 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCM-Eval: An Expert-Level Dynamic and Extensible Benchmark for Traditional Chinese Medicine
Nov 10, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in modern medicine, yet their application in Traditional Chinese Medicine (TCM) remains severely limited by the absence of standardized benchmarks and the scarcity of high-quality training data. To address these challenges, we introduce TCM-Eval, the first dynamic and extensible benchmark for TCM, meticulously curated from national medical licensing examinations and validated by TCM experts. Furthermore, we construct a large-scale training corpus and propose Self-Iterative Chain-of-Thought Enhancement (SI-CoTE) to autonomously enrich question-answer pairs with validated reasoning chains through rejection sampling, establishing a virtuous cycle of data and model co-evolution. Using this enriched training data, we develop ZhiMingTang (ZMT), a state-of-the-art LLM specifically designed for TCM, which significantly exceeds the passing threshold for human practitioners. To encourage future research and development, we release a public leaderboard, fostering community engagement and continuous improvement.
RepoDebug: Repository-Level Multi-Task and Multi-Language Debugging Evaluation of Large Language Models
Sep 04, 2025Large Language Models (LLMs) have exhibited significant proficiency in code debugging, especially in automatic program repair, which may substantially reduce the time consumption of developers and enhance their efficiency. Significant advancements in debugging datasets have been made to promote the development of code debugging. However, these datasets primarily focus on assessing the LLM's function-level code repair capabilities, neglecting the more complex and realistic repository-level scenarios, which leads to an incomplete understanding of the LLM's challenges in repository-level debugging. While several repository-level datasets have been proposed, they often suffer from limitations such as limited diversity of tasks, languages, and error types. To mitigate this challenge, this paper introduces RepoDebug, a multi-task and multi-language repository-level code debugging dataset with 22 subtypes of errors that supports 8 commonly used programming languages and 3 debugging tasks. Furthermore, we conduct evaluation experiments on 10 LLMs, where Claude 3.5 Sonnect, the best-performing model, still cannot perform well in repository-level debugging.
ToolSpectrum : Towards Personalized Tool Utilization for Large Language Models
May 19, 2025

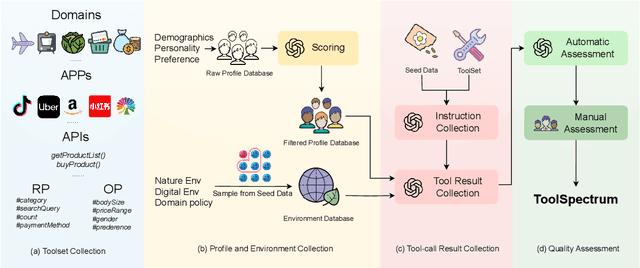

While integrating external tools into large language models (LLMs) enhances their ability to access real-time information and domain-specific services, existing approaches focus narrowly on functional tool selection following user instructions, overlooking the context-aware personalization in tool selection. This oversight leads to suboptimal user satisfaction and inefficient tool utilization, particularly when overlapping toolsets require nuanced selection based on contextual factors. To bridge this gap, we introduce ToolSpectrum, a benchmark designed to evaluate LLMs' capabilities in personalized tool utilization. Specifically, we formalize two key dimensions of personalization, user profile and environmental factors, and analyze their individual and synergistic impacts on tool utilization. Through extensive experiments on ToolSpectrum, we demonstrate that personalized tool utilization significantly improves user experience across diverse scenarios. However, even state-of-the-art LLMs exhibit the limited ability to reason jointly about user profiles and environmental factors, often prioritizing one dimension at the expense of the other. Our findings underscore the necessity of context-aware personalization in tool-augmented LLMs and reveal critical limitations for current models. Our data and code are available at https://github.com/Chengziha0/ToolSpectrum.
Generalizable AI-Generated Image Detection Based on Fractal Self-Similarity in the Spectrum
Mar 11, 2025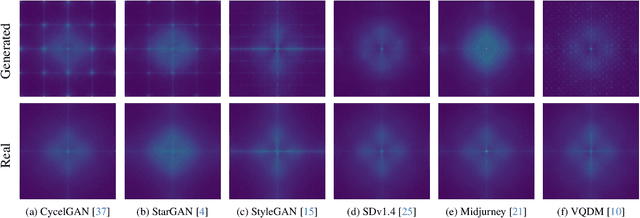
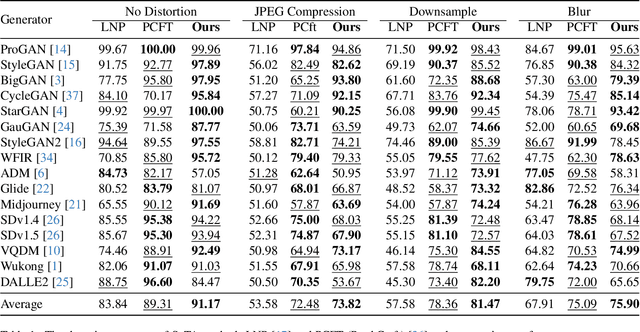
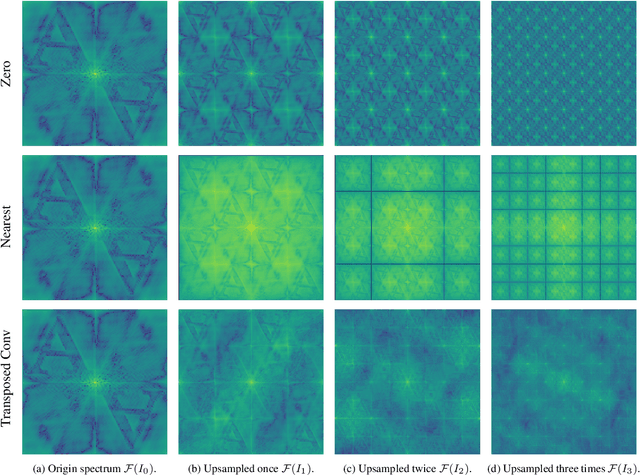
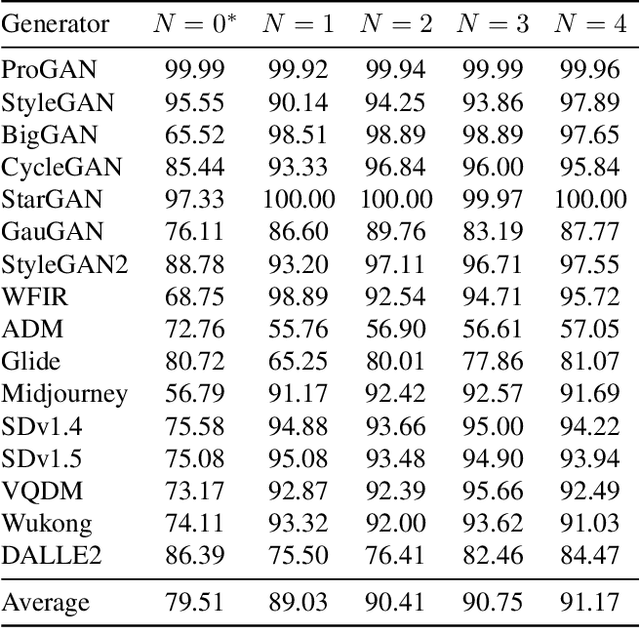
The generalization performance of AI-generated image detection remains a critical challenge. Although most existing methods perform well in detecting images from generative models included in the training set, their accuracy drops significantly when faced with images from unseen generators. To address this limitation, we propose a novel detection method based on the fractal self-similarity of the spectrum, a common feature among images generated by different models. Specifically, we demonstrate that AI-generated images exhibit fractal-like spectral growth through periodic extension and low-pass filtering. This observation motivates us to exploit the similarity among different fractal branches of the spectrum. Instead of directly analyzing the spectrum, our method mitigates the impact of varying spectral characteristics across different generators, improving detection performance for images from unseen models. Experiments on a public benchmark demonstrated the generalized detection performance across both GANs and diffusion models.
Deepfake Detection via Knowledge Injection
Mar 04, 2025
Deepfake detection technologies become vital because current generative AI models can generate realistic deepfakes, which may be utilized in malicious purposes. Existing deepfake detection methods either rely on developing classification methods to better fit the distributions of the training data, or exploiting forgery synthesis mechanisms to learn a more comprehensive forgery distribution. Unfortunately, these methods tend to overlook the essential role of real data knowledge, which limits their generalization ability in processing the unseen real and fake data. To tackle these challenges, in this paper, we propose a simple and novel approach, named Knowledge Injection based deepfake Detection (KID), by constructing a multi-task learning based knowledge injection framework, which can be easily plugged into existing ViT-based backbone models, including foundation models. Specifically, a knowledge injection module is proposed to learn and inject necessary knowledge into the backbone model, to achieve a more accurate modeling of the distributions of real and fake data. A coarse-grained forgery localization branch is constructed to learn the forgery locations in a multi-task learning manner, to enrich the learned forgery knowledge for the knowledge injection module. Two layer-wise suppression and contrast losses are proposed to emphasize the knowledge of real data in the knowledge injection module, to further balance the portions of the real and fake knowledge. Extensive experiments have demonstrated that our KID possesses excellent compatibility with different scales of Vit-based backbone models, and achieves state-of-the-art generalization performance while enhancing the training convergence speed.
AED-PADA:Improving Generalizability of Adversarial Example Detection via Principal Adversarial Domain Adaptation
Apr 19, 2024Adversarial example detection, which can be conveniently applied in many scenarios, is important in the area of adversarial defense. Unfortunately, existing detection methods suffer from poor generalization performance, because their training process usually relies on the examples generated from a single known adversarial attack and there exists a large discrepancy between the training and unseen testing adversarial examples. To address this issue, we propose a novel method, named Adversarial Example Detection via Principal Adversarial Domain Adaptation (AED-PADA). Specifically, our approach identifies the Principal Adversarial Domains (PADs), i.e., a combination of features of the adversarial examples from different attacks, which possesses large coverage of the entire adversarial feature space. Then, we pioneer to exploit multi-source domain adaptation in adversarial example detection with PADs as source domains. Experiments demonstrate the superior generalization ability of our proposed AED-PADA. Note that this superiority is particularly achieved in challenging scenarios characterized by employing the minimal magnitude constraint for the perturbations.
LSP Framework: A Compensatory Model for Defeating Trigger Reverse Engineering via Label Smoothing Poisoning
Apr 19, 2024Deep neural networks are vulnerable to backdoor attacks. Among the existing backdoor defense methods, trigger reverse engineering based approaches, which reconstruct the backdoor triggers via optimizations, are the most versatile and effective ones compared to other types of methods. In this paper, we summarize and construct a generic paradigm for the typical trigger reverse engineering process. Based on this paradigm, we propose a new perspective to defeat trigger reverse engineering by manipulating the classification confidence of backdoor samples. To determine the specific modifications of classification confidence, we propose a compensatory model to compute the lower bound of the modification. With proper modifications, the backdoor attack can easily bypass the trigger reverse engineering based methods. To achieve this objective, we propose a Label Smoothing Poisoning (LSP) framework, which leverages label smoothing to specifically manipulate the classification confidences of backdoor samples. Extensive experiments demonstrate that the proposed work can defeat the state-of-the-art trigger reverse engineering based methods, and possess good compatibility with a variety of existing backdoor attacks.
Understanding Heterophily for Graph Neural Networks
Jan 17, 2024Graphs with heterophily have been regarded as challenging scenarios for Graph Neural Networks (GNNs), where nodes are connected with dissimilar neighbors through various patterns. In this paper, we present theoretical understandings of the impacts of different heterophily patterns for GNNs by incorporating the graph convolution (GC) operations into fully connected networks via the proposed Heterophilous Stochastic Block Models (HSBM), a general random graph model that can accommodate diverse heterophily patterns. Firstly, we show that by applying a GC operation, the separability gains are determined by two factors, i.e., the Euclidean distance of the neighborhood distributions and $\sqrt{\mathbb{E}\left[\operatorname{deg}\right]}$, where $\mathbb{E}\left[\operatorname{deg}\right]$ is the averaged node degree. It reveals that the impact of heterophily on classification needs to be evaluated alongside the averaged node degree. Secondly, we show that the topological noise has a detrimental impact on separability, which is equivalent to degrading $\mathbb{E}\left[\operatorname{deg}\right]$. Finally, when applying multiple GC operations, we show that the separability gains are determined by the normalized distance of the $l$-powered neighborhood distributions. It indicates that the nodes still possess separability as $l$ goes to infinity in a wide range of regimes. Extensive experiments on both synthetic and real-world data verify the effectiveness of our theory.
RFDforFin: Robust Deep Forgery Detection for GAN-generated Fingerprint Images
Aug 18, 2023



With the rapid development of the image generation technologies, the malicious abuses of the GAN-generated fingerprint images poses a significant threat to the public safety in certain circumstances. Although the existing universal deep forgery detection approach can be applied to detect the fake fingerprint images, they are easily attacked and have poor robustness. Meanwhile, there is no specifically designed deep forgery detection method for fingerprint images. In this paper, we propose the first deep forgery detection approach for fingerprint images, which combines unique ridge features of fingerprint and generation artifacts of the GAN-generated images, to the best of our knowledge. Specifically, we firstly construct a ridge stream, which exploits the grayscale variations along the ridges to extract unique fingerprint-specific features. Then, we construct a generation artifact stream, in which the FFT-based spectrums of the input fingerprint images are exploited, to extract more robust generation artifact features. At last, the unique ridge features and generation artifact features are fused for binary classification (\textit{i.e.}, real or fake). Comprehensive experiments demonstrate that our proposed approach is effective and robust with low complexities.
Common Knowledge Learning for Generating Transferable Adversarial Examples
Jul 01, 2023This paper focuses on an important type of black-box attacks, i.e., transfer-based adversarial attacks, where the adversary generates adversarial examples by a substitute (source) model and utilize them to attack an unseen target model, without knowing its information. Existing methods tend to give unsatisfactory adversarial transferability when the source and target models are from different types of DNN architectures (e.g. ResNet-18 and Swin Transformer). In this paper, we observe that the above phenomenon is induced by the output inconsistency problem. To alleviate this problem while effectively utilizing the existing DNN models, we propose a common knowledge learning (CKL) framework to learn better network weights to generate adversarial examples with better transferability, under fixed network architectures. Specifically, to reduce the model-specific features and obtain better output distributions, we construct a multi-teacher framework, where the knowledge is distilled from different teacher architectures into one student network. By considering that the gradient of input is usually utilized to generated adversarial examples, we impose constraints on the gradients between the student and teacher models, to further alleviate the output inconsistency problem and enhance the adversarial transferability. Extensive experiments demonstrate that our proposed work can significantly improve the adversarial transferability.