 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSGA: A Large Tail Risk Model for Learning Value-at-Risk and Expected Shortfall
Jun 03, 2026Learning Value-at-Risk (VaR) and Expected Shortfall (ES) is important for managing financial risks effectively. Existing approaches with limited parameters are vulnerable to model misspecification in the era of big data. To address this limitation, we propose a large tail risk model, the retrieval-enhanced self-grouping autoencoder (ReSGA), which is designed with millions of parameters to exploit the rich cross-sectional dependence and long-term temporal dynamics of assets using their characteristics. Applied to monthly US equity returns from 1926 to 2023 with 153 firm characteristics, ReSGA outperforms twelve econometric and machine learning competitors in terms of out-of-sample loss and statistical backtesting. In addition, its forecast advantages can translate into significant economic gains from long-short decile portfolios that are constructed by a new size-enhanced left-side momentum strategy. To clarify the role of complexity, we further conduct a systematic scaling analysis and demonstrate that improvements in joint VaR-ES forecasting are primarily driven by data complexity rather than model complexity. Finally, our analyses of group-importance and transfer-learning exhibit the interpretability and cross-market generalizability of ReSGA.
Fast Rerandomization for Balancing Covariates in Randomized Experiments: A Metropolis-Hastings Framework
Feb 07, 2026Balancing covariates is critical for credible and efficient randomized experiments. Rerandomization addresses this by repeatedly generating treatment assignments until covariate balance meets a prespecified threshold. By shrinking this threshold, it can achieve arbitrarily strong balance, with established results guaranteeing optimal estimation and valid inference in both finite-sample and asymptotic settings across diverse complex experimental settings. Despite its rigorous theoretical foundations, practical use is limited by the extreme inefficiency of rejection sampling, which becomes prohibitively slow under small thresholds and often forces practitioners to adopt suboptimal settings, leading to degraded performance. Existing work focusing on acceleration typically fail to maintain the uniformity over the acceptable assignment space, thus losing the theoretical grounds of classical rerandomization. Building upon a Metropolis-Hastings framework, we address this challenge by introducing an additional sampling-importance resampling step, which restores uniformity and preserves statistical guarantees. Our proposed algorithm, PSRSRR, achieves speedups ranging from 10 to 10,000 times while maintaining exact and asymptotic validity, as demonstrated by simulations and two real-data applications.
Doubly Robust Fusion of Many Treatments for Policy Learning
May 12, 2025Individualized treatment rules/recommendations (ITRs) aim to improve patient outcomes by tailoring treatments to the characteristics of each individual. However, when there are many treatment groups, existing methods face significant challenges due to data sparsity within treatment groups and highly unbalanced covariate distributions across groups. To address these challenges, we propose a novel calibration-weighted treatment fusion procedure that robustly balances covariates across treatment groups and fuses similar treatments using a penalized working model. The fusion procedure ensures the recovery of latent treatment group structures when either the calibration model or the outcome model is correctly specified. In the fused treatment space, practitioners can seamlessly apply state-of-the-art ITR learning methods with the flexibility to utilize a subset of covariates, thereby achieving robustness while addressing practical concerns such as fairness. We establish theoretical guarantees, including consistency, the oracle property of treatment fusion, and regret bounds when integrated with multi-armed ITR learning methods such as policy trees. Simulation studies show superior group recovery and policy value compared to existing approaches. We illustrate the practical utility of our method using a nationwide electronic health record-derived de-identified database containing data from patients with Chronic Lymphocytic Leukemia and Small Lymphocytic Lymphoma.
On Data Synthesis and Post-training for Visual Abstract Reasoning
Apr 02, 2025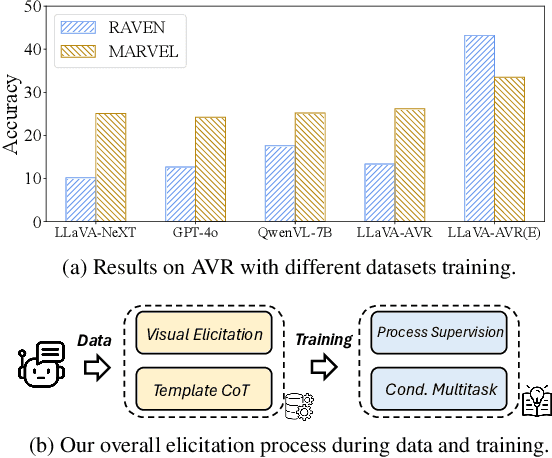



This paper is a pioneering work attempting to address abstract visual reasoning (AVR) problems for large vision-language models (VLMs). We make a common LLaVA-NeXT 7B model capable of perceiving and reasoning about specific AVR problems, surpassing both open-sourced (e.g., Qwen-2-VL-72B) and closed-sourced powerful VLMs (e.g., GPT-4o) with significant margin. This is a great breakthrough since almost all previous VLMs fail or show nearly random performance on representative AVR benchmarks. Our key success is our innovative data synthesis and post-training process, aiming to fully relieve the task difficulty and elicit the model to learn, step by step. Our 7B model is also shown to be behave well on AVR without sacrificing common multimodal comprehension abilities. We hope our paper could serve as an early effort in this area and would inspire further research in abstract visual reasoning.
Descriptive Caption Enhancement with Visual Specialists for Multimodal Perception
Dec 18, 2024



Training Large Multimodality Models (LMMs) relies on descriptive image caption that connects image and language. Existing methods either distill the caption from the LMM models or construct the captions from the internet images or by human. We propose to leverage off-the-shelf visual specialists, which were trained from annotated images initially not for image captioning, for enhancing the image caption. Our approach, named DCE, explores object low-level and fine-grained attributes (e.g., depth, emotion and fine-grained categories) and object relations (e.g., relative location and human-object-interaction (HOI)), and combine the attributes into the descriptive caption. Experiments demonstrate that such visual specialists are able to improve the performance for visual understanding tasks as well as reasoning that benefits from more accurate visual understanding. We will release the source code and the pipeline so that other visual specialists are easily combined into the pipeline. The complete source code of DCE pipeline and datasets will be available at \url{https://github.com/syp2ysy/DCE}.
All You Need in Knowledge Distillation Is a Tailored Coordinate System
Dec 12, 2024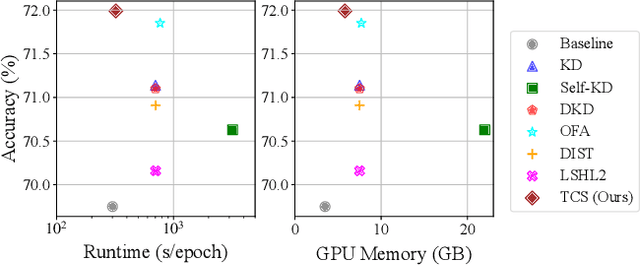
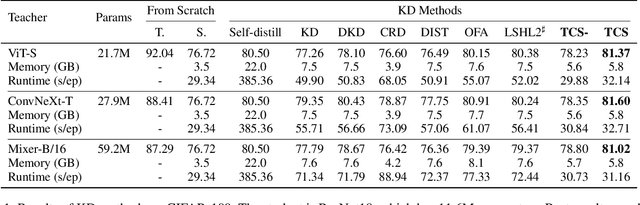
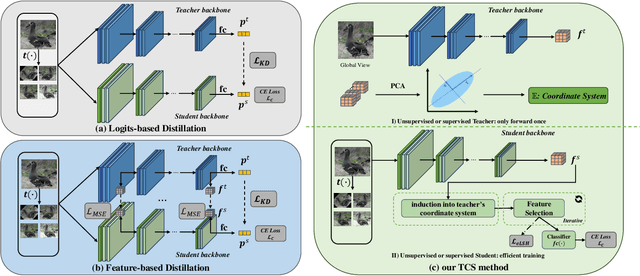
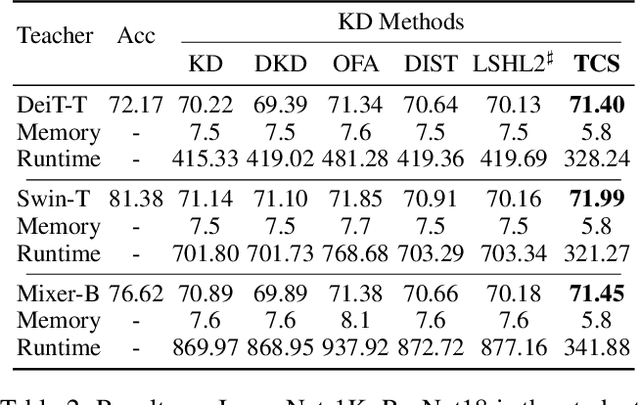
Knowledge Distillation (KD) is essential in transferring dark knowledge from a large teacher to a small student network, such that the student can be much more efficient than the teacher but with comparable accuracy. Existing KD methods, however, rely on a large teacher trained specifically for the target task, which is both very inflexible and inefficient. In this paper, we argue that a SSL-pretrained model can effectively act as the teacher and its dark knowledge can be captured by the coordinate system or linear subspace where the features lie in. We then need only one forward pass of the teacher, and then tailor the coordinate system (TCS) for the student network. Our TCS method is teacher-free and applies to diverse architectures, works well for KD and practical few-shot learning, and allows cross-architecture distillation with large capacity gap. Experiments show that TCS achieves significantly higher accuracy than state-of-the-art KD methods, while only requiring roughly half of their training time and GPU memory costs.
Quantization without Tears
Nov 22, 2024



Deep neural networks, while achieving remarkable success across diverse tasks, demand significant resources, including computation, GPU memory, bandwidth, storage, and energy. Network quantization, as a standard compression and acceleration technique, reduces storage costs and enables potential inference acceleration by discretizing network weights and activations into a finite set of integer values. However, current quantization methods are often complex and sensitive, requiring extensive task-specific hyperparameters, where even a single misconfiguration can impair model performance, limiting generality across different models and tasks. In this paper, we propose Quantization without Tears (QwT), a method that simultaneously achieves quantization speed, accuracy, simplicity, and generality. The key insight of QwT is to incorporate a lightweight additional structure into the quantized network to mitigate information loss during quantization. This structure consists solely of a small set of linear layers, keeping the method simple and efficient. More importantly, it provides a closed-form solution, allowing us to improve accuracy effortlessly under 2 minutes. Extensive experiments across various vision, language, and multimodal tasks demonstrate that QwT is both highly effective and versatile. In fact, our approach offers a robust solution for network quantization that combines simplicity, accuracy, and adaptability, which provides new insights for the design of novel quantization paradigms.
Continual SFT Matches Multimodal RLHF with Negative Supervision
Nov 22, 2024
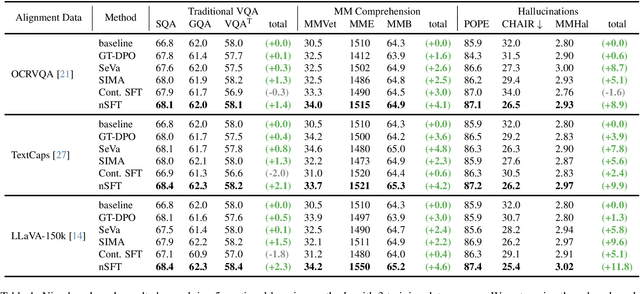
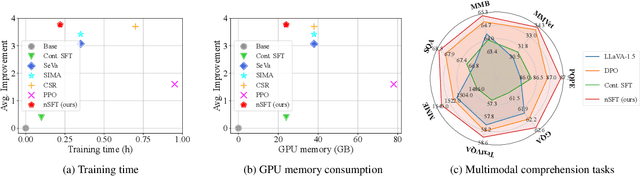
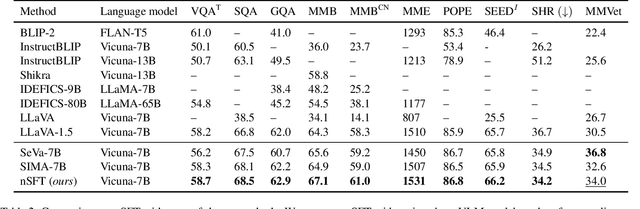
Multimodal RLHF usually happens after supervised finetuning (SFT) stage to continually improve vision-language models' (VLMs) comprehension. Conventional wisdom holds its superiority over continual SFT during this preference alignment stage. In this paper, we observe that the inherent value of multimodal RLHF lies in its negative supervision, the logit of the rejected responses. We thus propose a novel negative supervised finetuning (nSFT) approach that fully excavates these information resided. Our nSFT disentangles this negative supervision in RLHF paradigm, and continually aligns VLMs with a simple SFT loss. This is more memory efficient than multimodal RLHF where 2 (e.g., DPO) or 4 (e.g., PPO) large VLMs are strictly required. The effectiveness of nSFT is rigorously proved by comparing it with various multimodal RLHF approaches, across different dataset sources, base VLMs and evaluation metrics. Besides, fruitful of ablations are provided to support our hypothesis. We hope this paper will stimulate further research to properly align large vision language models.
Enhancement of price trend trading strategies via image-induced importance weights
Aug 16, 2024



We open up the "black-box" to identify the predictive general price patterns in price chart images via the deep learning image analysis techniques. Our identified price patterns lead to the construction of image-induced importance (triple-I) weights, which are applied to weighted moving average the existing price trend trading signals according to their level of importance in predicting price movements. From an extensive empirical analysis on the Chinese stock market, we show that the triple-I weighting scheme can significantly enhance the price trend trading signals for proposing portfolios, with a thoughtful robustness study in terms of network specifications, image structures, and stock sizes. Moreover, we demonstrate that the triple-I weighting scheme is able to propose long-term portfolios from a time-scale transfer learning, enhance the news-based trading strategies through a non-technical transfer learning, and increase the overall strength of numerous trading rules for portfolio selection.
Generalized Maximum Likelihood Estimation for Perspective-n-Point Problem
Aug 04, 2024

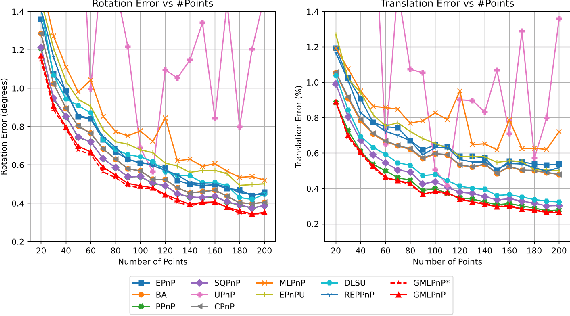

The Perspective-n-Point (PnP) problem has been widely studied in the literature and applied in various vision-based pose estimation scenarios. However, existing methods ignore the anisotropy uncertainty of observations, as demonstrated in several real-world datasets in this paper. This oversight may lead to suboptimal and inaccurate estimation, particularly in the presence of noisy observations. To this end, we propose a generalized maximum likelihood PnP solver, named GMLPnP, that minimizes the determinant criterion by iterating the GLS procedure to estimate the pose and uncertainty simultaneously. Further, the proposed method is decoupled from the camera model. Results of synthetic and real experiments show that our method achieves better accuracy in common pose estimation scenarios, GMLPnP improves rotation/translation accuracy by 4.7%/2.0% on TUM-RGBD and 18.6%/18.4% on KITTI-360 dataset compared to the best baseline. It is more accurate under very noisy observations in a vision-based UAV localization task, outperforming the best baseline by 34.4% in translation estimation accuracy.