 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evolution Learning for Mixup: Enhance Data Augmentation on Few-Shot Text Classification Tasks
Paper and Code
May 22, 2023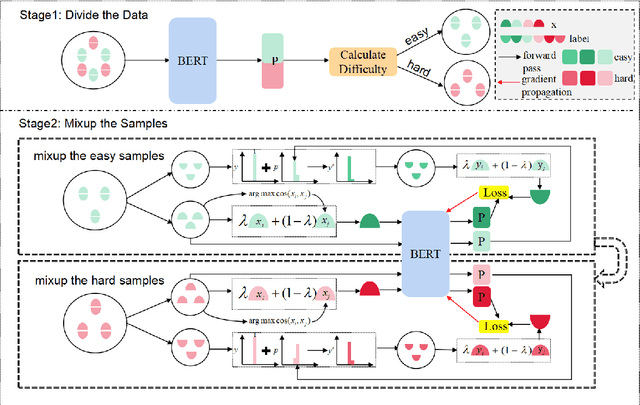
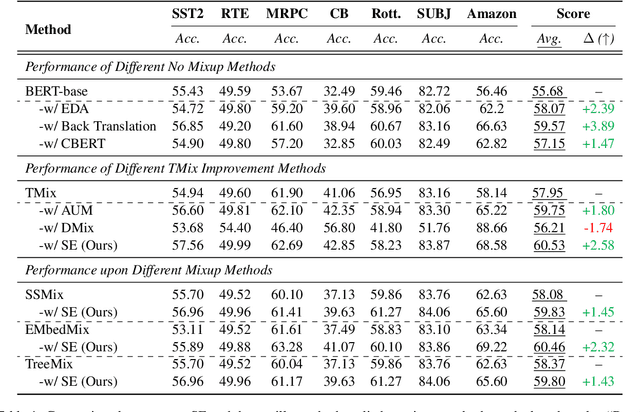
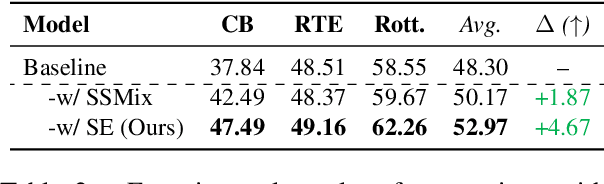
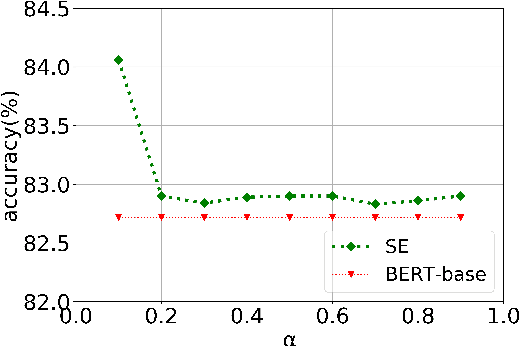
Text classification tasks often encounter few shot scenarios with limited labeled data, and addressing data scarcity is crucial. Data augmentation with mixup has shown to be effective on various text classification tasks. However, most of the mixup methods do not consider the varying degree of learning difficulty in different stages of training and generate new samples with one hot labels, resulting in the model over confidence. In this paper, we propose a self evolution learning (SE) based mixup approach for data augmentation in text classification, which can generate more adaptive and model friendly pesudo samples for the model training. SE focuses on the variation of the model's learning ability. To alleviate the model confidence, we introduce a novel instance specific label smoothing approach, which linearly interpolates the model's output and one hot labels of the original samples to generate new soft for label mixing up. Through experimental analysis, in addition to improving classification accuracy, we demonstrate that SE also enhances the model's generalize ability.