 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Modular Integration of "AI + Architecture" Pedagogy in Undergraduate Design Education: A Case Study of Architectural Design III/IV Courses at Zhejiang University
Dec 14, 2025This study investigates AI integration in architectural education through a teaching experiment in Zhejiang University's 2024-25 grade three undergraduate design studio. Adopting a dual-module framework (20-hour AI training + embedded ethics discussions), the course introduced deep learning models, LLMs, AIGC, LoRA, and ComfyUI while maintaining the original curriculum structure, supported by dedicated technical instructors. Findings demonstrate the effectiveness of phased guidance, balanced technical-ethical approaches, and institutional support. The model improved students' digital skills and strategic cognition while addressing AI ethics, providing a replicable approach combining technical and critical learning in design education.
CorrDiff: Adaptive Delay-aware Detector with Temporal Cue Inputs for Real-time Object Detection
Jan 09, 2025



Real-time object detection takes an essential part in the decision-making process of numerous real-world applications, including collision avoidance and path planning in autonomous driving systems. This paper presents a novel real-time streaming perception method named CorrDiff, designed to tackle the challenge of delays in real-time detection systems. The main contribution of CorrDiff lies in its adaptive delay-aware detector, which is able to utilize runtime-estimated temporal cues to predict objects' locations for multiple future frames, and selectively produce predictions that matches real-world time, effectively compensating for any communication and computational delays. The proposed model outperforms current state-of-the-art methods by leveraging motion estimation and feature enhancement, both for 1) single-frame detection for the current frame or the next frame, in terms of the metric mAP, and 2) the prediction for (multiple) future frame(s), in terms of the metric sAP (The sAP metric is to evaluate object detection algorithms in streaming scenarios, factoring in both latency and accuracy). It demonstrates robust performance across a range of devices, from powerful Tesla V100 to modest RTX 2080Ti, achieving the highest level of perceptual accuracy on all platforms. Unlike most state-of-the-art methods that struggle to complete computation within a single frame on less powerful devices, CorrDiff meets the stringent real-time processing requirements on all kinds of devices. The experimental results emphasize the system's adaptability and its potential to significantly improve the safety and reliability for many real-world systems, such as autonomous driving. Our code is completely open-sourced and is available at https://anonymous.4open.science/r/CorrDiff.
DirectL: Efficient Radiance Fields Rendering for 3D Light Field Displays
Jul 19, 2024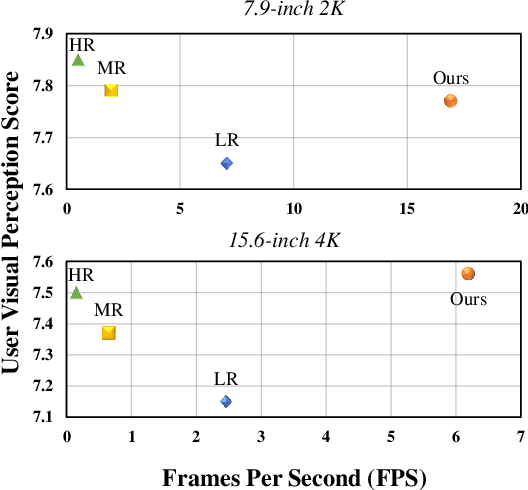
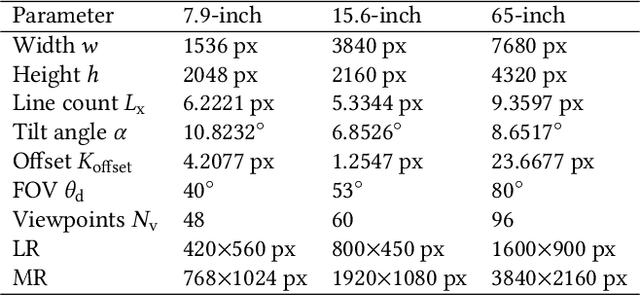
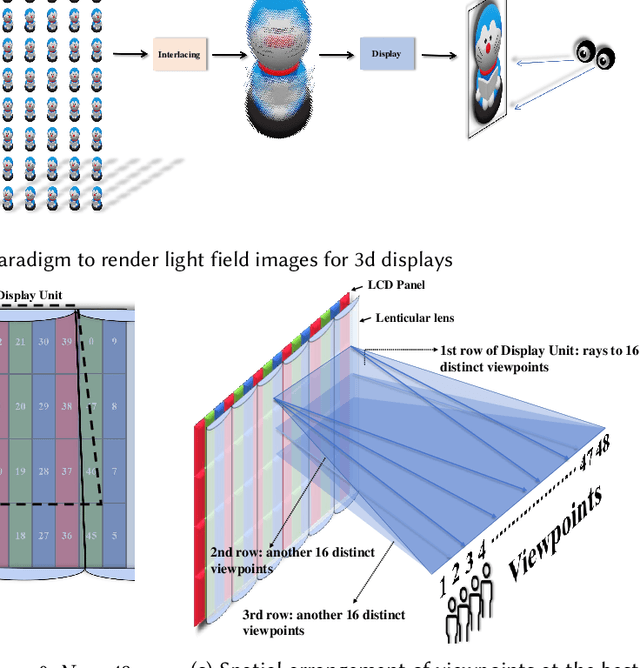

Autostereoscopic display, despite decades of development, has not achieved extensive application, primarily due to the daunting challenge of 3D content creation for non-specialists. The emergence of Radiance Field as an innovative 3D representation has markedly revolutionized the domains of 3D reconstruction and generation. This technology greatly simplifies 3D content creation for common users, broadening the applicability of Light Field Displays (LFDs). However, the combination of these two fields remains largely unexplored. The standard paradigm to create optimal content for parallax-based light field displays demands rendering at least 45 slightly shifted views preferably at high resolution per frame, a substantial hurdle for real-time rendering. We introduce DirectL, a novel rendering paradigm for Radiance Fields on 3D displays. We thoroughly analyze the interweaved mapping of spatial rays to screen subpixels, precisely determine the light rays entering the human eye, and propose subpixel repurposing to significantly reduce the pixel count required for rendering. Tailored for the two predominant radiance fields--Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS), we propose corresponding optimized rendering pipelines that directly render the light field images instead of multi-view images. Extensive experiments across various displays and user study demonstrate that DirectL accelerates rendering by up to 40 times compared to the standard paradigm without sacrificing visual quality. Its rendering process-only modification allows seamless integration into subsequent radiance field tasks. Finally, we integrate DirectL into diverse applications, showcasing the stunning visual experiences and the synergy between LFDs and Radiance Fields, which unveils tremendous potential for commercialization applications. \href{direct-l.github.io}{\textbf{Project Homepage}
DocDiff: Document Enhancement via Residual Diffusion Models
May 06, 2023Removing degradation from document images not only improves their visual quality and readability, but also enhances the performance of numerous automated document analysis and recognition tasks. However, existing regression-based methods optimized for pixel-level distortion reduction tend to suffer from significant loss of high-frequency information, leading to distorted and blurred text edges. To compensate for this major deficiency, we propose DocDiff, the first diffusion-based framework specifically designed for diverse challenging document enhancement problems, including document deblurring, denoising, and removal of watermarks and seals. DocDiff consists of two modules: the Coarse Predictor (CP), which is responsible for recovering the primary low-frequency content, and the High-Frequency Residual Refinement (HRR) module, which adopts the diffusion models to predict the residual (high-frequency information, including text edges), between the ground-truth and the CP-predicted image. DocDiff is a compact and computationally efficient model that benefits from a well-designed network architecture, an optimized training loss objective, and a deterministic sampling process with short time steps. Extensive experiments demonstrate that DocDiff achieves state-of-the-art (SOTA) performance on multiple benchmark datasets, and can significantly enhance the readability and recognizability of degraded document images. Furthermore, our proposed HRR module in pre-trained DocDiff is plug-and-play and ready-to-use, with only 4.17M parameters. It greatly sharpens the text edges generated by SOTA deblurring methods without additional joint training. Available codes: https://github.com/Royalvice/DocDiff
Adaptive Region Embedding for Text Classification
May 28, 2019



Deep learning models such as convolutional neural networks and recurrent networks are widely applied in text classification. In spite of their great success, most deep learning models neglect the importance of modeling context information, which is crucial to understanding texts. In this work, we propose the Adaptive Region Embedding to learn context representation to improve text classification. Specifically, a metanetwork is learned to generate a context matrix for each region, and each word interacts with its corresponding context matrix to produce the regional representation for further classification. Compared to previous models that are designed to capture context information, our model contains less parameters and is more flexible. We extensively evaluate our method on 8 benchmark datasets for text classification. The experimental results prove that our method achieves state-of-the-art performances and effectively avoids word ambiguity.