 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinVBC: A Model-based Reinforcement Learning Approach to Vehicle Braking Controller
Apr 06, 2026Braking system, the key module to ensure the safety and steer-ability of current vehicles, relies on extensive manual calibration during production. Reducing labor and time consumption while maintaining the Vehicle Braking Controller (VBC) performance greatly benefits the vehicle industry. Model-based methods in offline reinforcement learning, which facilitate policy exploration within a data-driven dynamics model, offer a promising solution for addressing real-world control tasks. This work proposes ReinVBC, which applies an offline model-based reinforcement learning approach to deal with the vehicle braking control problem. We introduce useful engineering designs into the paradigm of model learning and utilization to obtain a reliable vehicle dynamics model and a capable braking policy. Several results demonstrate the capability of our method in real-world vehicle braking and its potential to replace the production-grade anti-lock braking system.
Advancing Cancer Prognosis with Hierarchical Fusion of Genomic, Proteomic and Pathology Imaging Data from a Systems Biology Perspective
Mar 14, 2026To enhance the precision of cancer prognosis, recent research has increasingly focused on multimodal survival methods by integrating genomic data and histology images. However, current approaches overlook the fact that the proteome serves as an intermediate layer bridging genomic alterations and histopathological features while providing complementary biological information essential for survival prediction. This biological reality exposes another architectural limitation: existing integrative analysis studies fuse these heterogeneous data sources in a flat manner that fails to capture their inherent biological hierarchy. To address these limitations, we propose HFGPI, a hierarchical fusion framework that models the biological progression from genes to proteins to histology images from a systems biology perspective. Specifically, we introduce Molecular Tokenizer, a molecular encoding strategy that integrates identity embeddings with expression profiles to construct biologically informed representations for genes and proteins. We then develop Gene-Regulated Protein Fusion (GRPF), which employs graph-aware cross-attention with structure-preserving alignment to explicitly model gene-protein regulatory relationships and generate gene-regulated protein representations. Additionally, we propose Protein-Guided Hypergraph Learning (PGHL), which establishes associations between proteins and image patches, leveraging hypergraph convolution to capture higher-order protein-morphology relationships. The final features are progressively fused across hierarchical layers to achieve precise survival outcome prediction. Extensive experiments on five benchmark datasets demonstrate the superiority of HFGPI over state-of-the-art methods.
Human Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
GenAgent: Scaling Text-to-Image Generation via Agentic Multimodal Reasoning
Jan 26, 2026We introduce GenAgent, unifying visual understanding and generation through an agentic multimodal model. Unlike unified models that face expensive training costs and understanding-generation trade-offs, GenAgent decouples these capabilities through an agentic framework: understanding is handled by the multimodal model itself, while generation is achieved by treating image generation models as invokable tools. Crucially, unlike existing modular systems constrained by static pipelines, this design enables autonomous multi-turn interactions where the agent generates multimodal chains-of-thought encompassing reasoning, tool invocation, judgment, and reflection to iteratively refine outputs. We employ a two-stage training strategy: first, cold-start with supervised fine-tuning on high-quality tool invocation and reflection data to bootstrap agent behaviors; second, end-to-end agentic reinforcement learning combining pointwise rewards (final image quality) and pairwise rewards (reflection accuracy), with trajectory resampling for enhanced multi-turn exploration. GenAgent significantly boosts base generator(FLUX.1-dev) performance on GenEval++ (+23.6\%) and WISE (+14\%). Beyond performance gains, our framework demonstrates three key properties: 1) cross-tool generalization to generators with varying capabilities, 2) test-time scaling with consistent improvements across interaction rounds, and 3) task-adaptive reasoning that automatically adjusts to different tasks. Our code will be available at \href{https://github.com/deep-kaixun/GenAgent}{this url}.
ShowTable: Unlocking Creative Table Visualization with Collaborative Reflection and Refinement
Dec 15, 2025While existing generation and unified models excel at general image generation, they struggle with tasks requiring deep reasoning, planning, and precise data-to-visual mapping abilities beyond general scenarios. To push beyond the existing limitations, we introduce a new and challenging task: creative table visualization, requiring the model to generate an infographic that faithfully and aesthetically visualizes the data from a given table. To address this challenge, we propose ShowTable, a pipeline that synergizes MLLMs with diffusion models via a progressive self-correcting process. The MLLM acts as the central orchestrator for reasoning the visual plan and judging visual errors to provide refined instructions, the diffusion execute the commands from MLLM, achieving high-fidelity results. To support this task and our pipeline, we introduce three automated data construction pipelines for training different modules. Furthermore, we introduce TableVisBench, a new benchmark with 800 challenging instances across 5 evaluation dimensions, to assess performance on this task. Experiments demonstrate that our pipeline, instantiated with different models, significantly outperforms baselines, highlighting its effective multi-modal reasoning, generation, and error correction capabilities.
OmniGen2: Exploration to Advanced Multimodal Generation
Jun 23, 2025In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
VideoDeepResearch: Long Video Understanding With Agentic Tool Using
Jun 12, 2025Long video understanding (LVU) presents a significant challenge for current multi-modal large language models (MLLMs) due to the task's inherent complexity and context window constraint. It is widely assumed that addressing LVU tasks requires foundation MLLMs with extended context windows, strong visual perception capabilities, and proficient domain expertise. In this work, we challenge this common belief by introducing VideoDeepResearch, a novel agentic framework for long video understanding. Our approach relies solely on a text-only large reasoning model (LRM) combined with a modular multi-modal toolkit, including multimodal retrievers and visual perceivers, all of which are readily available in practice. For each LVU task, the system formulates a problem-solving strategy through reasoning, while selectively accessing and utilizing essential video content via tool using. We conduct extensive experiments on popular LVU benchmarks, including MLVU, Video-MME, and LVBench. Our results demonstrate that VideoDeepResearch achieves substantial improvements over existing MLLM baselines, surpassing the previous state-of-the-art by 9.6%, 6.6%, and 3.9% on MLVU (test), LVBench, and LongVideoBench, respectively. These findings highlight the promise of agentic systems in overcoming key challenges in LVU problems.
Feature Fusion Revisited: Multimodal CTR Prediction for MMCTR Challenge
Apr 26, 2025With the rapid advancement of Multimodal Large Language Models (MLLMs), an increasing number of researchers are exploring their application in recommendation systems. However, the high latency associated with large models presents a significant challenge for such use cases. The EReL@MIR workshop provided a valuable opportunity to experiment with various approaches aimed at improving the efficiency of multimodal representation learning for information retrieval tasks. As part of the competition's requirements, participants were mandated to submit a technical report detailing their methodologies and findings. Our team was honored to receive the award for Task 2 - Winner (Multimodal CTR Prediction). In this technical report, we present our methods and key findings. Additionally, we propose several directions for future work, particularly focusing on how to effectively integrate recommendation signals into multimodal representations. The codebase for our implementation is publicly available at: https://github.com/Lattice-zjj/MMCTR_Code, and the trained model weights can be accessed at: https://huggingface.co/FireFlyCourageous/MMCTR_DIN_MicroLens_1M_x1.
DAMM-Diffusion: Learning Divergence-Aware Multi-Modal Diffusion Model for Nanoparticles Distribution Prediction
Mar 12, 2025



The prediction of nanoparticles (NPs) distribution is crucial for the diagnosis and treatment of tumors. Recent studies indicate that the heterogeneity of tumor microenvironment (TME) highly affects the distribution of NPs across tumors. Hence, it has become a research hotspot to generate the NPs distribution by the aid of multi-modal TME components. However, the distribution divergence among multi-modal TME components may cause side effects i.e., the best uni-modal model may outperform the joint generative model. To address the above issues, we propose a \textbf{D}ivergence-\textbf{A}ware \textbf{M}ulti-\textbf{M}odal \textbf{Diffusion} model (i.e., \textbf{DAMM-Diffusion}) to adaptively generate the prediction results from uni-modal and multi-modal branches in a unified network. In detail, the uni-modal branch is composed of the U-Net architecture while the multi-modal branch extends it by introducing two novel fusion modules i.e., Multi-Modal Fusion Module (MMFM) and Uncertainty-Aware Fusion Module (UAFM). Specifically, the MMFM is proposed to fuse features from multiple modalities, while the UAFM module is introduced to learn the uncertainty map for cross-attention computation. Following the individual prediction results from each branch, the Divergence-Aware Multi-Modal Predictor (DAMMP) module is proposed to assess the consistency of multi-modal data with the uncertainty map, which determines whether the final prediction results come from multi-modal or uni-modal predictions. We predict the NPs distribution given the TME components of tumor vessels and cell nuclei, and the experimental results show that DAMM-Diffusion can generate the distribution of NPs with higher accuracy than the comparing methods. Additional results on the multi-modal brain image synthesis task further validate the effectiveness of the proposed method.
Robust Multimodal Survival Prediction with the Latent Differentiation Conditional Variational AutoEncoder
Mar 12, 2025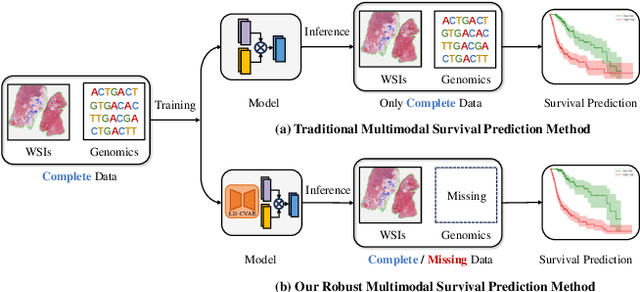

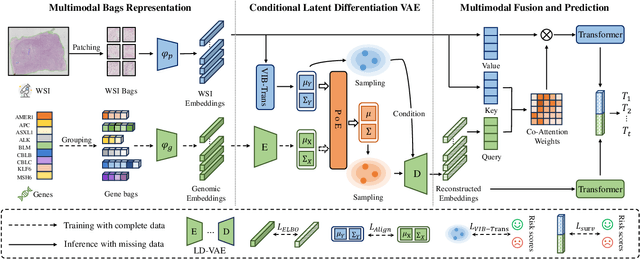

The integrative analysis of histopathological images and genomic data has received increasing attention for survival prediction of human cancers. However, the existing studies always hold the assumption that full modalities are available. As a matter of fact, the cost for collecting genomic data is high, which sometimes makes genomic data unavailable in testing samples. A common way of tackling such incompleteness is to generate the genomic representations from the pathology images. Nevertheless, such strategy still faces the following two challenges: (1) The gigapixel whole slide images (WSIs) are huge and thus hard for representation. (2) It is difficult to generate the genomic embeddings with diverse function categories in a unified generative framework. To address the above challenges, we propose a Conditional Latent Differentiation Variational AutoEncoder (LD-CVAE) for robust multimodal survival prediction, even with missing genomic data. Specifically, a Variational Information Bottleneck Transformer (VIB-Trans) module is proposed to learn compressed pathological representations from the gigapixel WSIs. To generate different functional genomic features, we develop a novel Latent Differentiation Variational AutoEncoder (LD-VAE) to learn the common and specific posteriors for the genomic embeddings with diverse functions. Finally, we use the product-of-experts technique to integrate the genomic common posterior and image posterior for the joint latent distribution estimation in LD-CVAE. We test the effectiveness of our method on five different cancer datasets, and the experimental results demonstrate its superiority in both complete and missing modality scenarios.