 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaPairs: Massive Data Synthesis For Universal Multimodal Retrieval
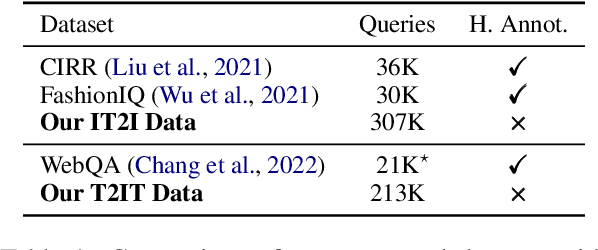
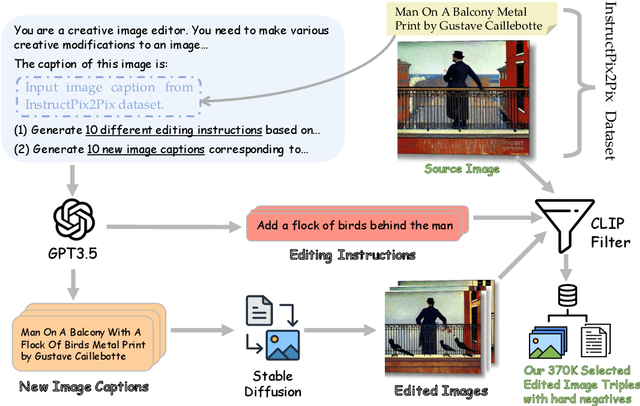
Dec 19, 2024Despite the rapidly growing demand for multimodal retrieval, progress in this field remains severely constrained by a lack of training data. In this paper, we introduce MegaPairs, a novel data synthesis method that leverages vision language models (VLMs) and open-domain images, together with a massive synthetic dataset generated from this method. Our empirical analysis shows that MegaPairs generates high-quality data, enabling the multimodal retriever to significantly outperform the baseline model trained on 70$\times$ more data from existing datasets. Moreover, since MegaPairs solely relies on general image corpora and open-source VLMs, it can be easily scaled up, enabling continuous improvements in retrieval performance. In this stage, we produced more than 26 million training instances and trained several models of varying sizes using this data. These new models achieve state-of-the-art zero-shot performance across 4 popular composed image retrieval (CIR) benchmarks and the highest overall performance on the 36 datasets provided by MMEB. They also demonstrate notable performance improvements with additional downstream fine-tuning. Our produced dataset, well-trained models, and data synthesis pipeline will be made publicly available to facilitate the future development of this field.
DirectL: Efficient Radiance Fields Rendering for 3D Light Field Displays
Jul 19, 2024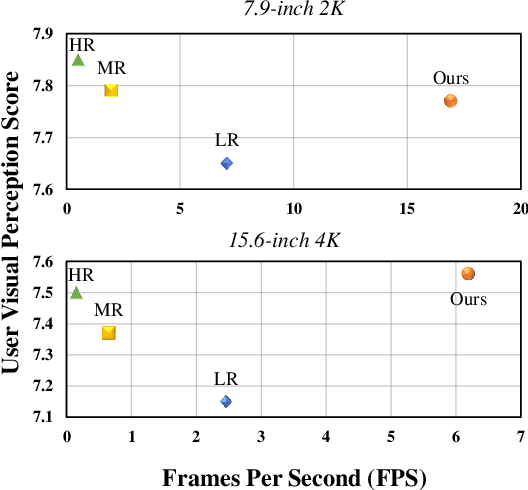
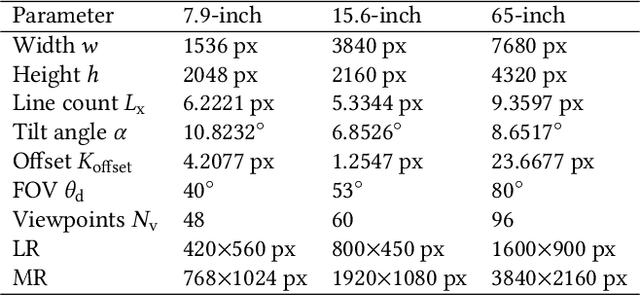
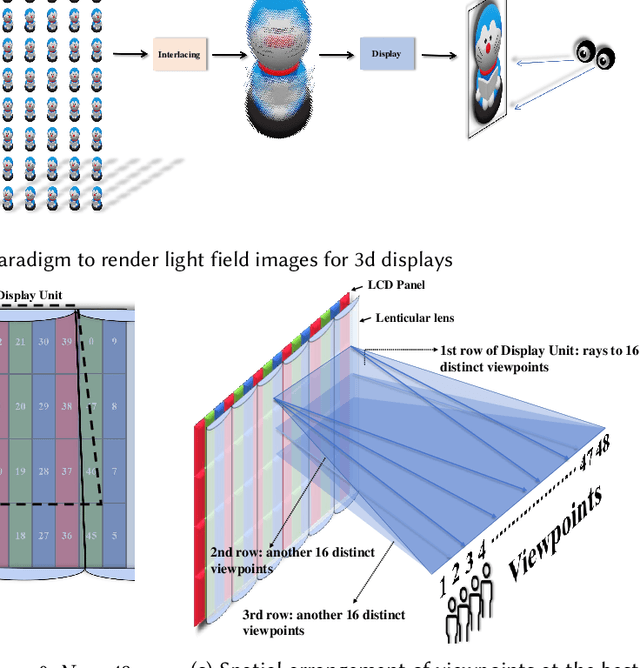

Autostereoscopic display, despite decades of development, has not achieved extensive application, primarily due to the daunting challenge of 3D content creation for non-specialists. The emergence of Radiance Field as an innovative 3D representation has markedly revolutionized the domains of 3D reconstruction and generation. This technology greatly simplifies 3D content creation for common users, broadening the applicability of Light Field Displays (LFDs). However, the combination of these two fields remains largely unexplored. The standard paradigm to create optimal content for parallax-based light field displays demands rendering at least 45 slightly shifted views preferably at high resolution per frame, a substantial hurdle for real-time rendering. We introduce DirectL, a novel rendering paradigm for Radiance Fields on 3D displays. We thoroughly analyze the interweaved mapping of spatial rays to screen subpixels, precisely determine the light rays entering the human eye, and propose subpixel repurposing to significantly reduce the pixel count required for rendering. Tailored for the two predominant radiance fields--Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS), we propose corresponding optimized rendering pipelines that directly render the light field images instead of multi-view images. Extensive experiments across various displays and user study demonstrate that DirectL accelerates rendering by up to 40 times compared to the standard paradigm without sacrificing visual quality. Its rendering process-only modification allows seamless integration into subsequent radiance field tasks. Finally, we integrate DirectL into diverse applications, showcasing the stunning visual experiences and the synergy between LFDs and Radiance Fields, which unveils tremendous potential for commercialization applications. \href{direct-l.github.io}{\textbf{Project Homepage}
VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval
Jun 06, 2024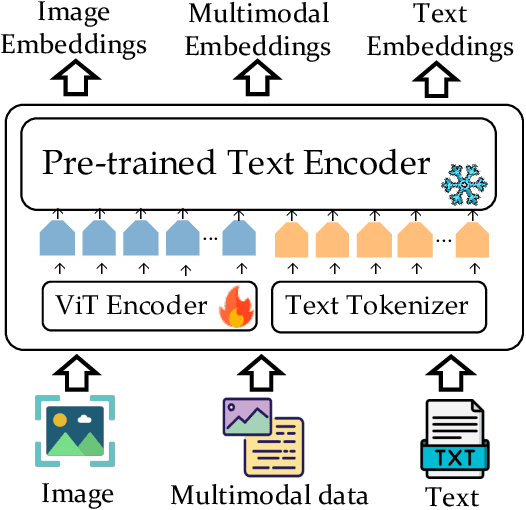

Multi-modal retrieval becomes increasingly popular in practice. However, the existing retrievers are mostly text-oriented, which lack the capability to process visual information. Despite the presence of vision-language models like CLIP, the current methods are severely limited in representing the text-only and image-only data. In this work, we present a new embedding model VISTA for universal multi-modal retrieval. Our work brings forth threefold technical contributions. Firstly, we introduce a flexible architecture which extends a powerful text encoder with the image understanding capability by introducing visual token embeddings. Secondly, we develop two data generation strategies, which bring high-quality composed image-text to facilitate the training of the embedding model. Thirdly, we introduce a multi-stage training algorithm, which first aligns the visual token embedding with the text encoder using massive weakly labeled data, and then develops multi-modal representation capability using the generated composed image-text data. In our experiments, VISTA achieves superior performances across a variety of multi-modal retrieval tasks in both zero-shot and supervised settings. Our model, data, and source code are available at https://github.com/FlagOpen/FlagEmbedding.
MLVU: A Comprehensive Benchmark for Multi-Task Long Video Understanding
Jun 06, 2024



The evaluation of Long Video Understanding (LVU) performance poses an important but challenging research problem. Despite previous efforts, the existing video understanding benchmarks are severely constrained by several issues, especially the insufficient lengths of videos, a lack of diversity in video types and evaluation tasks, and the inappropriateness for evaluating LVU performances. To address the above problems, we propose a new benchmark, called MLVU (Multi-task Long Video Understanding Benchmark), for the comprehensive and in-depth evaluation of LVU. MLVU presents the following critical values: 1) The substantial and flexible extension of video lengths, which enables the benchmark to evaluate LVU performance across a wide range of durations. 2) The inclusion of various video genres, e.g., movies, surveillance footage, egocentric videos, cartoons, game videos, etc., which reflects the models' LVU performances in different scenarios. 3) The development of diversified evaluation tasks, which enables a comprehensive examination of MLLMs' key abilities in long-video understanding. The empirical study with 20 latest MLLMs reveals significant room for improvement in today's technique, as all existing methods struggle with most of the evaluation tasks and exhibit severe performance degradation when handling longer videos. Additionally, it suggests that factors such as context length, image-understanding quality, and the choice of LLM backbone can play critical roles in future advancements. We anticipate that MLVU will advance the research of long video understanding by providing a comprehensive and in-depth analysis of MLLMs.
TextDiff: Mask-Guided Residual Diffusion Models for Scene Text Image Super-Resolution
Aug 13, 2023
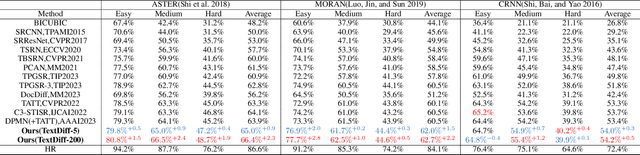

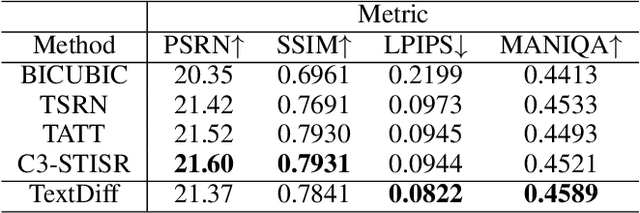
The goal of scene text image super-resolution is to reconstruct high-resolution text-line images from unrecognizable low-resolution inputs. The existing methods relying on the optimization of pixel-level loss tend to yield text edges that exhibit a notable degree of blurring, thereby exerting a substantial impact on both the readability and recognizability of the text. To address these issues, we propose TextDiff, the first diffusion-based framework tailored for scene text image super-resolution. It contains two modules: the Text Enhancement Module (TEM) and the Mask-Guided Residual Diffusion Module (MRD). The TEM generates an initial deblurred text image and a mask that encodes the spatial location of the text. The MRD is responsible for effectively sharpening the text edge by modeling the residuals between the ground-truth images and the initial deblurred images. Extensive experiments demonstrate that our TextDiff achieves state-of-the-art (SOTA) performance on public benchmark datasets and can improve the readability of scene text images. Moreover, our proposed MRD module is plug-and-play that effectively sharpens the text edges produced by SOTA methods. This enhancement not only improves the readability and recognizability of the results generated by SOTA methods but also does not require any additional joint training. Available Codes:https://github.com/Lenubolim/TextDiff.
DocDiff: Document Enhancement via Residual Diffusion Models
May 06, 2023Removing degradation from document images not only improves their visual quality and readability, but also enhances the performance of numerous automated document analysis and recognition tasks. However, existing regression-based methods optimized for pixel-level distortion reduction tend to suffer from significant loss of high-frequency information, leading to distorted and blurred text edges. To compensate for this major deficiency, we propose DocDiff, the first diffusion-based framework specifically designed for diverse challenging document enhancement problems, including document deblurring, denoising, and removal of watermarks and seals. DocDiff consists of two modules: the Coarse Predictor (CP), which is responsible for recovering the primary low-frequency content, and the High-Frequency Residual Refinement (HRR) module, which adopts the diffusion models to predict the residual (high-frequency information, including text edges), between the ground-truth and the CP-predicted image. DocDiff is a compact and computationally efficient model that benefits from a well-designed network architecture, an optimized training loss objective, and a deterministic sampling process with short time steps. Extensive experiments demonstrate that DocDiff achieves state-of-the-art (SOTA) performance on multiple benchmark datasets, and can significantly enhance the readability and recognizability of degraded document images. Furthermore, our proposed HRR module in pre-trained DocDiff is plug-and-play and ready-to-use, with only 4.17M parameters. It greatly sharpens the text edges generated by SOTA deblurring methods without additional joint training. Available codes: https://github.com/Royalvice/DocDiff
GDB: Gated convolutions-based Document Binarization
Feb 04, 2023
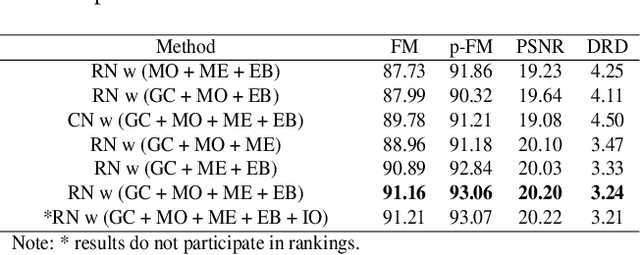
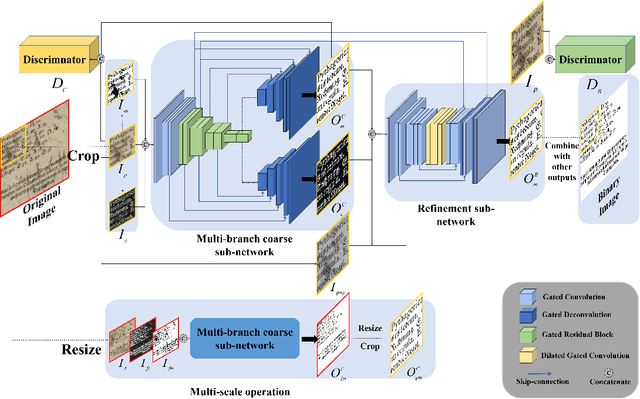
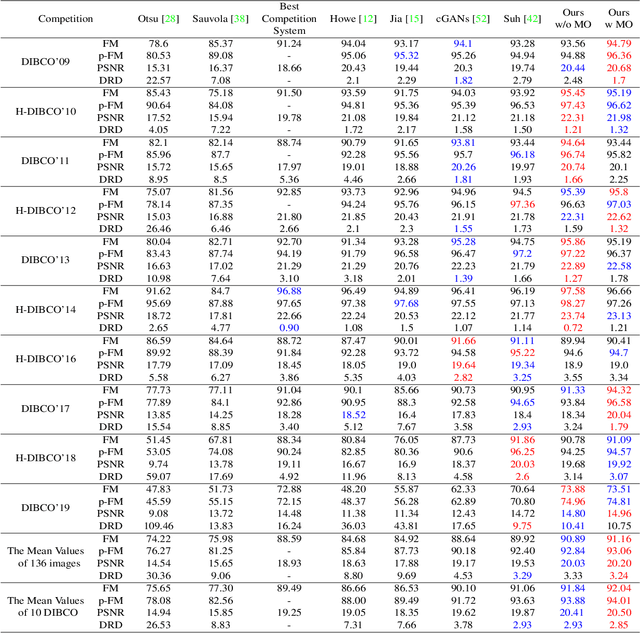
Document binarization is a key pre-processing step for many document analysis tasks. However, existing methods can not extract stroke edges finely, mainly due to the fair-treatment nature of vanilla convolutions and the extraction of stroke edges without adequate supervision by boundary-related information. In this paper, we formulate text extraction as the learning of gating values and propose an end-to-end gated convolutions-based network (GDB) to solve the problem of imprecise stroke edge extraction. The gated convolutions are applied to selectively extract the features of strokes with different attention. Our proposed framework consists of two stages. Firstly, a coarse sub-network with an extra edge branch is trained to get more precise feature maps by feeding a priori mask and edge. Secondly, a refinement sub-network is cascaded to refine the output of the first stage by gated convolutions based on the sharp edge. For global information, GDB also contains a multi-scale operation to combine local and global features. We conduct comprehensive experiments on ten Document Image Binarization Contest (DIBCO) datasets from 2009 to 2019. Experimental results show that our proposed methods outperform the state-of-the-art methods in terms of all metrics on average and achieve top ranking on six benchmark datasets.
SAT: Size-Aware Transformer for 3D Point Cloud Semantic Segmentation
Jan 17, 2023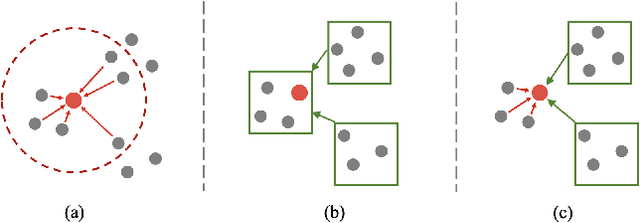
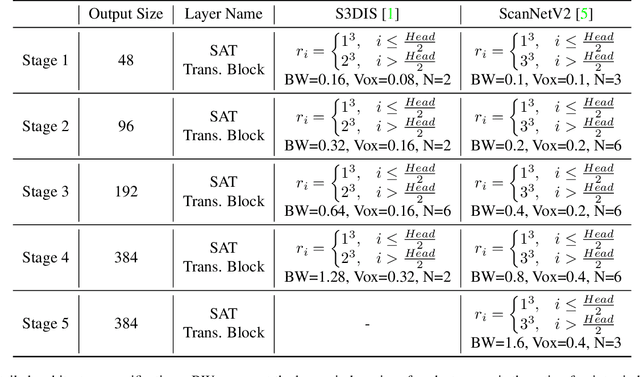
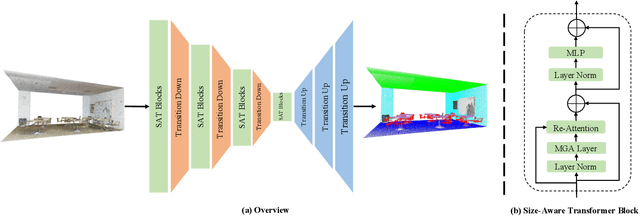
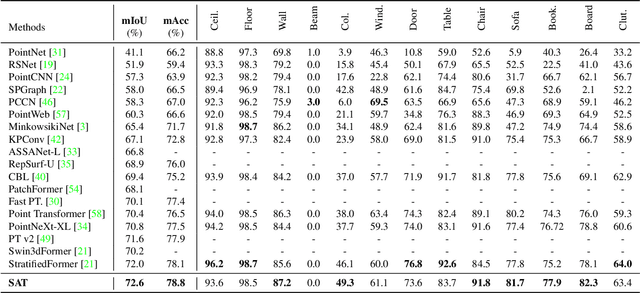
Transformer models have achieved promising performances in point cloud segmentation. However, most existing attention schemes provide the same feature learning paradigm for all points equally and overlook the enormous difference in size among scene objects. In this paper, we propose the Size-Aware Transformer (SAT) that can tailor effective receptive fields for objects of different sizes. Our SAT achieves size-aware learning via two steps: introduce multi-scale features to each attention layer and allow each point to choose its attentive fields adaptively. It contains two key designs: the Multi-Granularity Attention (MGA) scheme and the Re-Attention module. The MGA addresses two challenges: efficiently aggregating tokens from distant areas and preserving multi-scale features within one attention layer. Specifically, point-voxel cross attention is proposed to address the first challenge, and the shunted strategy based on the standard multi-head self attention is applied to solve the second. The Re-Attention module dynamically adjusts the attention scores to the fine- and coarse-grained features output by MGA for each point. Extensive experimental results demonstrate that SAT achieves state-of-the-art performances on S3DIS and ScanNetV2 datasets. Our SAT also achieves the most balanced performance on categories among all referred methods, which illustrates the superiority of modelling categories of different sizes. Our code and model will be released after the acceptance of this paper.