 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll You Need in Knowledge Distillation Is a Tailored Coordinate System
Paper and Code
Dec 12, 2024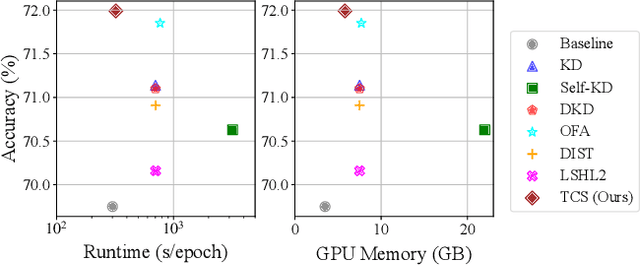
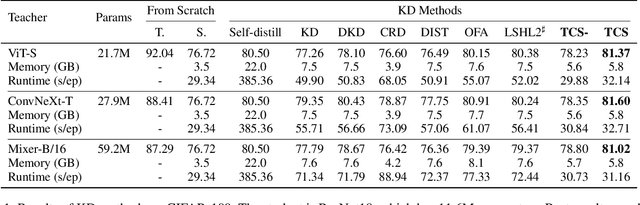
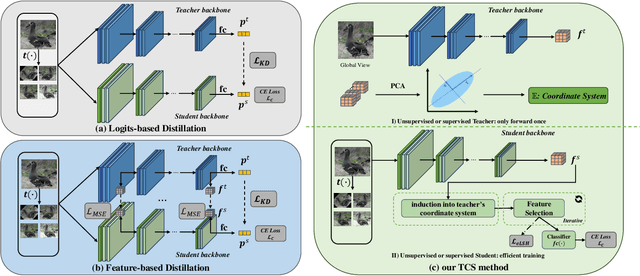
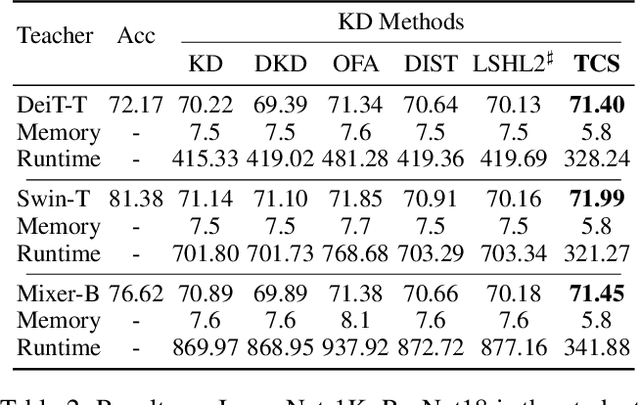
Knowledge Distillation (KD) is essential in transferring dark knowledge from a large teacher to a small student network, such that the student can be much more efficient than the teacher but with comparable accuracy. Existing KD methods, however, rely on a large teacher trained specifically for the target task, which is both very inflexible and inefficient. In this paper, we argue that a SSL-pretrained model can effectively act as the teacher and its dark knowledge can be captured by the coordinate system or linear subspace where the features lie in. We then need only one forward pass of the teacher, and then tailor the coordinate system (TCS) for the student network. Our TCS method is teacher-free and applies to diverse architectures, works well for KD and practical few-shot learning, and allows cross-architecture distillation with large capacity gap. Experiments show that TCS achieves significantly higher accuracy than state-of-the-art KD methods, while only requiring roughly half of their training time and GPU memory costs.