 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Knowledge Conflicts in Domain-specific Data Selection: A Case Study on Medical Instruction-tuning
May 28, 2025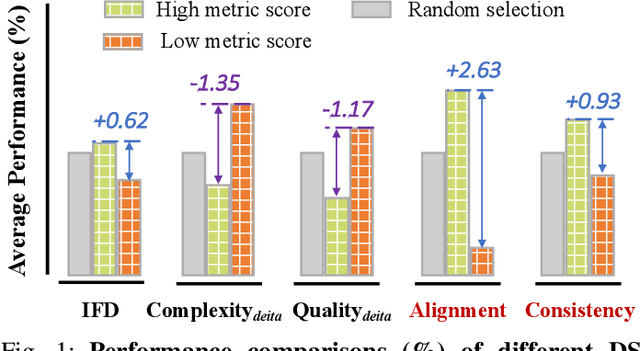
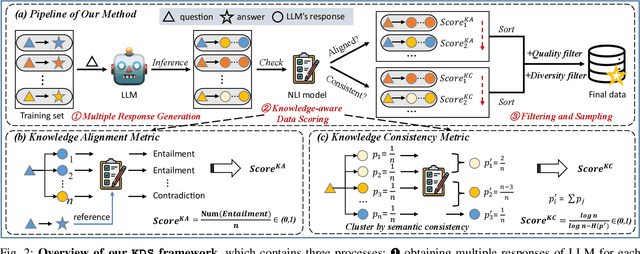
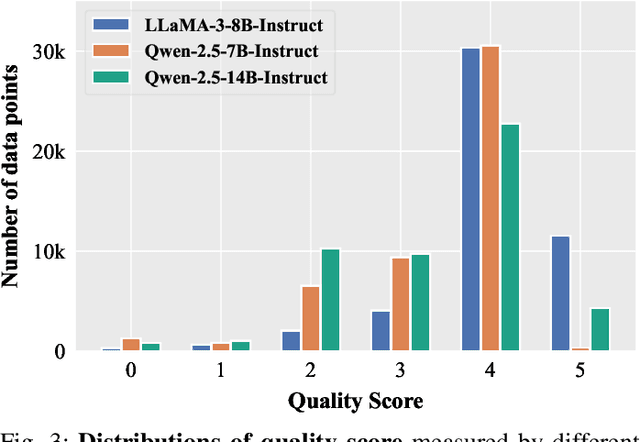
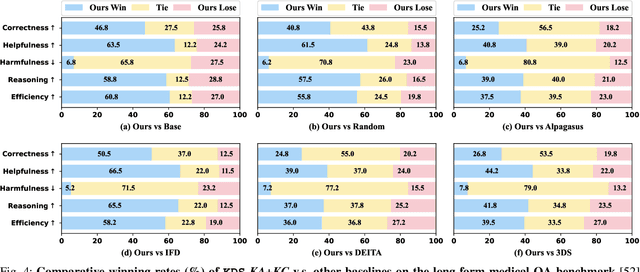
Domain-specific instruction-tuning has become the defacto standard for improving the performance of large language models (LLMs) in specialized applications, e.g., medical question answering. Since the instruction-tuning dataset might contain redundant or low-quality data, data selection (DS) is usually required to maximize the data efficiency. Despite the successes in the general domain, current DS methods often struggle to select the desired data for domain-specific instruction-tuning. One of the main reasons is that they neglect the impact of knowledge conflicts, i.e., the discrepancy between LLMs' pretrained knowledge and context knowledge of instruction data, which could damage LLMs' prior abilities and lead to hallucination. To this end, we propose a simple-yet-effective Knowledge-aware Data Selection (namely KDS) framework to select the domain-specific instruction-tuning data that meets LLMs' actual needs. The core of KDS is to leverage two knowledge-aware metrics for quantitatively measuring knowledge conflicts from two aspects: context-memory knowledge alignment and intra-memory knowledge consistency. By filtering the data with large knowledge conflicts and sampling the high-quality and diverse data, KDS can effectively stimulate the LLMs' abilities and achieve better domain-specific performance. Taking the medical domain as the testbed, we conduct extensive experiments and empirically prove that KDS surpasses the other baselines and brings significant and consistent performance gains among all LLMs. More encouragingly, KDS effectively improves the model generalization and alleviates the hallucination problem.
KaFT: Knowledge-aware Fine-tuning for Boosting LLMs' Domain-specific Question-Answering Performance
May 21, 2025Supervised fine-tuning (SFT) is a common approach to improve the domain-specific question-answering (QA) performance of large language models (LLMs). However, recent literature reveals that due to the conflicts between LLMs' internal knowledge and the context knowledge of training data, vanilla SFT using the full QA training set is usually suboptimal. In this paper, we first design a query diversification strategy for robust conflict detection and then conduct a series of experiments to analyze the impact of knowledge conflict. We find that 1) training samples with varied conflicts contribute differently, where SFT on the data with large conflicts leads to catastrophic performance drops; 2) compared to directly filtering out the conflict data, appropriately applying the conflict data would be more beneficial. Motivated by this, we propose a simple-yet-effective Knowledge-aware Fine-tuning (namely KaFT) approach to effectively boost LLMs' performance. The core of KaFT is to adapt the training weight by assigning different rewards for different training samples according to conflict level. Extensive experiments show that KaFT brings consistent and significant improvements across four LLMs. More analyses prove that KaFT effectively improves the model generalization and alleviates the hallucination.
Learning from Imperfect Data: Towards Efficient Knowledge Distillation of Autoregressive Language Models for Text-to-SQL
Oct 15, 2024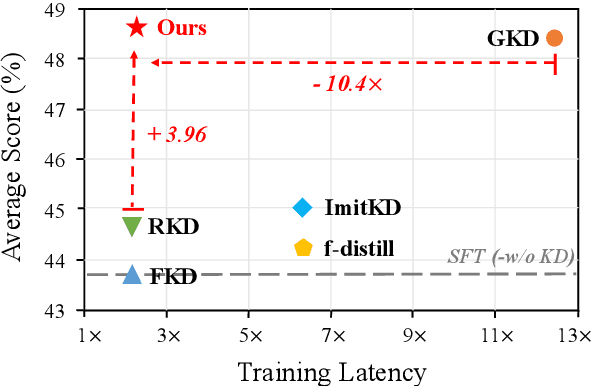
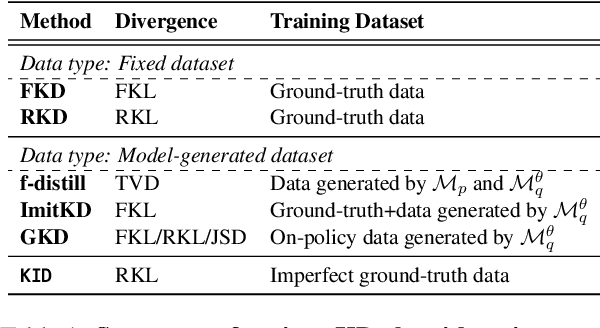
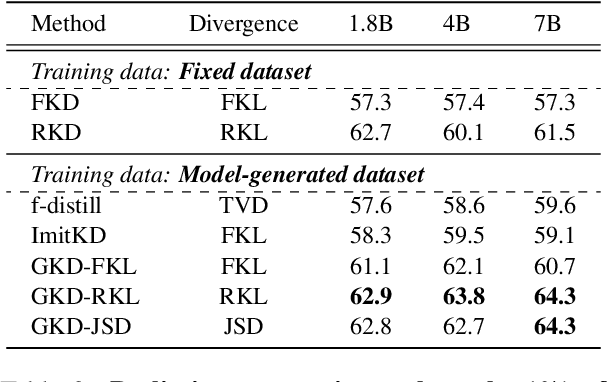
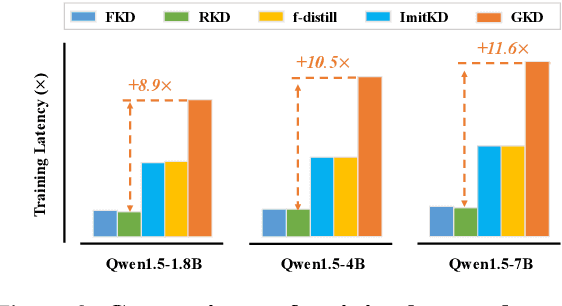
Large Language Models (LLMs) have shown promising performance in text-to-SQL, which involves translating natural language questions into SQL queries. However, current text-to-SQL LLMs are computationally expensive and challenging to deploy in real-world applications, highlighting the importance of compressing them. To achieve this goal, knowledge distillation (KD) is a common approach, which aims to distill the larger teacher model into a smaller student model. While numerous KD methods for autoregressive LLMs have emerged recently, it is still under-explored whether they work well in complex text-to-SQL scenarios. To this end, we conduct a series of analyses and reveal that these KD methods generally fall short in balancing performance and efficiency. In response to this problem, we propose to improve the KD with Imperfect Data, namely KID, which effectively boosts the performance without introducing much training budget. The core of KID is to efficiently mitigate the training-inference mismatch by simulating the cascading effect of inference in the imperfect training data. Extensive experiments on 5 text-to-SQL benchmarks show that, KID can not only achieve consistent and significant performance gains (up to +5.83% average score) across all model types and sizes, but also effectively improve the training efficiency.
Iterative Data Augmentation with Large Language Models for Aspect-based Sentiment Analysis
Jun 29, 2024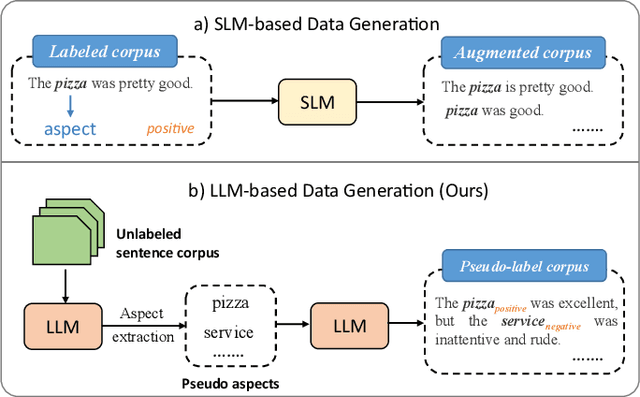
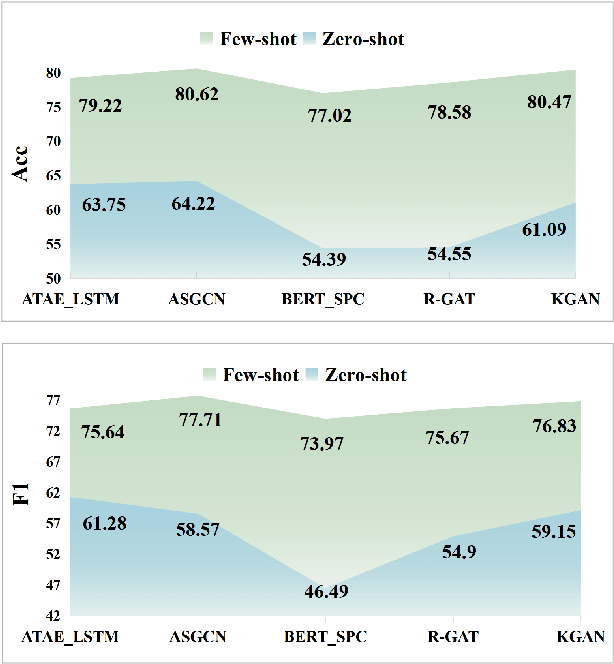
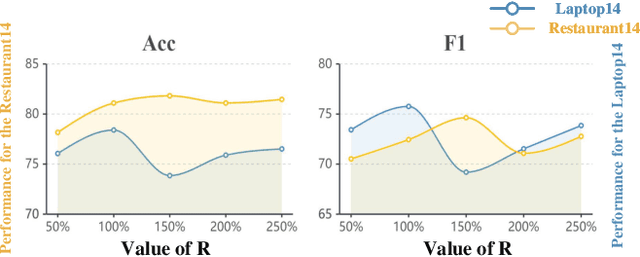
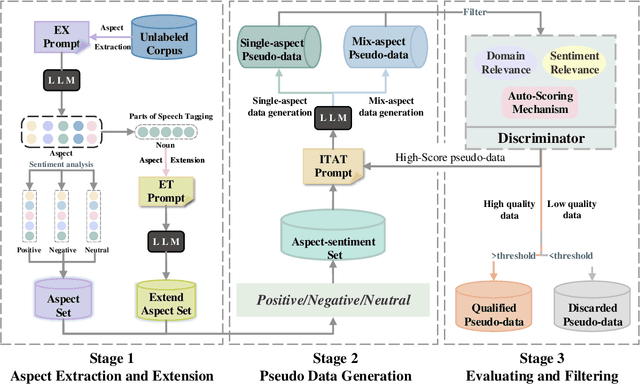
Aspect-based Sentiment Analysis (ABSA) is an important sentiment analysis task, which aims to determine the sentiment polarity towards an aspect in a sentence. Due to the expensive and limited labeled data, data augmentation (DA) has become the standard for improving the performance of ABSA. However, current DA methods usually have some shortcomings: 1) poor fluency and coherence, 2) lack of diversity of generated data, and 3) reliance on some existing labeled data, hindering its applications in real-world scenarios. In response to these problems, we propose a systematic Iterative Data augmentation framework, namely IterD, to boost the performance of ABSA. The core of IterD is to leverage the powerful ability of large language models (LLMs) to iteratively generate more fluent and diverse synthetic labeled data, starting from an unsupervised sentence corpus. Extensive experiments on 4 widely-used ABSA benchmarks show that IterD brings consistent and significant performance gains among 5 baseline ABSA models. More encouragingly, the synthetic data generated by IterD can achieve comparable or even better performance against the manually annotated data.
Achieving >97% on GSM8K: Deeply Understanding the Problems Makes LLMs Better Reasoners
Apr 28, 2024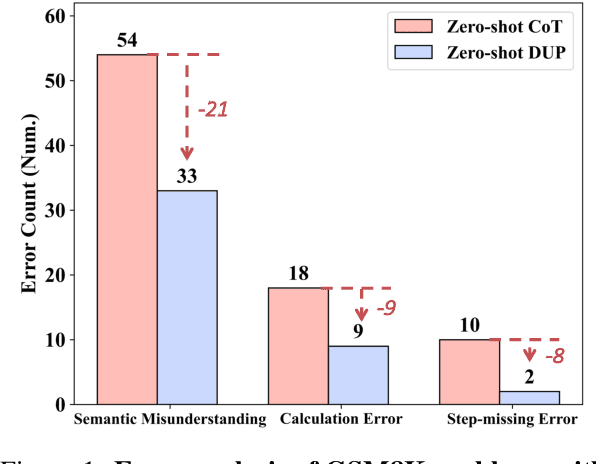

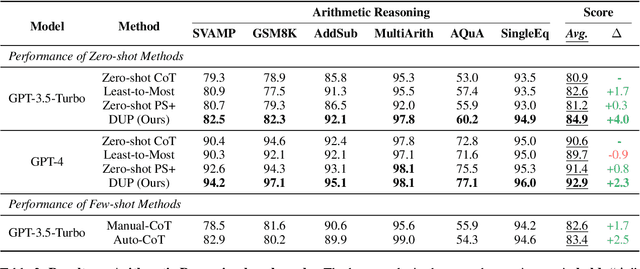
Chain of Thought prompting strategy has enhanced the performance of Large Language Models (LLMs) across various NLP tasks. However, it still has shortcomings when dealing with complex reasoning tasks, including understanding errors, calculation errors and process errors (e.g., missing-step and hallucinations). Subsequently, our in-depth analyses among various error types show that deeply understanding the whole problem is critical in addressing complicated reasoning tasks. Motivated by this, we propose a simple-yet-effective method, namely Deeply Understanding the Problems (DUP), to enhance the LLMs' reasoning abilities. The core of our method is to encourage the LLMs to deeply understand the problems and leverage the key problem-solving information for better reasoning. Extensive experiments on 10 diverse reasoning benchmarks show that our DUP method consistently outperforms the other counterparts by a large margin. More encouragingly, DUP achieves a new SOTA result on the GSM8K benchmark, with an accuracy of 97.1% in a zero-shot setting.
Revisiting Knowledge Distillation for Autoregressive Language Models
Feb 19, 2024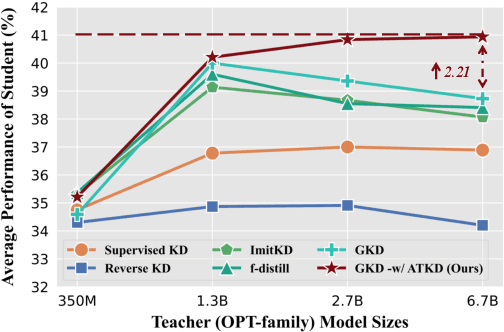
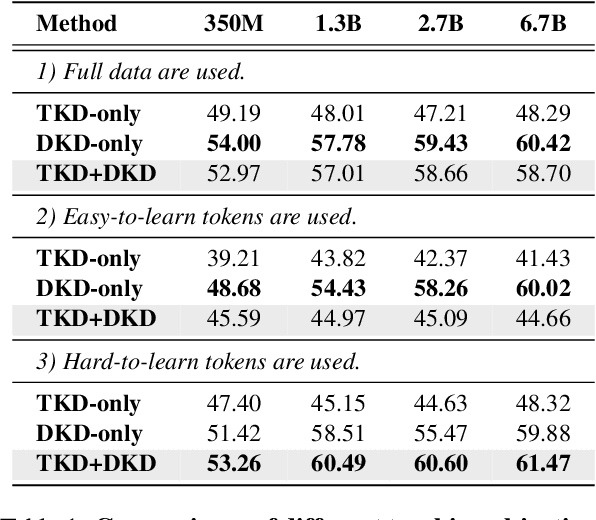
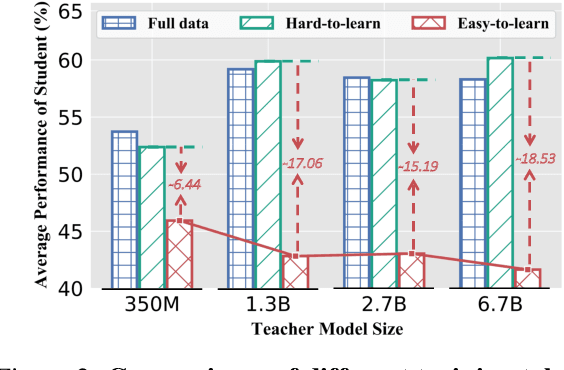
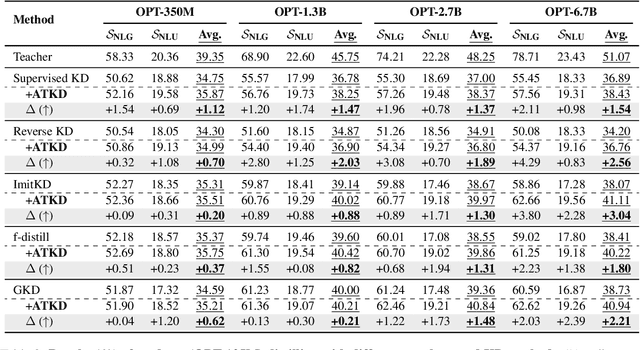
Knowledge distillation (KD) is a common approach to compress a teacher model to reduce its inference cost and memory footprint, by training a smaller student model. However, in the context of autoregressive language models (LMs), we empirically find that larger teacher LMs might dramatically result in a poorer student. In response to this problem, we conduct a series of analyses and reveal that different tokens have different teaching modes, neglecting which will lead to performance degradation. Motivated by this, we propose a simple yet effective adaptive teaching approach (ATKD) to improve the KD. The core of ATKD is to reduce rote learning and make teaching more diverse and flexible. Extensive experiments on 8 LM tasks show that, with the help of ATKD, various baseline KD methods can achieve consistent and significant performance gains (up to +3.04% average score) across all model types and sizes. More encouragingly, ATKD can improve the student model generalization effectively.
ROSE Doesn't Do That: Boosting the Safety of Instruction-Tuned Large Language Models with Reverse Prompt Contrastive Decoding
Feb 19, 2024



With the development of instruction-tuned large language models (LLMs), improving the safety of LLMs has become more critical. However, the current approaches for aligning the LLMs output with expected safety usually require substantial training efforts, e.g., high-quality safety data and expensive computational resources, which are costly and inefficient. To this end, we present reverse prompt contrastive decoding (ROSE), a simple-yet-effective method to directly boost the safety of existing instruction-tuned LLMs without any additional training. The principle of ROSE is to improve the probability of desired safe output via suppressing the undesired output induced by the carefully-designed reverse prompts. Experiments on 6 safety and 2 general-purpose tasks show that, our ROSE not only brings consistent and significant safety improvements (up to +13.8% safety score) upon 5 types of instruction-tuned LLMs, but also benefits the general-purpose ability of LLMs. In-depth analyses explore the underlying mechanism of ROSE, and reveal when and where to use it.
Zero-Shot Sharpness-Aware Quantization for Pre-trained Language Models
Oct 20, 2023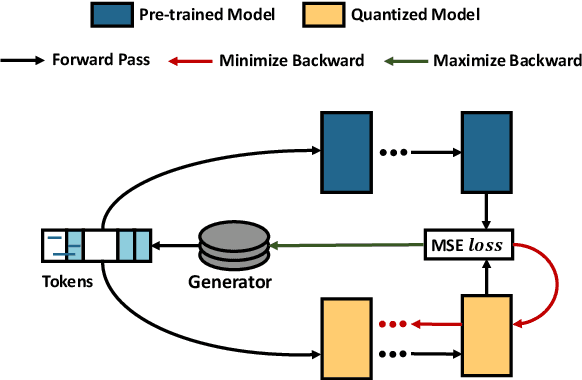
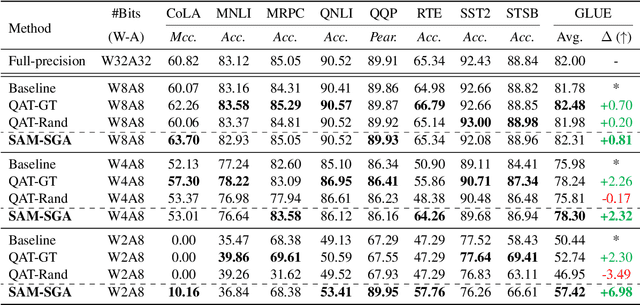
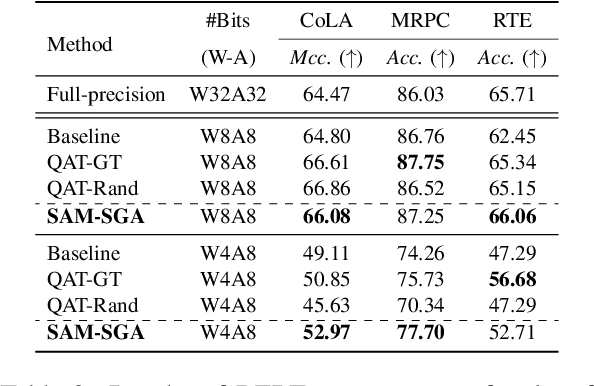
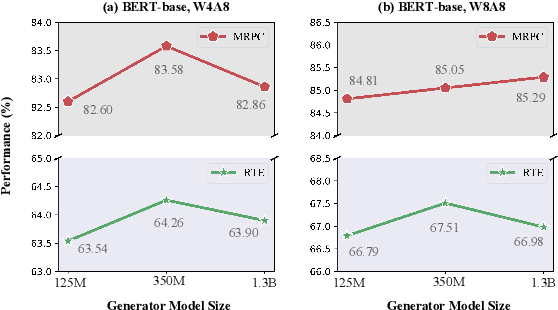
Quantization is a promising approach for reducing memory overhead and accelerating inference, especially in large pre-trained language model (PLM) scenarios. While having no access to original training data due to security and privacy concerns has emerged the demand for zero-shot quantization. Most of the cutting-edge zero-shot quantization methods primarily 1) apply to computer vision tasks, and 2) neglect of overfitting problem in the generative adversarial learning process, leading to sub-optimal performance. Motivated by this, we propose a novel zero-shot sharpness-aware quantization (ZSAQ) framework for the zero-shot quantization of various PLMs. The key algorithm in solving ZSAQ is the SAM-SGA optimization, which aims to improve the quantization accuracy and model generalization via optimizing a minimax problem. We theoretically prove the convergence rate for the minimax optimization problem and this result can be applied to other nonconvex-PL minimax optimization frameworks. Extensive experiments on 11 tasks demonstrate that our method brings consistent and significant performance gains on both discriminative and generative PLMs, i.e., up to +6.98 average score. Furthermore, we empirically validate that our method can effectively improve the model generalization.
Self-Evolution Learning for Discriminative Language Model Pretraining
May 24, 2023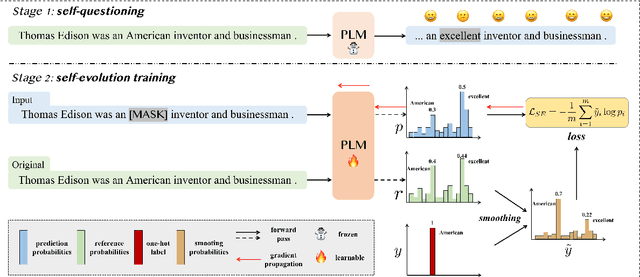
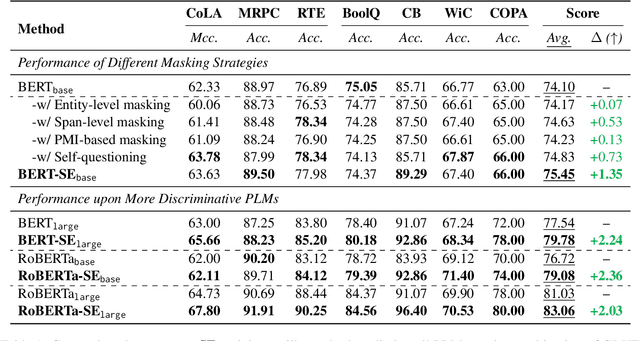
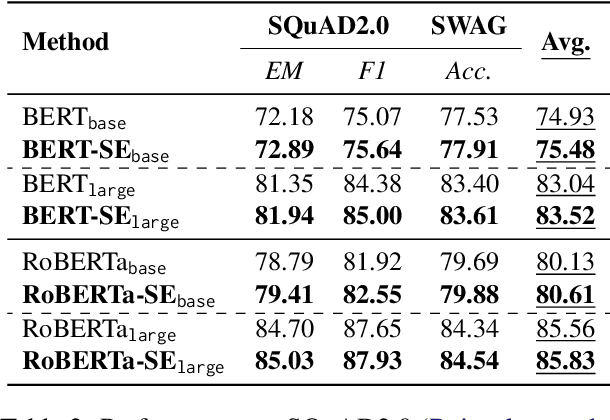
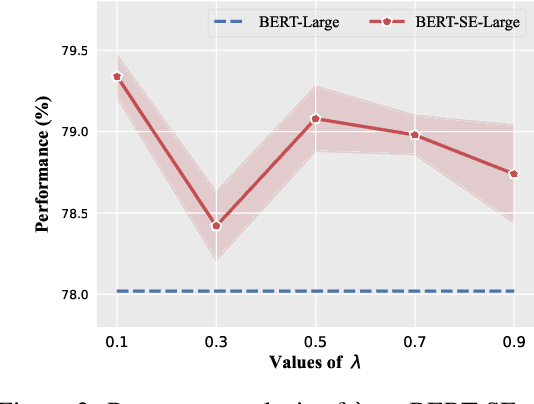
Masked language modeling, widely used in discriminative language model (e.g., BERT) pretraining, commonly adopts a random masking strategy. However, random masking does not consider the importance of the different words in the sentence meaning, where some of them are more worthy to be predicted. Therefore, various masking strategies (e.g., entity-level masking) are proposed, but most of them require expensive prior knowledge and generally train from scratch without reusing existing model weights. In this paper, we present Self-Evolution learning (SE), a simple and effective token masking and learning method to fully and wisely exploit the knowledge from data. SE focuses on learning the informative yet under-explored tokens and adaptively regularizes the training by introducing a novel Token-specific Label Smoothing approach. Experiments on 10 tasks show that our SE brings consistent and significant improvements (+1.43~2.12 average scores) upon different PLMs. In-depth analyses demonstrate that SE improves linguistic knowledge learning and generalization.
Revisiting Token Dropping Strategy in Efficient BERT Pretraining
May 24, 2023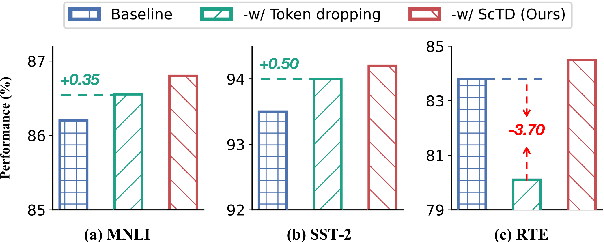
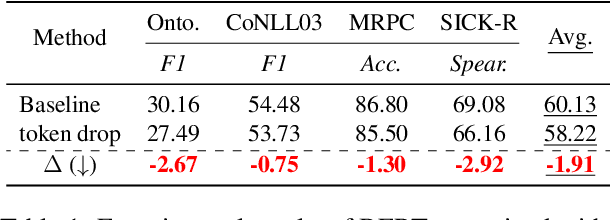
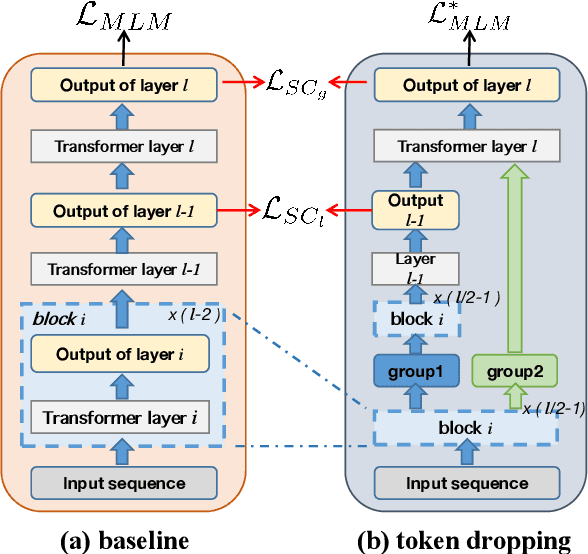
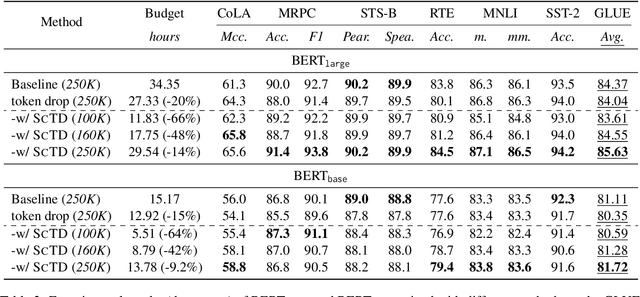
Token dropping is a recently-proposed strategy to speed up the pretraining of masked language models, such as BERT, by skipping the computation of a subset of the input tokens at several middle layers. It can effectively reduce the training time without degrading much performance on downstream tasks. However, we empirically find that token dropping is prone to a semantic loss problem and falls short in handling semantic-intense tasks. Motivated by this, we propose a simple yet effective semantic-consistent learning method (ScTD) to improve the token dropping. ScTD aims to encourage the model to learn how to preserve the semantic information in the representation space. Extensive experiments on 12 tasks show that, with the help of our ScTD, token dropping can achieve consistent and significant performance gains across all task types and model sizes. More encouragingly, ScTD saves up to 57% of pretraining time and brings up to +1.56% average improvement over the vanilla token dropping.