 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Data Augmentation with Large Language Models for Aspect-based Sentiment Analysis
Paper and Code
Jun 29, 2024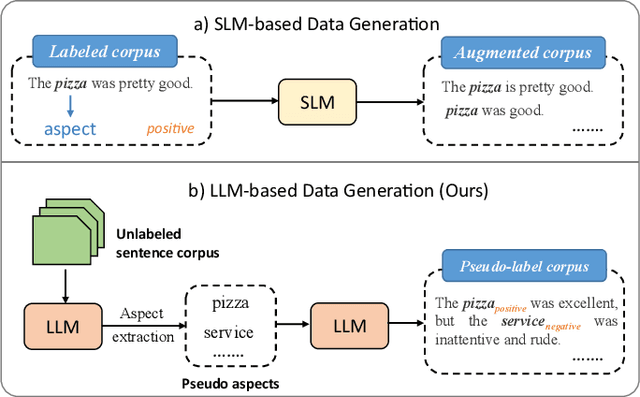
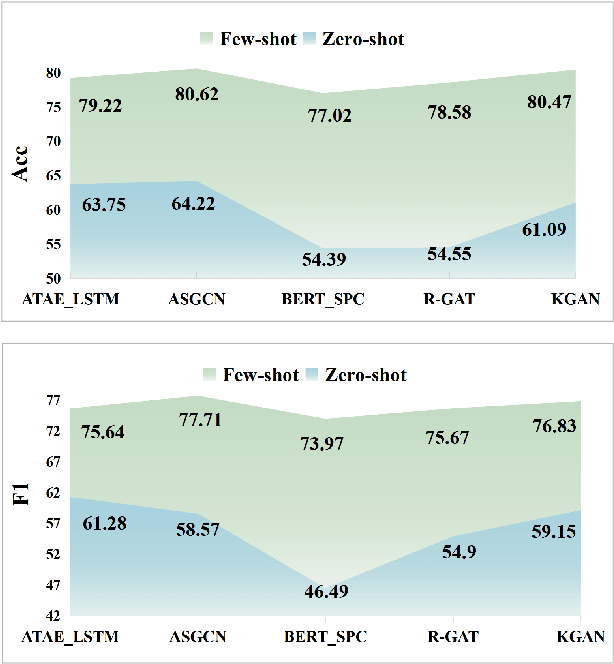
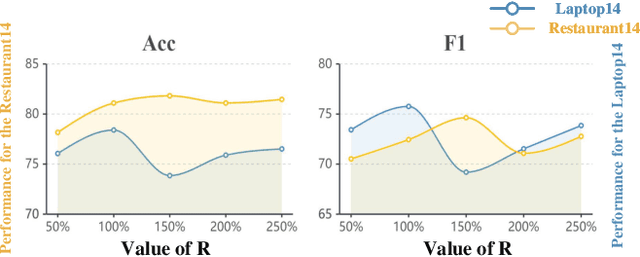
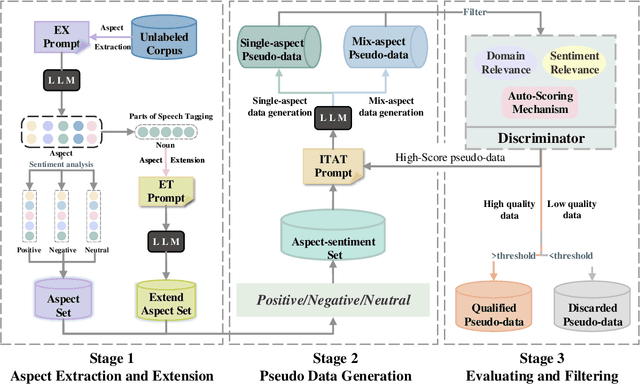
Aspect-based Sentiment Analysis (ABSA) is an important sentiment analysis task, which aims to determine the sentiment polarity towards an aspect in a sentence. Due to the expensive and limited labeled data, data augmentation (DA) has become the standard for improving the performance of ABSA. However, current DA methods usually have some shortcomings: 1) poor fluency and coherence, 2) lack of diversity of generated data, and 3) reliance on some existing labeled data, hindering its applications in real-world scenarios. In response to these problems, we propose a systematic Iterative Data augmentation framework, namely IterD, to boost the performance of ABSA. The core of IterD is to leverage the powerful ability of large language models (LLMs) to iteratively generate more fluent and diverse synthetic labeled data, starting from an unsupervised sentence corpus. Extensive experiments on 4 widely-used ABSA benchmarks show that IterD brings consistent and significant performance gains among 5 baseline ABSA models. More encouragingly, the synthetic data generated by IterD can achieve comparable or even better performance against the manually annotated data.