Graph anomaly detection is a popular and vital task in various real-world scenarios, which has been studied for several decades. Recently, many studies extending deep learning-based methods have shown preferable performance on graph anomaly detection. However, existing methods are lack of efficiency that is definitely necessary for embedded devices. Towards this end, we propose an Efficient Anomaly detection model on heterogeneous Graphs via contrastive LEarning (EAGLE) by contrasting abnormal nodes with normal ones in terms of their distances to the local context. The proposed method first samples instance pairs on meta path-level for contrastive learning. Then, a graph autoencoder-based model is applied to learn informative node embeddings in an unsupervised way, which will be further combined with the discriminator to predict the anomaly scores of nodes. Experimental results show that EAGLE outperforms the state-of-the-art methods on three heterogeneous network datasets.