 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable AI-Generated Image Detection Based on Fractal Self-Similarity in the Spectrum
Mar 11, 2025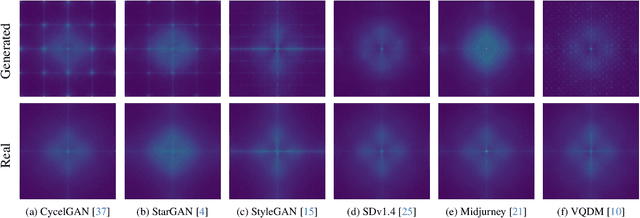
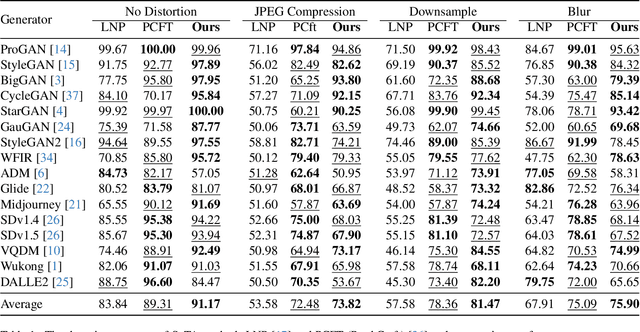
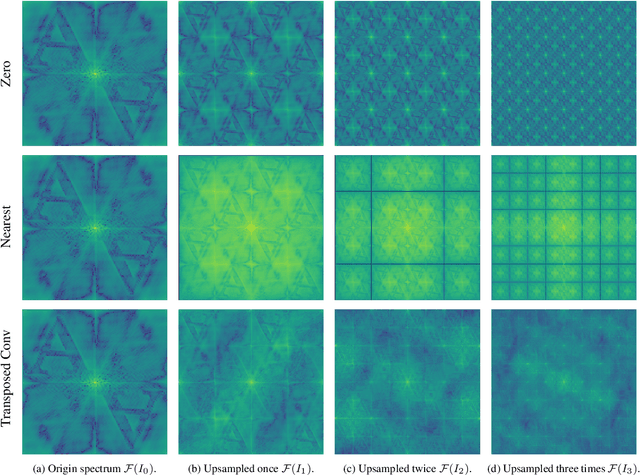
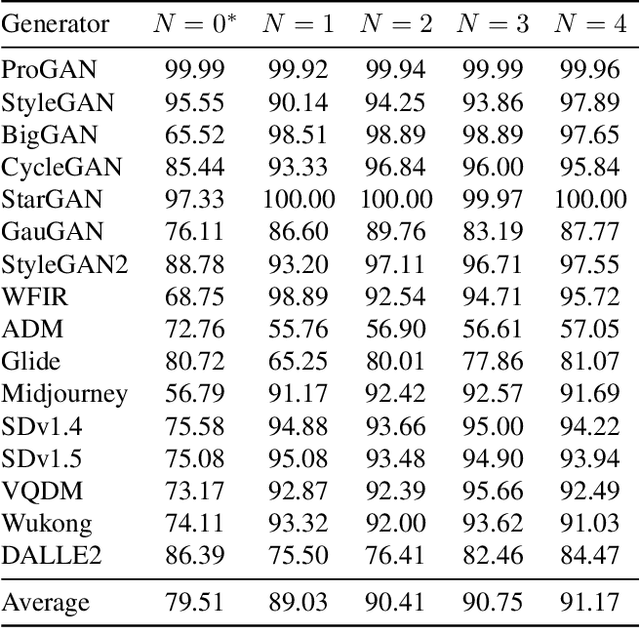
The generalization performance of AI-generated image detection remains a critical challenge. Although most existing methods perform well in detecting images from generative models included in the training set, their accuracy drops significantly when faced with images from unseen generators. To address this limitation, we propose a novel detection method based on the fractal self-similarity of the spectrum, a common feature among images generated by different models. Specifically, we demonstrate that AI-generated images exhibit fractal-like spectral growth through periodic extension and low-pass filtering. This observation motivates us to exploit the similarity among different fractal branches of the spectrum. Instead of directly analyzing the spectrum, our method mitigates the impact of varying spectral characteristics across different generators, improving detection performance for images from unseen models. Experiments on a public benchmark demonstrated the generalized detection performance across both GANs and diffusion models.
Deepfake Detection via Knowledge Injection
Mar 04, 2025
Deepfake detection technologies become vital because current generative AI models can generate realistic deepfakes, which may be utilized in malicious purposes. Existing deepfake detection methods either rely on developing classification methods to better fit the distributions of the training data, or exploiting forgery synthesis mechanisms to learn a more comprehensive forgery distribution. Unfortunately, these methods tend to overlook the essential role of real data knowledge, which limits their generalization ability in processing the unseen real and fake data. To tackle these challenges, in this paper, we propose a simple and novel approach, named Knowledge Injection based deepfake Detection (KID), by constructing a multi-task learning based knowledge injection framework, which can be easily plugged into existing ViT-based backbone models, including foundation models. Specifically, a knowledge injection module is proposed to learn and inject necessary knowledge into the backbone model, to achieve a more accurate modeling of the distributions of real and fake data. A coarse-grained forgery localization branch is constructed to learn the forgery locations in a multi-task learning manner, to enrich the learned forgery knowledge for the knowledge injection module. Two layer-wise suppression and contrast losses are proposed to emphasize the knowledge of real data in the knowledge injection module, to further balance the portions of the real and fake knowledge. Extensive experiments have demonstrated that our KID possesses excellent compatibility with different scales of Vit-based backbone models, and achieves state-of-the-art generalization performance while enhancing the training convergence speed.
AED-PADA:Improving Generalizability of Adversarial Example Detection via Principal Adversarial Domain Adaptation
Apr 19, 2024Adversarial example detection, which can be conveniently applied in many scenarios, is important in the area of adversarial defense. Unfortunately, existing detection methods suffer from poor generalization performance, because their training process usually relies on the examples generated from a single known adversarial attack and there exists a large discrepancy between the training and unseen testing adversarial examples. To address this issue, we propose a novel method, named Adversarial Example Detection via Principal Adversarial Domain Adaptation (AED-PADA). Specifically, our approach identifies the Principal Adversarial Domains (PADs), i.e., a combination of features of the adversarial examples from different attacks, which possesses large coverage of the entire adversarial feature space. Then, we pioneer to exploit multi-source domain adaptation in adversarial example detection with PADs as source domains. Experiments demonstrate the superior generalization ability of our proposed AED-PADA. Note that this superiority is particularly achieved in challenging scenarios characterized by employing the minimal magnitude constraint for the perturbations.
LSP Framework: A Compensatory Model for Defeating Trigger Reverse Engineering via Label Smoothing Poisoning
Apr 19, 2024Deep neural networks are vulnerable to backdoor attacks. Among the existing backdoor defense methods, trigger reverse engineering based approaches, which reconstruct the backdoor triggers via optimizations, are the most versatile and effective ones compared to other types of methods. In this paper, we summarize and construct a generic paradigm for the typical trigger reverse engineering process. Based on this paradigm, we propose a new perspective to defeat trigger reverse engineering by manipulating the classification confidence of backdoor samples. To determine the specific modifications of classification confidence, we propose a compensatory model to compute the lower bound of the modification. With proper modifications, the backdoor attack can easily bypass the trigger reverse engineering based methods. To achieve this objective, we propose a Label Smoothing Poisoning (LSP) framework, which leverages label smoothing to specifically manipulate the classification confidences of backdoor samples. Extensive experiments demonstrate that the proposed work can defeat the state-of-the-art trigger reverse engineering based methods, and possess good compatibility with a variety of existing backdoor attacks.