 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Unimodal Shortcuts: MLLMs as Cross-Modal Reasoners for Grounded Named Entity Recognition
Feb 04, 2026Grounded Multimodal Named Entity Recognition (GMNER) aims to extract text-based entities, assign them semantic categories, and ground them to corresponding visual regions. In this work, we explore the potential of Multimodal Large Language Models (MLLMs) to perform GMNER in an end-to-end manner, moving beyond their typical role as auxiliary tools within cascaded pipelines. Crucially, our investigation reveals a fundamental challenge: MLLMs exhibit $\textbf{modality bias}$, including visual bias and textual bias, which stems from their tendency to take unimodal shortcuts rather than rigorous cross-modal verification. To address this, we propose Modality-aware Consistency Reasoning ($\textbf{MCR}$), which enforces structured cross-modal reasoning through Multi-style Reasoning Schema Injection (MRSI) and Constraint-guided Verifiable Optimization (CVO). MRSI transforms abstract constraints into executable reasoning chains, while CVO empowers the model to dynamically align its reasoning trajectories with Group Relative Policy Optimization (GRPO). Experiments on GMNER and visual grounding tasks demonstrate that MCR effectively mitigates modality bias and achieves superior performance compared to existing baselines.
Beyond Literal Mapping: Benchmarking and Improving Non-Literal Translation Evaluation
Jan 12, 2026Large Language Models (LLMs) have significantly advanced Machine Translation (MT), applying them to linguistically complex domains-such as Social Network Services, literature etc. In these scenarios, translations often require handling non-literal expressions, leading to the inaccuracy of MT metrics. To systematically investigate the reliability of MT metrics, we first curate a meta-evaluation dataset focused on non-literal translations, namely MENT. MENT encompasses four non-literal translation domains and features source sentences paired with translations from diverse MT systems, with 7,530 human-annotated scores on translation quality. Experimental results reveal the inaccuracies of traditional MT metrics and the limitations of LLM-as-a-Judge, particularly the knowledge cutoff and score inconsistency problem. To mitigate these limitations, we propose RATE, a novel agentic translation evaluation framework, centered by a reflective Core Agent that dynamically invokes specialized sub-agents. Experimental results indicate the efficacy of RATE, achieving an improvement of at least 3.2 meta score compared with current metrics. Further experiments demonstrate the robustness of RATE to general-domain MT evaluation. Code and dataset are available at: https://github.com/BITHLP/RATE.
Character-R1: Enhancing Role-Aware Reasoning in Role-Playing Agents via RLVR
Jan 08, 2026Current role-playing agents (RPAs) are typically constructed by imitating surface-level behaviors, but this approach lacks internal cognitive consistency, often causing out-of-character errors in complex situations. To address this, we propose Character-R1, a framework designed to provide comprehensive verifiable reward signals for effective role-aware reasoning, which are missing in recent studies. Specifically, our framework comprises three core designs: (1) Cognitive Focus Reward, which enforces explicit label-based analysis of 10 character elements (e.g., worldview) to structure internal cognition; (2) Reference-Guided Reward, which utilizes overlap-based metrics with reference responses as optimization anchors to enhance exploration and performance; and (3) Character-Conditioned Reward Normalization, which adjusts reward distributions based on character categories to ensure robust optimization across heterogeneous roles. Extensive experiments demonstrate that Character-R1 significantly outperforms existing methods in knowledge, memory and others.
DGA-Net: Enhancing SAM with Depth Prompting and Graph-Anchor Guidance for Camouflaged Object Detection
Jan 06, 2026To fully exploit depth cues in Camouflaged Object Detection (COD), we present DGA-Net, a specialized framework that adapts the Segment Anything Model (SAM) via a novel ``depth prompting" paradigm. Distinguished from existing approaches that primarily rely on sparse prompts (e.g., points or boxes), our method introduces a holistic mechanism for constructing and propagating dense depth prompts. Specifically, we propose a Cross-modal Graph Enhancement (CGE) module that synthesizes RGB semantics and depth geometric within a heterogeneous graph to form a unified guidance signal. Furthermore, we design an Anchor-Guided Refinement (AGR) module. To counteract the inherent information decay in feature hierarchies, AGR forges a global anchor and establishes direct non-local pathways to broadcast this guidance from deep to shallow layers, ensuring precise and consistent segmentation. Quantitative and qualitative experimental results demonstrate that our proposed DGA-Net outperforms the state-of-the-art COD methods.
TCM-Eval: An Expert-Level Dynamic and Extensible Benchmark for Traditional Chinese Medicine
Nov 10, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in modern medicine, yet their application in Traditional Chinese Medicine (TCM) remains severely limited by the absence of standardized benchmarks and the scarcity of high-quality training data. To address these challenges, we introduce TCM-Eval, the first dynamic and extensible benchmark for TCM, meticulously curated from national medical licensing examinations and validated by TCM experts. Furthermore, we construct a large-scale training corpus and propose Self-Iterative Chain-of-Thought Enhancement (SI-CoTE) to autonomously enrich question-answer pairs with validated reasoning chains through rejection sampling, establishing a virtuous cycle of data and model co-evolution. Using this enriched training data, we develop ZhiMingTang (ZMT), a state-of-the-art LLM specifically designed for TCM, which significantly exceeds the passing threshold for human practitioners. To encourage future research and development, we release a public leaderboard, fostering community engagement and continuous improvement.
Learn More, Forget Less: A Gradient-Aware Data Selection Approach for LLM
Nov 07, 2025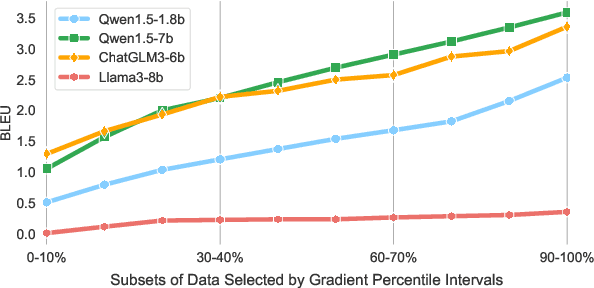
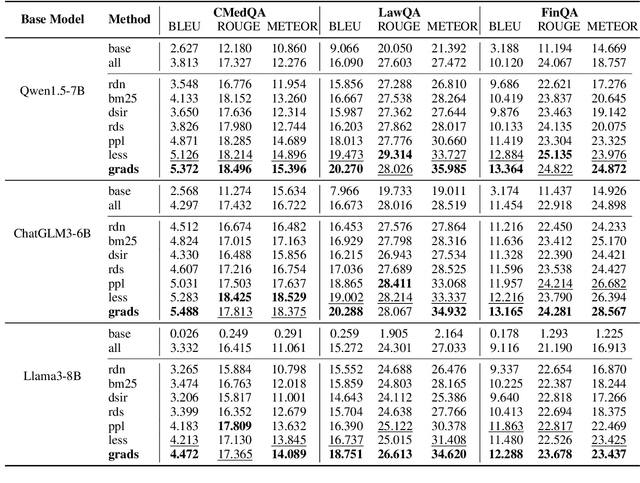
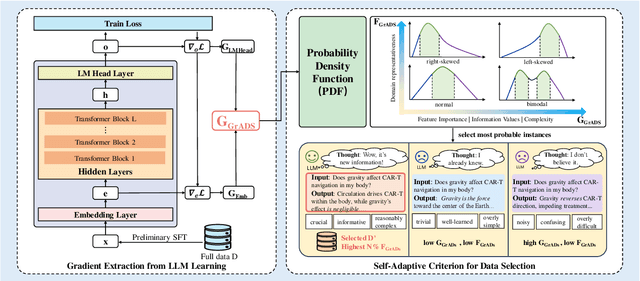
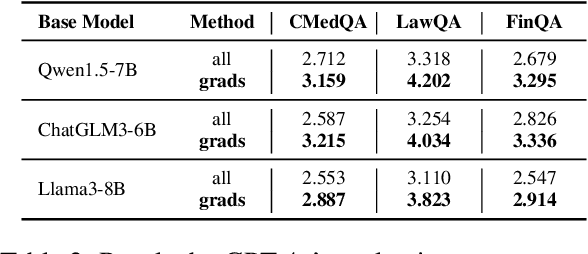
Despite large language models (LLMs) have achieved impressive achievements across numerous tasks, supervised fine-tuning (SFT) remains essential for adapting these models to specialized domains. However, SFT for domain specialization can be resource-intensive and sometimes leads to a deterioration in performance over general capabilities due to catastrophic forgetting (CF). To address these issues, we propose a self-adaptive gradient-aware data selection approach (GrADS) for supervised fine-tuning of LLMs, which identifies effective subsets of training data by analyzing gradients obtained from a preliminary training phase. Specifically, we design self-guided criteria that leverage the magnitude and statistical distribution of gradients to prioritize examples that contribute the most to the model's learning process. This approach enables the acquisition of representative samples that enhance LLMs understanding of domain-specific tasks. Through extensive experimentation with various LLMs across diverse domains such as medicine, law, and finance, GrADS has demonstrated significant efficiency and cost-effectiveness. Remarkably, utilizing merely 5% of the selected GrADS data, LLMs already surpass the performance of those fine-tuned on the entire dataset, and increasing to 50% of the data results in significant improvements! With catastrophic forgetting substantially mitigated simultaneously. We will release our code for GrADS later.
PRIM: Towards Practical In-Image Multilingual Machine Translation
Sep 05, 2025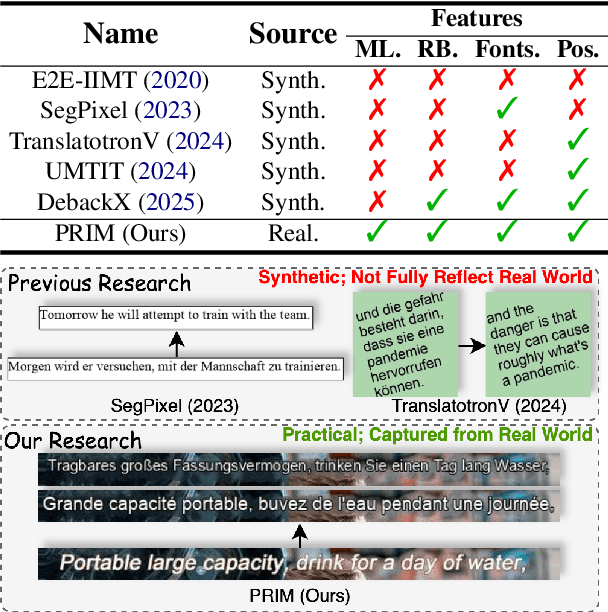
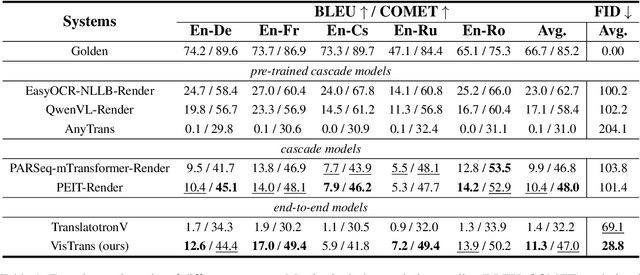
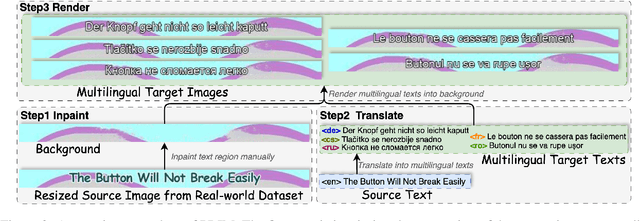

In-Image Machine Translation (IIMT) aims to translate images containing texts from one language to another. Current research of end-to-end IIMT mainly conducts on synthetic data, with simple background, single font, fixed text position, and bilingual translation, which can not fully reflect real world, causing a significant gap between the research and practical conditions. To facilitate research of IIMT in real-world scenarios, we explore Practical In-Image Multilingual Machine Translation (IIMMT). In order to convince the lack of publicly available data, we annotate the PRIM dataset, which contains real-world captured one-line text images with complex background, various fonts, diverse text positions, and supports multilingual translation directions. We propose an end-to-end model VisTrans to handle the challenge of practical conditions in PRIM, which processes visual text and background information in the image separately, ensuring the capability of multilingual translation while improving the visual quality. Experimental results indicate the VisTrans achieves a better translation quality and visual effect compared to other models. The code and dataset are available at: https://github.com/BITHLP/PRIM.
RepoDebug: Repository-Level Multi-Task and Multi-Language Debugging Evaluation of Large Language Models
Sep 04, 2025Large Language Models (LLMs) have exhibited significant proficiency in code debugging, especially in automatic program repair, which may substantially reduce the time consumption of developers and enhance their efficiency. Significant advancements in debugging datasets have been made to promote the development of code debugging. However, these datasets primarily focus on assessing the LLM's function-level code repair capabilities, neglecting the more complex and realistic repository-level scenarios, which leads to an incomplete understanding of the LLM's challenges in repository-level debugging. While several repository-level datasets have been proposed, they often suffer from limitations such as limited diversity of tasks, languages, and error types. To mitigate this challenge, this paper introduces RepoDebug, a multi-task and multi-language repository-level code debugging dataset with 22 subtypes of errors that supports 8 commonly used programming languages and 3 debugging tasks. Furthermore, we conduct evaluation experiments on 10 LLMs, where Claude 3.5 Sonnect, the best-performing model, still cannot perform well in repository-level debugging.
ContextQFormer: A New Context Modeling Method for Multi-Turn Multi-Modal Conversations
May 29, 2025Multi-modal large language models have demonstrated remarkable zero-shot abilities and powerful image-understanding capabilities. However, the existing open-source multi-modal models suffer from the weak capability of multi-turn interaction, especially for long contexts. To address the issue, we first introduce a context modeling module, termed ContextQFormer, which utilizes a memory block to enhance the presentation of contextual information. Furthermore, to facilitate further research, we carefully build a new multi-turn multi-modal dialogue dataset (TMDialog) for pre-training, instruction-tuning, and evaluation, which will be open-sourced lately. Compared with other multi-modal dialogue datasets, TMDialog contains longer conversations, which supports the research of multi-turn multi-modal dialogue. In addition, ContextQFormer is compared with three baselines on TMDialog and experimental results illustrate that ContextQFormer achieves an improvement of 2%-4% in available rate over baselines.
DocMEdit: Towards Document-Level Model Editing
May 26, 2025Model editing aims to correct errors and outdated knowledge in the Large language models (LLMs) with minimal cost. Prior research has proposed a variety of datasets to assess the effectiveness of these model editing methods. However, most existing datasets only require models to output short phrases or sentences, overlooks the widespread existence of document-level tasks in the real world, raising doubts about their practical usability. Aimed at addressing this limitation and promoting the application of model editing in real-world scenarios, we propose the task of document-level model editing. To tackle such challenges and enhance model capabilities in practical settings, we introduce \benchmarkname, a dataset focused on document-level model editing, characterized by document-level inputs and outputs, extrapolative, and multiple facts within a single edit. We propose a series of evaluation metrics and experiments. The results show that the difficulties in document-level model editing pose challenges for existing model editing methods.