 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Few-Shot Learning for Pedestrian Attribute Recognition
Jun 02, 2019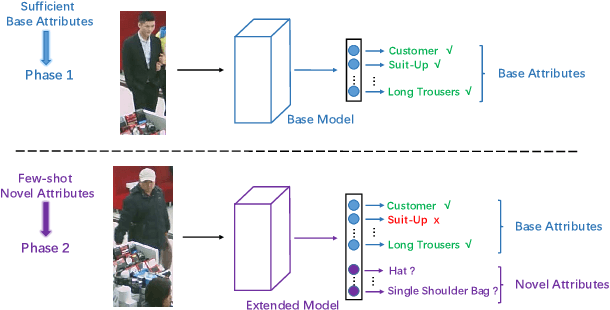
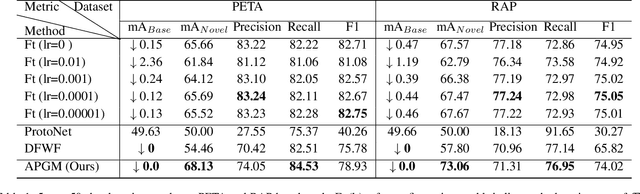
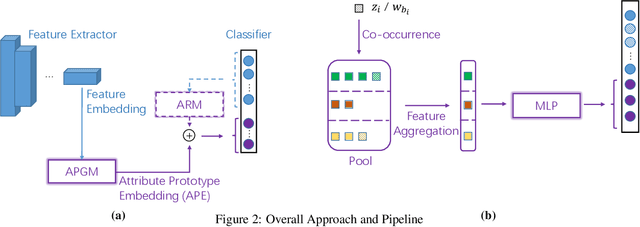

Pedestrian attribute recognition has received increasing attention due to its important role in video surveillance applications. However, most existing methods are designed for a fixed set of attributes. They are unable to handle the incremental few-shot learning scenario, i.e. adapting a well-trained model to newly added attributes with scarce data, which commonly exists in the real world. In this work, we present a meta learning based method to address this issue. The core of our framework is a meta architecture capable of disentangling multiple attribute information and generalizing rapidly to new coming attributes. By conducting extensive experiments on the benchmark dataset PETA and RAP under the incremental few-shot setting, we show that our method is able to perform the task with competitive performances and low resource requirements.
Adaptive Region Embedding for Text Classification
May 28, 2019



Deep learning models such as convolutional neural networks and recurrent networks are widely applied in text classification. In spite of their great success, most deep learning models neglect the importance of modeling context information, which is crucial to understanding texts. In this work, we propose the Adaptive Region Embedding to learn context representation to improve text classification. Specifically, a metanetwork is learned to generate a context matrix for each region, and each word interacts with its corresponding context matrix to produce the regional representation for further classification. Compared to previous models that are designed to capture context information, our model contains less parameters and is more flexible. We extensively evaluate our method on 8 benchmark datasets for text classification. The experimental results prove that our method achieves state-of-the-art performances and effectively avoids word ambiguity.