 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClusterUCB: Efficient Gradient-Based Data Selection for Targeted Fine-Tuning of LLMs
Jun 12, 2025Gradient-based data influence approximation has been leveraged to select useful data samples in the supervised fine-tuning of large language models. However, the computation of gradients throughout the fine-tuning process requires too many resources to be feasible in practice. In this paper, we propose an efficient gradient-based data selection framework with clustering and a modified Upper Confidence Bound (UCB) algorithm. Based on the intuition that data samples with similar gradient features will have similar influences, we first perform clustering on the training data pool. Then, we frame the inter-cluster data selection as a constrained computing budget allocation problem and consider it a multi-armed bandit problem. A modified UCB algorithm is leveraged to solve this problem. Specifically, during the iterative sampling process, historical data influence information is recorded to directly estimate the distributions of each cluster, and a cold start is adopted to balance exploration and exploitation. Experimental results on various benchmarks show that our proposed framework, ClusterUCB, can achieve comparable results to the original gradient-based data selection methods while greatly reducing computing consumption.
TimeRAG: BOOSTING LLM Time Series Forecasting via Retrieval-Augmented Generation
Dec 21, 2024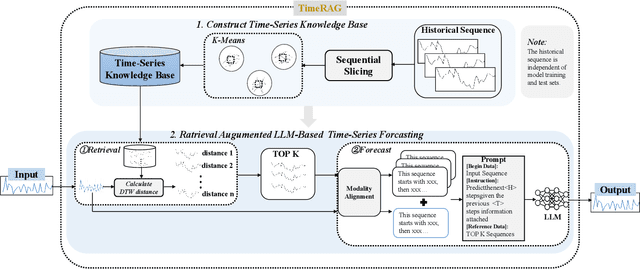
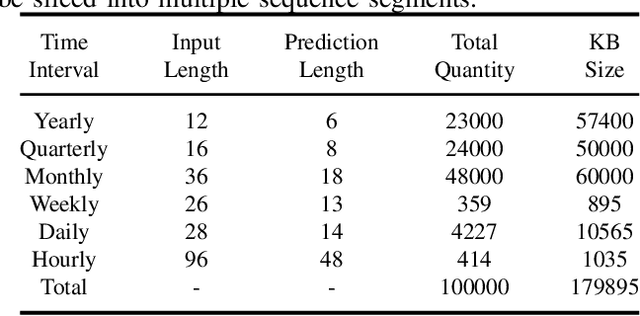
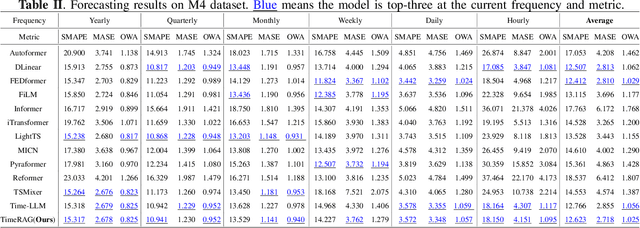
Although the rise of large language models (LLMs) has introduced new opportunities for time series forecasting, existing LLM-based solutions require excessive training and exhibit limited transferability. In view of these challenges, we propose TimeRAG, a framework that incorporates Retrieval-Augmented Generation (RAG) into time series forecasting LLMs, which constructs a time series knowledge base from historical sequences, retrieves reference sequences from the knowledge base that exhibit similar patterns to the query sequence measured by Dynamic Time Warping (DTW), and combines these reference sequences and the prediction query as a textual prompt to the time series forecasting LLM. Experiments on datasets from various domains show that the integration of RAG improved the prediction accuracy of the original model by 2.97% on average.
Context-Driven Index Trimming: A Data Quality Perspective to Enhancing Precision of RALMs
Aug 10, 2024



Retrieval-Augmented Large Language Models (RALMs) have made significant strides in enhancing the accuracy of generated responses.However, existing research often overlooks the data quality issues within retrieval results, often caused by inaccurate existing vector-distance-based retrieval methods.We propose to boost the precision of RALMs' answers from a data quality perspective through the Context-Driven Index Trimming (CDIT) framework, where Context Matching Dependencies (CMDs) are employed as logical data quality rules to capture and regulate the consistency between retrieved contexts.Based on the semantic comprehension capabilities of Large Language Models (LLMs), CDIT can effectively identify and discard retrieval results that are inconsistent with the query context and further modify indexes in the database, thereby improving answer quality.Experiments demonstrate on challenging question-answering tasks.Also, the flexibility of CDIT is verified through its compatibility with various language models and indexing methods, which offers a promising approach to bolster RALMs' data quality and retrieval precision jointly.
FutureNet-LOF: Joint Trajectory Prediction and Lane Occupancy Field Prediction with Future Context Encoding
Jun 20, 2024



Most prior motion prediction endeavors in autonomous driving have inadequately encoded future scenarios, leading to predictions that may fail to accurately capture the diverse movements of agents (e.g., vehicles or pedestrians). To address this, we propose FutureNet, which explicitly integrates initially predicted trajectories into the future scenario and further encodes these future contexts to enhance subsequent forecasting. Additionally, most previous motion forecasting works have focused on predicting independent futures for each agent. However, safe and smooth autonomous driving requires accurately predicting the diverse future behaviors of numerous surrounding agents jointly in complex dynamic environments. Given that all agents occupy certain potential travel spaces and possess lane driving priority, we propose Lane Occupancy Field (LOF), a new representation with lane semantics for motion forecasting in autonomous driving. LOF can simultaneously capture the joint probability distribution of all road participants' future spatial-temporal positions. Due to the high compatibility between lane occupancy field prediction and trajectory prediction, we propose a novel network with future context encoding for the joint prediction of these two tasks. Our approach ranks 1st on two large-scale motion forecasting benchmarks: Argoverse 1 and Argoverse 2.
GANet: Goal Area Network for Motion Forecasting
Sep 20, 2022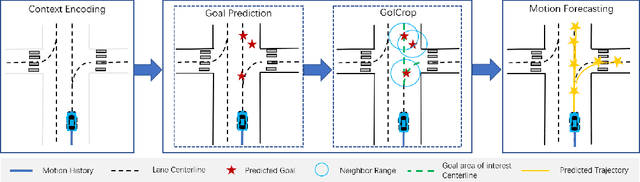
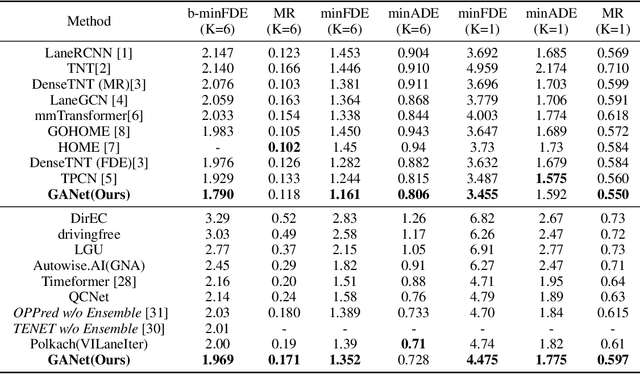
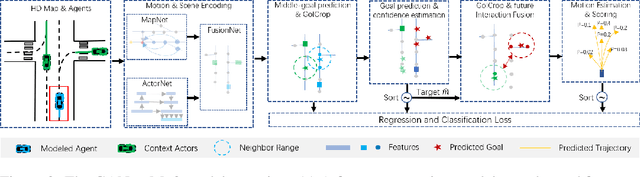
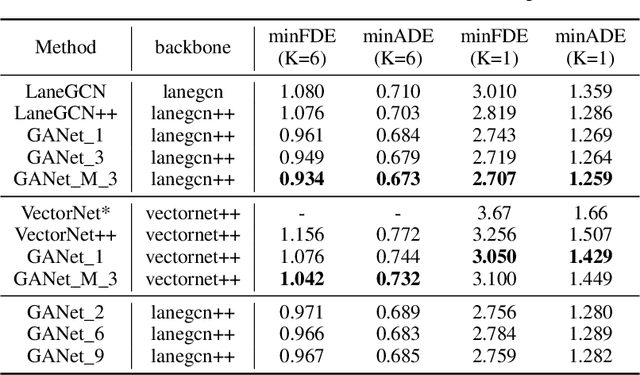
Predicting the future motion of road participants is crucial for autonomous driving but is extremely challenging due to staggering motion uncertainty. Recently, most motion forecasting methods resort to the goal-based strategy, i.e., predicting endpoints of motion trajectories as conditions to regress the entire trajectories, so that the search space of solution can be reduced. However, accurate goal coordinates are hard to predict and evaluate. In addition, the point representation of the destination limits the utilization of a rich road context, leading to inaccurate prediction results in many cases. Goal area, i.e., the possible destination area, rather than goal coordinate, could provide a more soft constraint for searching potential trajectories by involving more tolerance and guidance. In view of this, we propose a new goal area-based framework, named Goal Area Network (GANet), for motion forecasting, which models goal areas rather than exact goal coordinates as preconditions for trajectory prediction, performing more robustly and accurately. Specifically, we propose a GoICrop (Goal Area of Interest) operator to effectively extract semantic lane features in goal areas and model actors' future interactions, which benefits a lot for future trajectory estimations. GANet ranks the 1st on the leaderboard of Argoverse Challenge among all public literature (till the paper submission), and its source codes will be released.
Visual Confusion Label Tree For Image Classification
Jun 05, 2019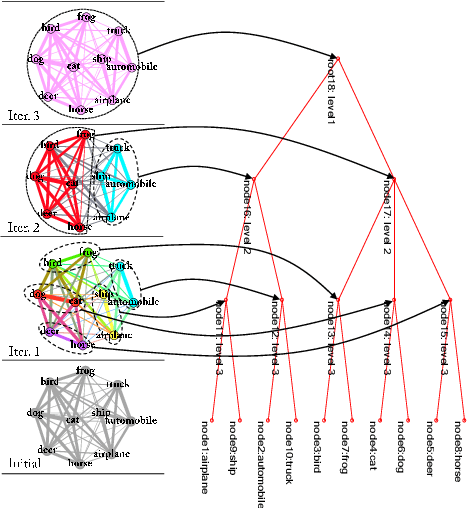
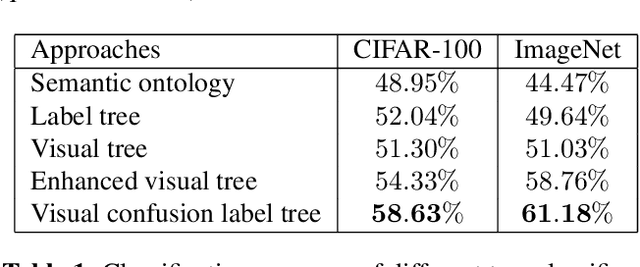
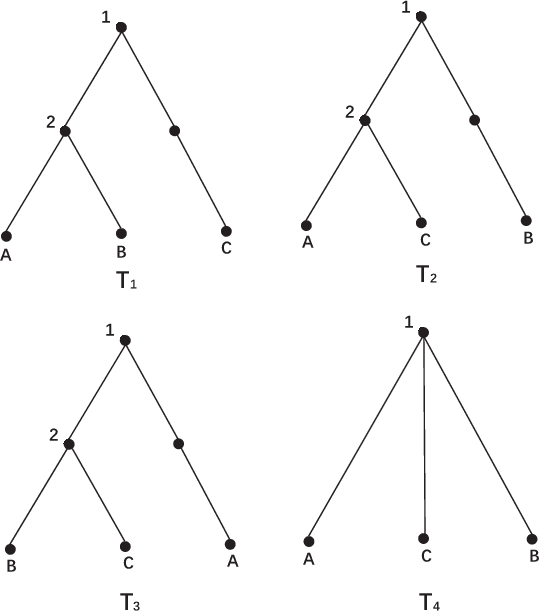

Convolution neural network models are widely used in image classification tasks. However, the running time of such models is so long that it is not the conforming to the strict real-time requirement of mobile devices. In order to optimize models and meet the requirement mentioned above, we propose a method that replaces the fully-connected layers of convolution neural network models with a tree classifier. Specifically, we construct a Visual Confusion Label Tree based on the output of the convolution neural network models, and use a multi-kernel SVM plus classifier with hierarchical constraints to train the tree classifier. Focusing on those confusion subsets instead of the entire set of categories makes the tree classifier more discriminative and the replacement of the fully-connected layers reduces the original running time. Experiments show that our tree classifier obtains a significant improvement over the state-of-the-art tree classifier by 4.3% and 2.4% in terms of top-1 accuracy on CIFAR-100 and ImageNet datasets respectively. Additionally, our method achieves 124x and 115x speedup ratio compared with fully-connected layers on AlexNet and VGG16 without accuracy decline.
* 9 pages, 5 figures, conference
Visual Tree Convolutional Neural Network in Image Classification
Jun 04, 2019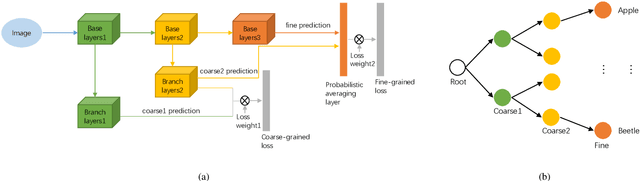
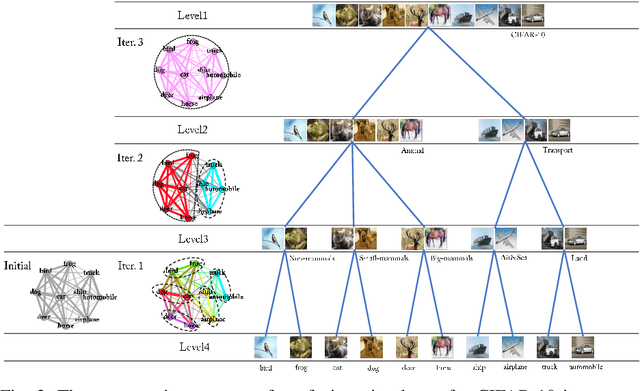
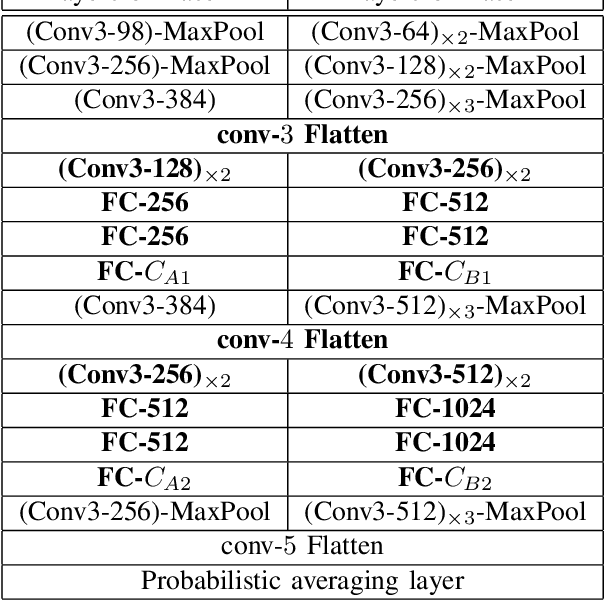
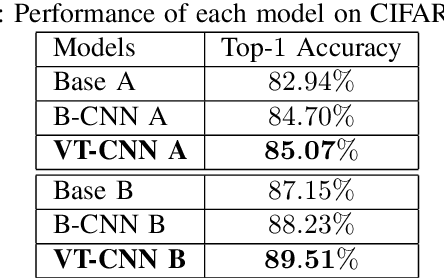
In image classification, Convolutional Neural Network(CNN) models have achieved high performance with the rapid development in deep learning. However, some categories in the image datasets are more difficult to distinguished than others. Improving the classification accuracy on these confused categories is benefit to the overall performance. In this paper, we build a Confusion Visual Tree(CVT) based on the confused semantic level information to identify the confused categories. With the information provided by the CVT, we can lead the CNN training procedure to pay more attention on these confused categories. Therefore, we propose Visual Tree Convolutional Neural Networks(VT-CNN) based on the original deep CNN embedded with our CVT. We evaluate our VT-CNN model on the benchmark datasets CIFAR-10 and CIFAR-100. In our experiments, we build up 3 different VT-CNN models and they obtain improvement over their based CNN models by 1.36%, 0.89% and 0.64%, respectively.
* 7 pages, 2 figures, conference