 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMPA: Evaluating Persona-Aligned Empathy as a Process
Feb 28, 2026Evaluating persona-aligned empathy in LLM-based dialogue agents remains challenging. User states are latent, feedback is sparse and difficult to verify in situ, and seemingly supportive turns can still accumulate into trajectories that drift from persona-specific needs. We introduce EMPA, a process-oriented framework that evaluates persona-aligned support as sustained intervention rather than isolated replies. EMPA distills real interactions into controllable, psychologically grounded scenarios, couples them with an open-ended multi-agent sandbox that exposes strategic adaptation and failure modes, and scores trajectories in a latent psychological space by directional alignment, cumulative impact, and stability. The resulting signals and metrics support reproducible comparison and optimization of long-horizon empathic behavior, and they extend to other agent settings shaped by latent dynamics and weak, hard-to-verify feedback.
UniMM-V2X: MoE-Enhanced Multi-Level Fusion for End-to-End Cooperative Autonomous Driving
Nov 12, 2025Autonomous driving holds transformative potential but remains fundamentally constrained by the limited perception and isolated decision-making with standalone intelligence. While recent multi-agent approaches introduce cooperation, they often focus merely on perception-level tasks, overlooking the alignment with downstream planning and control, or fall short in leveraging the full capacity of the recent emerging end-to-end autonomous driving. In this paper, we present UniMM-V2X, a novel end-to-end multi-agent framework that enables hierarchical cooperation across perception, prediction, and planning. At the core of our framework is a multi-level fusion strategy that unifies perception and prediction cooperation, allowing agents to share queries and reason cooperatively for consistent and safe decision-making. To adapt to diverse downstream tasks and further enhance the quality of multi-level fusion, we incorporate a Mixture-of-Experts (MoE) architecture to dynamically enhance the BEV representations. We further extend MoE into the decoder to better capture diverse motion patterns. Extensive experiments on the DAIR-V2X dataset demonstrate our approach achieves state-of-the-art (SOTA) performance with a 39.7% improvement in perception accuracy, a 7.2% reduction in prediction error, and a 33.2% improvement in planning performance compared with UniV2X, showcasing the strength of our MoE-enhanced multi-level cooperative paradigm.
WHALES: A Multi-agent Scheduling Dataset for Enhanced Cooperation in Autonomous Driving
Nov 20, 2024Achieving high levels of safety and reliability in autonomous driving remains a critical challenge, especially due to occlusion and limited perception ranges in standalone systems. Cooperative perception among vehicles offers a promising solution, but existing research is hindered by datasets with a limited number of agents. Scaling up the number of cooperating agents is non-trivial and introduces significant computational and technical hurdles that have not been addressed in previous works. To bridge this gap, we present Wireless enHanced Autonomous vehicles with Large number of Engaged agentS (WHALES), a dataset generated using CARLA simulator that features an unprecedented average of 8.4 agents per driving sequence. In addition to providing the largest number of agents and viewpoints among autonomous driving datasets, WHALES records agent behaviors, enabling cooperation across multiple tasks. This expansion allows for new supporting tasks in cooperative perception. As a demonstration, we conduct experiments on agent scheduling task, where the ego agent selects one of multiple candidate agents to cooperate with, optimizing perception gains in autonomous driving. The WHALES dataset and codebase can be found at https://github.com/chensiweiTHU/WHALES.
TextDiff: Mask-Guided Residual Diffusion Models for Scene Text Image Super-Resolution
Aug 13, 2023
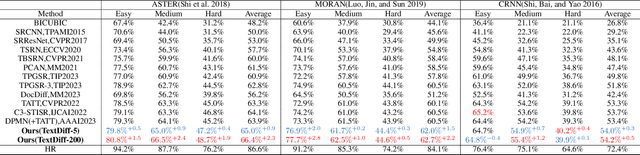

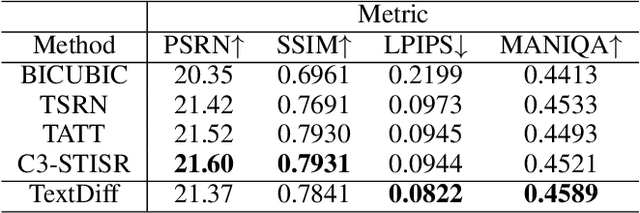
The goal of scene text image super-resolution is to reconstruct high-resolution text-line images from unrecognizable low-resolution inputs. The existing methods relying on the optimization of pixel-level loss tend to yield text edges that exhibit a notable degree of blurring, thereby exerting a substantial impact on both the readability and recognizability of the text. To address these issues, we propose TextDiff, the first diffusion-based framework tailored for scene text image super-resolution. It contains two modules: the Text Enhancement Module (TEM) and the Mask-Guided Residual Diffusion Module (MRD). The TEM generates an initial deblurred text image and a mask that encodes the spatial location of the text. The MRD is responsible for effectively sharpening the text edge by modeling the residuals between the ground-truth images and the initial deblurred images. Extensive experiments demonstrate that our TextDiff achieves state-of-the-art (SOTA) performance on public benchmark datasets and can improve the readability of scene text images. Moreover, our proposed MRD module is plug-and-play that effectively sharpens the text edges produced by SOTA methods. This enhancement not only improves the readability and recognizability of the results generated by SOTA methods but also does not require any additional joint training. Available Codes:https://github.com/Lenubolim/TextDiff.