 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeRAG: BOOSTING LLM Time Series Forecasting via Retrieval-Augmented Generation
Dec 21, 2024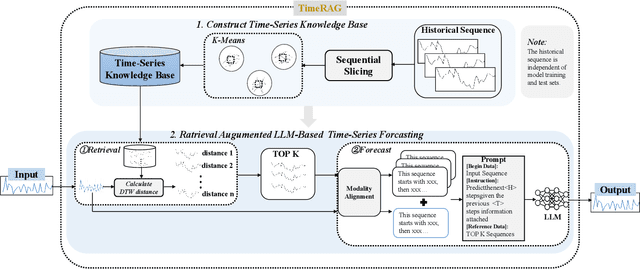
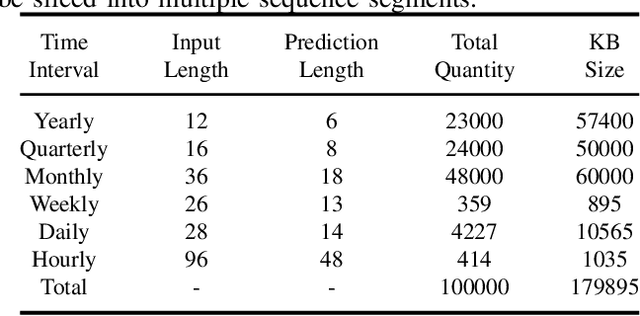
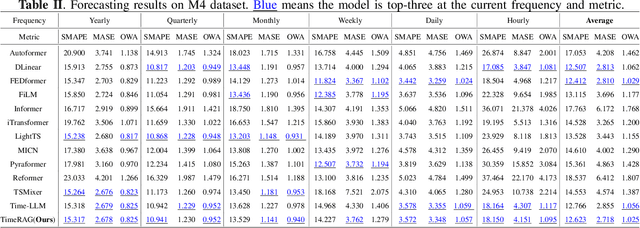
Although the rise of large language models (LLMs) has introduced new opportunities for time series forecasting, existing LLM-based solutions require excessive training and exhibit limited transferability. In view of these challenges, we propose TimeRAG, a framework that incorporates Retrieval-Augmented Generation (RAG) into time series forecasting LLMs, which constructs a time series knowledge base from historical sequences, retrieves reference sequences from the knowledge base that exhibit similar patterns to the query sequence measured by Dynamic Time Warping (DTW), and combines these reference sequences and the prediction query as a textual prompt to the time series forecasting LLM. Experiments on datasets from various domains show that the integration of RAG improved the prediction accuracy of the original model by 2.97% on average.
Self-Evolution Learning for Mixup: Enhance Data Augmentation on Few-Shot Text Classification Tasks
May 22, 2023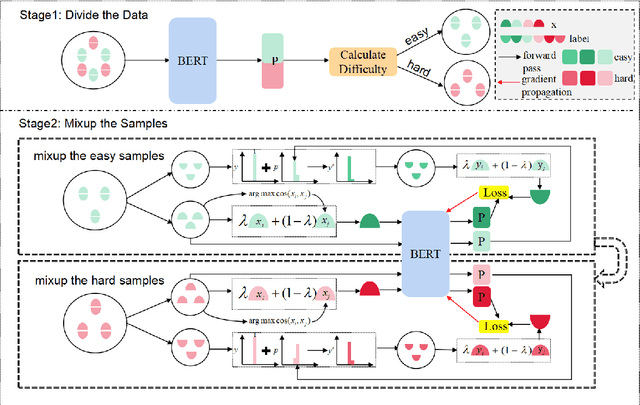
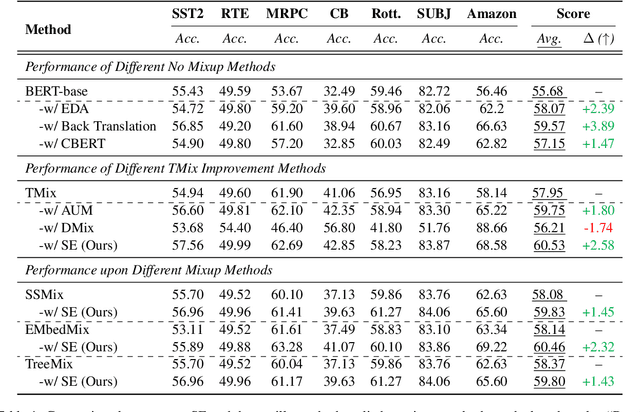
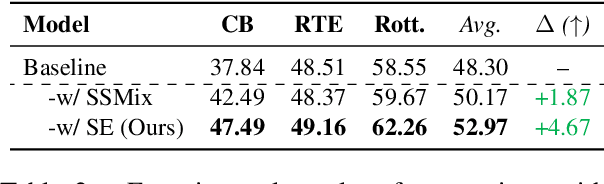
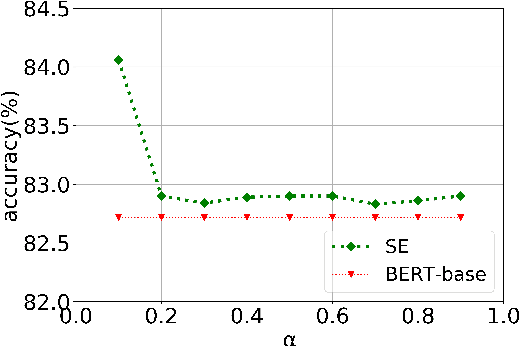
Text classification tasks often encounter few shot scenarios with limited labeled data, and addressing data scarcity is crucial. Data augmentation with mixup has shown to be effective on various text classification tasks. However, most of the mixup methods do not consider the varying degree of learning difficulty in different stages of training and generate new samples with one hot labels, resulting in the model over confidence. In this paper, we propose a self evolution learning (SE) based mixup approach for data augmentation in text classification, which can generate more adaptive and model friendly pesudo samples for the model training. SE focuses on the variation of the model's learning ability. To alleviate the model confidence, we introduce a novel instance specific label smoothing approach, which linearly interpolates the model's output and one hot labels of the original samples to generate new soft for label mixing up. Through experimental analysis, in addition to improving classification accuracy, we demonstrate that SE also enhances the model's generalize ability.