 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAC: A Conversion Rate Prediction Benchmark Featuring Labels Under Multiple Attribution Mechanisms
Mar 02, 2026Multi-attribution learning (MAL), which enhances model performance by learning from conversion labels yielded by multiple attribution mechanisms, has emerged as a promising learning paradigm for conversion rate (CVR) prediction. However, the conversion labels in public CVR datasets are generated by a single attribution mechanism, hindering the development of MAL approaches. To address this data gap, we establish the Multi-Attribution Benchmark (MAC), the first public CVR dataset featuring labels from multiple attribution mechanisms. Besides, to promote reproducible research on MAL, we develop PyMAL, an open-source library covering a wide array of baseline methods. We conduct comprehensive experimental analyses on MAC and reveal three key insights: (1) MAL brings consistent performance gains across different attribution settings, especially for users featuring long conversion paths. (2) The performance growth scales up with objective complexity in most settings; however, when predicting first-click conversion targets, simply adding auxiliary objectives is counterproductive, underscoring the necessity of careful selection of auxiliary objectives. (3) Two architectural design principles are paramount: first, to fully learn the multi-attribution knowledge, and second, to fully leverage this knowledge to serve the main task. Motivated by these findings, we propose Mixture of Asymmetric Experts (MoAE), an effective MAL approach incorporating multi-attribution knowledge learning and main task-centric knowledge utilization. Experiments on MAC show that MoAE substantially surpasses the existing state-of-the-art MAL method. We believe that our benchmark and insights will foster future research in the MAL field. Our MAC benchmark and the PyMAL algorithm library are publicly available at https://github.com/alimama-tech/PyMAL.
EST: Towards Efficient Scaling Laws in Click-Through Rate Prediction via Unified Modeling
Feb 11, 2026Efficiently scaling industrial Click-Through Rate (CTR) prediction has recently attracted significant research attention. Existing approaches typically employ early aggregation of user behaviors to maintain efficiency. However, such non-unified or partially unified modeling creates an information bottleneck by discarding fine-grained, token-level signals essential for unlocking scaling gains. In this work, we revisit the fundamental distinctions between CTR prediction and Large Language Models (LLMs), identifying two critical properties: the asymmetry in information density between behavioral and non-behavioral features, and the modality-specific priors of content-rich signals. Accordingly, we propose the Efficiently Scalable Transformer (EST), which achieves fully unified modeling by processing all raw inputs in a single sequence without lossy aggregation. EST integrates two modules: Lightweight Cross-Attention (LCA), which prunes redundant self-interactions to focus on high-impact cross-feature dependencies, and Content Sparse Attention (CSA), which utilizes content similarity to dynamically select high-signal behaviors. Extensive experiments show that EST exhibits a stable and efficient power-law scaling relationship, enabling predictable performance gains with model scale. Deployed on Taobao's display advertising platform, EST significantly outperforms production baselines, delivering a 3.27\% RPM (Revenue Per Mile) increase and a 1.22\% CTR lift, establishing a practical pathway for scalable industrial CTR prediction models.
VQL: An End-to-End Context-Aware Vector Quantization Attention for Ultra-Long User Behavior Modeling
Aug 23, 2025In large-scale recommender systems, ultra-long user behavior sequences encode rich signals of evolving interests. Extending sequence length generally improves accuracy, but directly modeling such sequences in production is infeasible due to latency and memory constraints. Existing solutions fall into two categories: (1) top-k retrieval, which truncates the sequence and may discard most attention mass when L >> k; and (2) encoder-based compression, which preserves coverage but often over-compresses and fails to incorporate key context such as temporal gaps or target-aware signals. Neither class achieves a good balance of low-loss compression, context awareness, and efficiency. We propose VQL, a context-aware Vector Quantization Attention framework for ultra-long behavior modeling, with three innovations. (1) Key-only quantization: only attention keys are quantized, while values remain intact; we prove that softmax normalization yields an error bound independent of sequence length, and a codebook loss directly supervises quantization quality. This also enables L-free inference via offline caches. (2) Multi-scale quantization: attention heads are partitioned into groups, each with its own small codebook, which reduces quantization error while keeping cache size fixed. (3) Efficient context injection: static features (e.g., item category, modality) are directly integrated, and relative position is modeled via a separable temporal kernel. All context is injected without enlarging the codebook, so cached representations remain query-independent. Experiments on three large-scale datasets (KuaiRand-1K, KuaiRec, TMALL) show that VQL consistently outperforms strong baselines, achieving higher accuracy while reducing inference latency, establishing a new state of the art in balancing accuracy and efficiency for ultra-long sequence recommendation.
CHIME: A Compressive Framework for Holistic Interest Modeling
Apr 09, 2025Modeling holistic user interests is important for improving recommendation systems but is challenged by high computational cost and difficulty in handling diverse information with full behavior context. Existing search-based methods might lose critical signals during behavior selection. To overcome these limitations, we propose CHIME: A Compressive Framework for Holistic Interest Modeling. It uses adapted large language models to encode complete user behaviors with heterogeneous inputs. We introduce multi-granular contrastive learning objectives to capture both persistent and transient interest patterns and apply residual vector quantization to generate compact embeddings. CHIME demonstrates superior ranking performance across diverse datasets, establishing a robust solution for scalable holistic interest modeling in recommendation systems.
BBQRec: Behavior-Bind Quantization for Multi-Modal Sequential Recommendation
Apr 09, 2025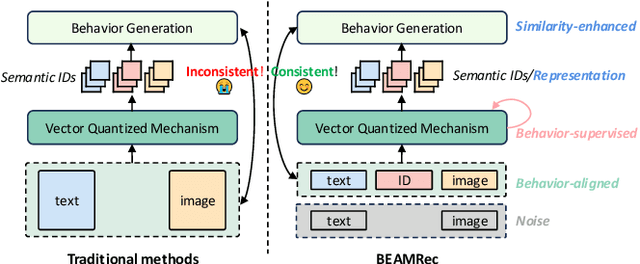
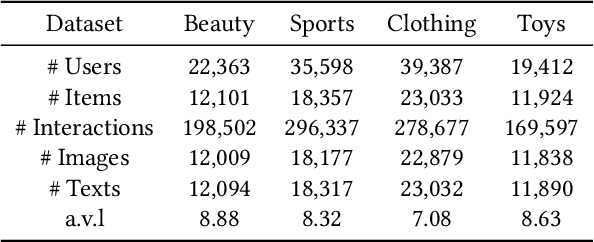
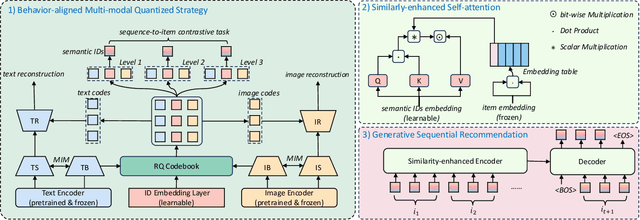
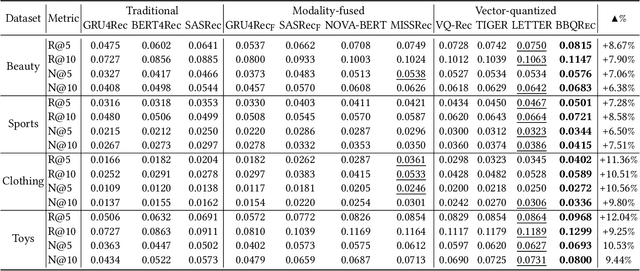
Multi-modal sequential recommendation systems leverage auxiliary signals (e.g., text, images) to alleviate data sparsity in user-item interactions. While recent methods exploit large language models to encode modalities into discrete semantic IDs for autoregressive prediction, we identify two critical limitations: (1) Existing approaches adopt fragmented quantization, where modalities are independently mapped to semantic spaces misaligned with behavioral objectives, and (2) Over-reliance on semantic IDs disrupts inter-modal semantic coherence, thereby weakening the expressive power of multi-modal representations for modeling diverse user preferences. To address these challenges, we propose a Behavior-Bind multi-modal Quantization for Sequential Recommendation (BBQRec for short) featuring dual-aligned quantization and semantics-aware sequence modeling. First, our behavior-semantic alignment module disentangles modality-agnostic behavioral patterns from noisy modality-specific features through contrastive codebook learning, ensuring semantic IDs are inherently tied to recommendation tasks. Second, we design a discretized similarity reweighting mechanism that dynamically adjusts self-attention scores using quantized semantic relationships, preserving multi-modal synergies while avoiding invasive modifications to the sequence modeling architecture. Extensive evaluations across four real-world benchmarks demonstrate BBQRec's superiority over the state-of-the-art baselines.
Group channel pruning and spatial attention distilling for object detection
Jun 02, 2023Due to the over-parameterization of neural networks, many model compression methods based on pruning and quantization have emerged. They are remarkable in reducing the size, parameter number, and computational complexity of the model. However, most of the models compressed by such methods need the support of special hardware and software, which increases the deployment cost. Moreover, these methods are mainly used in classification tasks, and rarely directly used in detection tasks. To address these issues, for the object detection network we introduce a three-stage model compression method: dynamic sparse training, group channel pruning, and spatial attention distilling. Firstly, to select out the unimportant channels in the network and maintain a good balance between sparsity and accuracy, we put forward a dynamic sparse training method, which introduces a variable sparse rate, and the sparse rate will change with the training process of the network. Secondly, to reduce the effect of pruning on network accuracy, we propose a novel pruning method called group channel pruning. In particular, we divide the network into multiple groups according to the scales of the feature layer and the similarity of module structure in the network, and then we use different pruning thresholds to prune the channels in each group. Finally, to recover the accuracy of the pruned network, we use an improved knowledge distillation method for the pruned network. Especially, we extract spatial attention information from the feature maps of specific scales in each group as knowledge for distillation. In the experiments, we use YOLOv4 as the object detection network and PASCAL VOC as the training dataset. Our method reduces the parameters of the model by 64.7 % and the calculation by 34.9%.
* Appl Intell
Capturing Conversion Rate Fluctuation during Sales Promotions: A Novel Historical Data Reuse Approach
May 22, 2023



Conversion rate (CVR) prediction is one of the core components in online recommender systems, and various approaches have been proposed to obtain accurate and well-calibrated CVR estimation. However, we observe that a well-trained CVR prediction model often performs sub-optimally during sales promotions. This can be largely ascribed to the problem of the data distribution shift, in which the conventional methods no longer work. To this end, we seek to develop alternative modeling techniques for CVR prediction. Observing similar purchase patterns across different promotions, we propose reusing the historical promotion data to capture the promotional conversion patterns. Herein, we propose a novel \textbf{H}istorical \textbf{D}ata \textbf{R}euse (\textbf{HDR}) approach that first retrieves historically similar promotion data and then fine-tunes the CVR prediction model with the acquired data for better adaptation to the promotion mode. HDR consists of three components: an automated data retrieval module that seeks similar data from historical promotions, a distribution shift correction module that re-weights the retrieved data for better aligning with the target promotion, and a TransBlock module that quickly fine-tunes the original model for better adaptation to the promotion mode. Experiments conducted with real-world data demonstrate the effectiveness of HDR, as it improves both ranking and calibration metrics to a large extent. HDR has also been deployed on the display advertising system in Alibaba, bringing a lift of $9\%$ RPM and $16\%$ CVR during Double 11 Sales in 2022.
Adapting to Online Label Shift with Provable Guarantees
Jul 05, 2022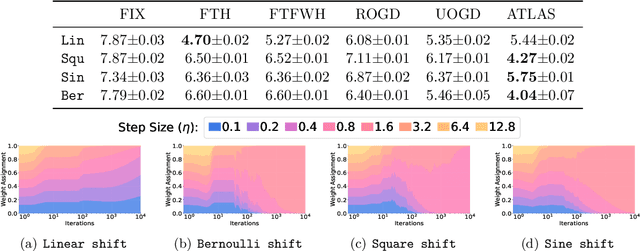
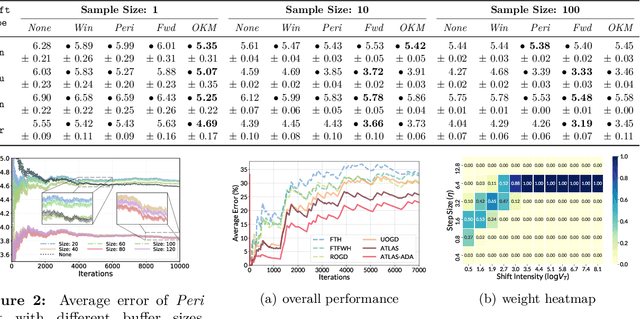
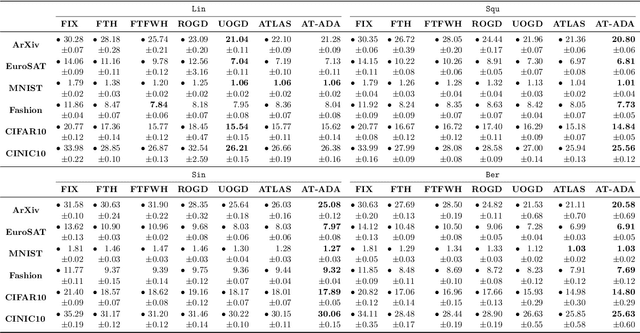
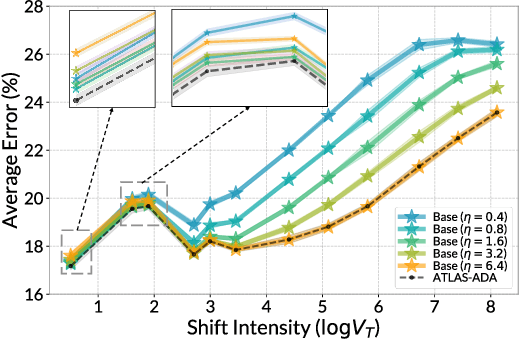
The standard supervised learning paradigm works effectively when training data shares the same distribution as the upcoming testing samples. However, this assumption is often violated in real-world applications, especially when testing data appear in an online fashion. In this paper, we formulate and investigate the problem of online label shift (OLaS): the learner trains an initial model from the labeled offline data and then deploys it to an unlabeled online environment where the underlying label distribution changes over time but the label-conditional density does not. The non-stationarity nature and the lack of supervision make the problem challenging to be tackled. To address the difficulty, we construct a new unbiased risk estimator that utilizes the unlabeled data, which exhibits many benign properties albeit with potential non-convexity. Building upon that, we propose novel online ensemble algorithms to deal with the non-stationarity of the environments. Our approach enjoys optimal dynamic regret, indicating that the performance is competitive with a clairvoyant who knows the online environments in hindsight and then chooses the best decision for each round. The obtained dynamic regret bound scales with the intensity and pattern of label distribution shift, hence exhibiting the adaptivity in the OLaS problem. Extensive experiments are conducted to validate the effectiveness and support our theoretical findings.
Fake Generated Painting Detection via Frequency Analysis
Mar 05, 2020
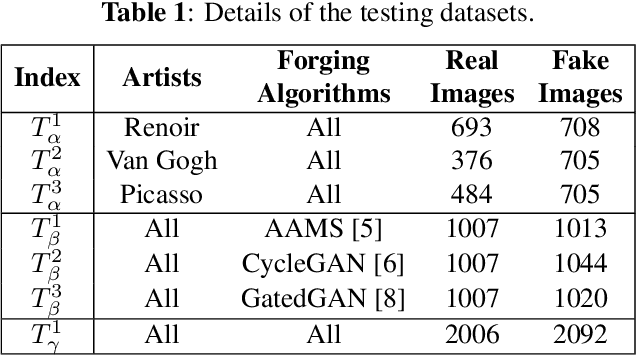
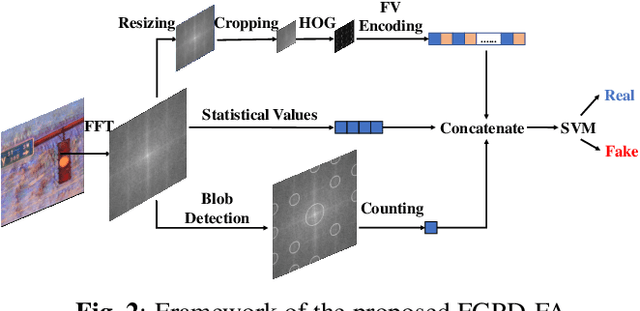

With the development of deep neural networks, digital fake paintings can be generated by various style transfer algorithms.To detect the fake generated paintings, we analyze the fake generated and real paintings in Fourier frequency domain and observe statistical differences and artifacts. Based on our observations, we propose Fake Generated Painting Detection via Frequency Analysis (FGPD-FA) by extracting three types of features in frequency domain. Besides, we also propose a digital fake painting detection database for assessing the proposed method. Experimental results demonstrate the excellence of the proposed method in different testing conditions.
Recognition of Pyralidae Insects Using Intelligent Monitoring Autonomous Robot Vehicle in Natural Farm Scene
Mar 26, 2019


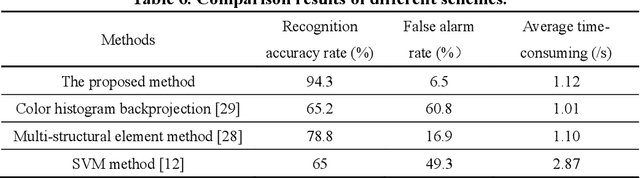
The Pyralidae pests, such as corn borer and rice leaf roller, are main pests in economic crops. The timely detection and identification of Pyralidae pests is a critical task for agriculturists and farmers. However, the traditional identification of pests by humans is labor intensive and inefficient. To tackle the challenges, a pest monitoring autonomous robot vehicle and a method to recognize Pyralidae pests are presented in this paper. Firstly, the robot on autonomous vehicle collects images by performing camera sensing in natural farm scene. Secondly, the total probability image can be obtained by using inverse histogram mapping, and then the object contour of Pyralidae pests can be extracted quickly and accurately with the constrained Otsu method. Finally, by employing Hu moment and the perimeter and area characteristics, the correct contours of objects can be drawn, and the recognition results can be obtained by comparing them with the reference templates of Pyralidae pests. Additionally, the moving speed of the mechanical arms on the vehicle can be adjusted adaptively by interacting with the recognition algorithm. The experimental results demonstrate that the robot vehicle can automatically capture pest images, and can achieve 94.3$\%$ recognition accuracy in natural farm planting scene.