 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreative4U: MLLMs-based Advertising Creative Image Selector with Comparative Reasoning
Aug 18, 2025Creative image in advertising is the heart and soul of e-commerce platform. An eye-catching creative image can enhance the shopping experience for users, boosting income for advertisers and advertising revenue for platforms. With the advent of AIGC technology, advertisers can produce large quantities of creative images at minimal cost. However, they struggle to assess the creative quality to select. Existing methods primarily focus on creative ranking, which fails to address the need for explainable creative selection. In this work, we propose the first paradigm for explainable creative assessment and selection. Powered by multimodal large language models (MLLMs), our approach integrates the assessment and selection of creative images into a natural language generation task. To facilitate this research, we construct CreativePair, the first comparative reasoning-induced creative dataset featuring 8k annotated image pairs, with each sample including a label indicating which image is superior. Additionally, we introduce Creative4U (pronounced Creative for You), a MLLMs-based creative selector that takes into account users' interests. Through Reason-to-Select RFT, which includes supervised fine-tuning with Chain-of-Thought (CoT-SFT) and Group Relative Policy Optimization (GRPO) based reinforcement learning, Creative4U is able to evaluate and select creative images accurately. Both offline and online experiments demonstrate the effectiveness of our approach. Our code and dataset will be made public to advance research and industrial applications.
DirectL: Efficient Radiance Fields Rendering for 3D Light Field Displays
Jul 19, 2024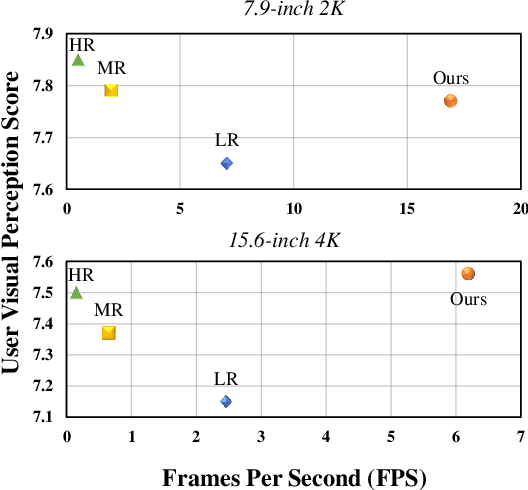
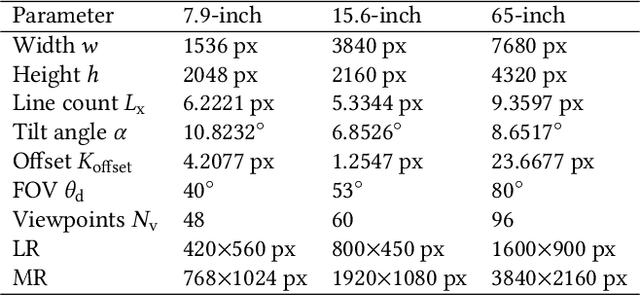
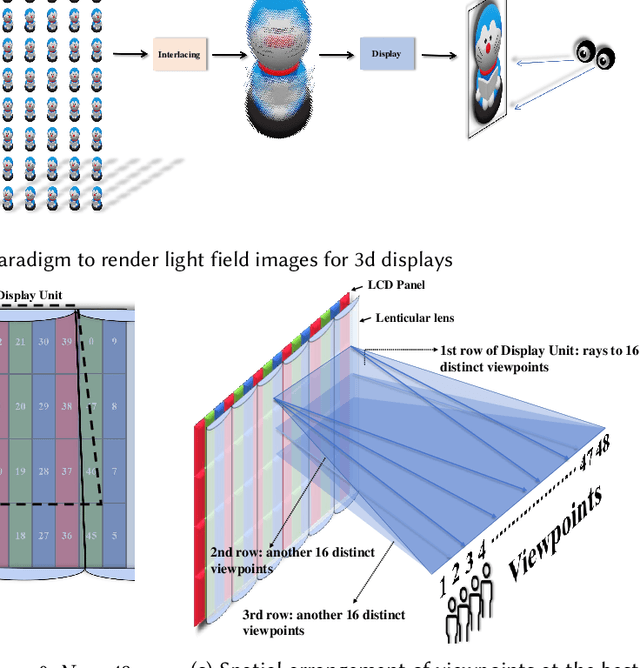

Autostereoscopic display, despite decades of development, has not achieved extensive application, primarily due to the daunting challenge of 3D content creation for non-specialists. The emergence of Radiance Field as an innovative 3D representation has markedly revolutionized the domains of 3D reconstruction and generation. This technology greatly simplifies 3D content creation for common users, broadening the applicability of Light Field Displays (LFDs). However, the combination of these two fields remains largely unexplored. The standard paradigm to create optimal content for parallax-based light field displays demands rendering at least 45 slightly shifted views preferably at high resolution per frame, a substantial hurdle for real-time rendering. We introduce DirectL, a novel rendering paradigm for Radiance Fields on 3D displays. We thoroughly analyze the interweaved mapping of spatial rays to screen subpixels, precisely determine the light rays entering the human eye, and propose subpixel repurposing to significantly reduce the pixel count required for rendering. Tailored for the two predominant radiance fields--Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS), we propose corresponding optimized rendering pipelines that directly render the light field images instead of multi-view images. Extensive experiments across various displays and user study demonstrate that DirectL accelerates rendering by up to 40 times compared to the standard paradigm without sacrificing visual quality. Its rendering process-only modification allows seamless integration into subsequent radiance field tasks. Finally, we integrate DirectL into diverse applications, showcasing the stunning visual experiences and the synergy between LFDs and Radiance Fields, which unveils tremendous potential for commercialization applications. \href{direct-l.github.io}{\textbf{Project Homepage}
TextDiff: Mask-Guided Residual Diffusion Models for Scene Text Image Super-Resolution
Aug 13, 2023
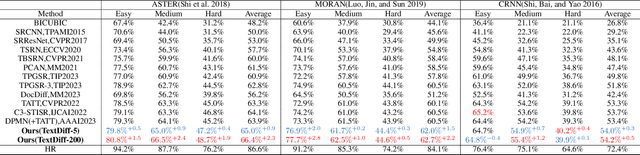

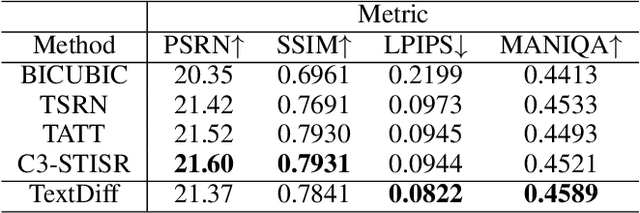
The goal of scene text image super-resolution is to reconstruct high-resolution text-line images from unrecognizable low-resolution inputs. The existing methods relying on the optimization of pixel-level loss tend to yield text edges that exhibit a notable degree of blurring, thereby exerting a substantial impact on both the readability and recognizability of the text. To address these issues, we propose TextDiff, the first diffusion-based framework tailored for scene text image super-resolution. It contains two modules: the Text Enhancement Module (TEM) and the Mask-Guided Residual Diffusion Module (MRD). The TEM generates an initial deblurred text image and a mask that encodes the spatial location of the text. The MRD is responsible for effectively sharpening the text edge by modeling the residuals between the ground-truth images and the initial deblurred images. Extensive experiments demonstrate that our TextDiff achieves state-of-the-art (SOTA) performance on public benchmark datasets and can improve the readability of scene text images. Moreover, our proposed MRD module is plug-and-play that effectively sharpens the text edges produced by SOTA methods. This enhancement not only improves the readability and recognizability of the results generated by SOTA methods but also does not require any additional joint training. Available Codes:https://github.com/Lenubolim/TextDiff.
Collision-free Motion Generation Based on Stochastic Optimization and Composite Signed Distance Field Networks of Articulated Robot
Jun 07, 2023



Safe robot motion generation is critical for practical applications from manufacturing to homes. In this work, we proposed a stochastic optimization-based motion generation method to generate collision-free and time-optimal motion for the articulated robot represented by composite signed distance field (SDF) networks. First, we propose composite SDF networks to learn the SDF for articulated robots. The learned composite SDF networks combined with the kinematics of the robot allow for quick and accurate estimates of the minimum distance between the robot and obstacles in a batch fashion. Then, a stochastic optimization-based trajectory planning algorithm generates a spatial-optimized and collision-free trajectory offline with the learned composite SDF networks. This stochastic trajectory planner is formulated as a Bayesian Inference problem with a time-normalized Gaussian process prior and exponential likelihood function. The Gaussian process prior can enforce initial and goal position constraints in Configuration Space. Besides, it can encode the correlation of waypoints in time series. The likelihood function aims at encoding task-related cost terms, such as collision avoidance, trajectory length penalty, boundary avoidance, etc. The kernel updating strategies combined with model-predictive path integral (MPPI) is proposed to solve the maximum a posteriori inference problems. Lastly, we integrate the learned composite SDF networks into the trajectory planning algorithm and apply it to a Franka Emika Panda robot. The simulation and experiment results validate the effectiveness of the proposed method.
Capturing Conversion Rate Fluctuation during Sales Promotions: A Novel Historical Data Reuse Approach
May 22, 2023



Conversion rate (CVR) prediction is one of the core components in online recommender systems, and various approaches have been proposed to obtain accurate and well-calibrated CVR estimation. However, we observe that a well-trained CVR prediction model often performs sub-optimally during sales promotions. This can be largely ascribed to the problem of the data distribution shift, in which the conventional methods no longer work. To this end, we seek to develop alternative modeling techniques for CVR prediction. Observing similar purchase patterns across different promotions, we propose reusing the historical promotion data to capture the promotional conversion patterns. Herein, we propose a novel \textbf{H}istorical \textbf{D}ata \textbf{R}euse (\textbf{HDR}) approach that first retrieves historically similar promotion data and then fine-tunes the CVR prediction model with the acquired data for better adaptation to the promotion mode. HDR consists of three components: an automated data retrieval module that seeks similar data from historical promotions, a distribution shift correction module that re-weights the retrieved data for better aligning with the target promotion, and a TransBlock module that quickly fine-tunes the original model for better adaptation to the promotion mode. Experiments conducted with real-world data demonstrate the effectiveness of HDR, as it improves both ranking and calibration metrics to a large extent. HDR has also been deployed on the display advertising system in Alibaba, bringing a lift of $9\%$ RPM and $16\%$ CVR during Double 11 Sales in 2022.
DocDiff: Document Enhancement via Residual Diffusion Models
May 06, 2023Removing degradation from document images not only improves their visual quality and readability, but also enhances the performance of numerous automated document analysis and recognition tasks. However, existing regression-based methods optimized for pixel-level distortion reduction tend to suffer from significant loss of high-frequency information, leading to distorted and blurred text edges. To compensate for this major deficiency, we propose DocDiff, the first diffusion-based framework specifically designed for diverse challenging document enhancement problems, including document deblurring, denoising, and removal of watermarks and seals. DocDiff consists of two modules: the Coarse Predictor (CP), which is responsible for recovering the primary low-frequency content, and the High-Frequency Residual Refinement (HRR) module, which adopts the diffusion models to predict the residual (high-frequency information, including text edges), between the ground-truth and the CP-predicted image. DocDiff is a compact and computationally efficient model that benefits from a well-designed network architecture, an optimized training loss objective, and a deterministic sampling process with short time steps. Extensive experiments demonstrate that DocDiff achieves state-of-the-art (SOTA) performance on multiple benchmark datasets, and can significantly enhance the readability and recognizability of degraded document images. Furthermore, our proposed HRR module in pre-trained DocDiff is plug-and-play and ready-to-use, with only 4.17M parameters. It greatly sharpens the text edges generated by SOTA deblurring methods without additional joint training. Available codes: https://github.com/Royalvice/DocDiff