 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAME: Towards Factual Multi-Task Model Editing
Oct 07, 2024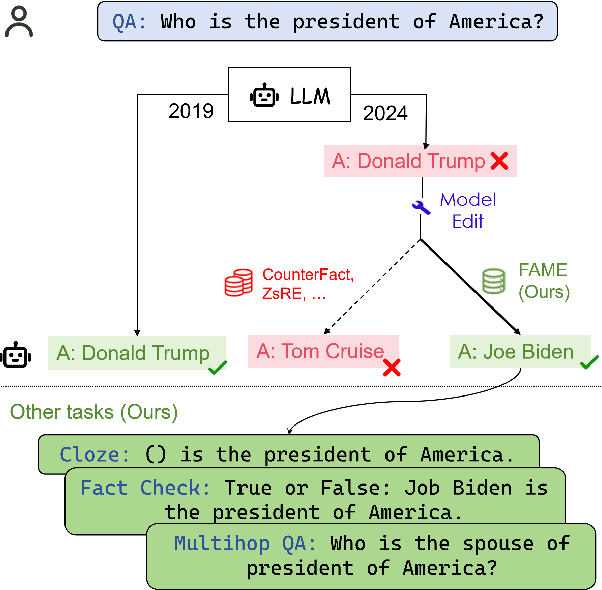
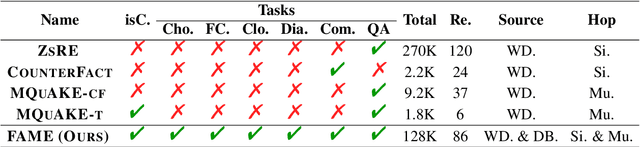
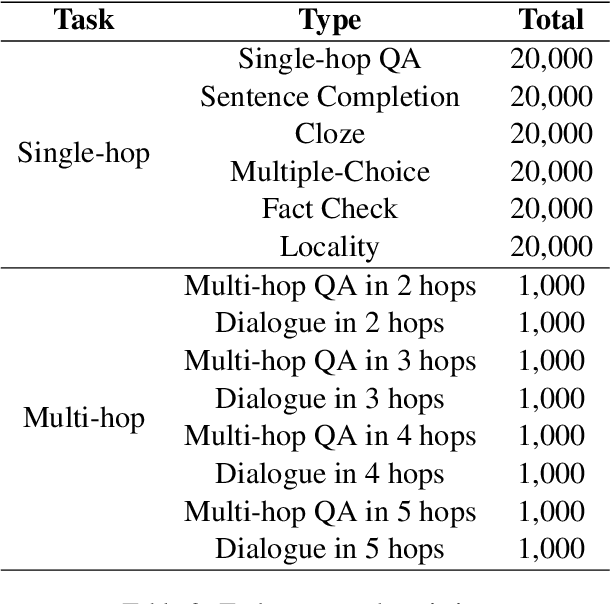
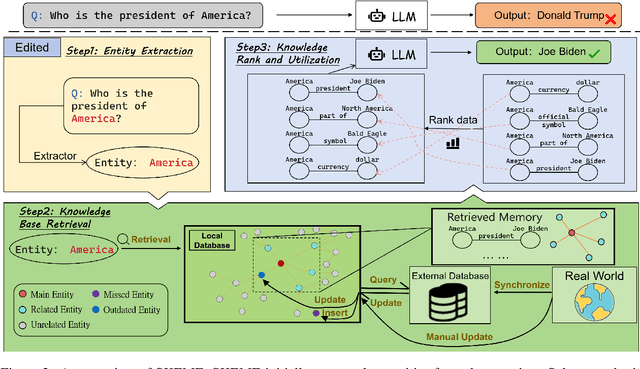
Large language models (LLMs) embed extensive knowledge and utilize it to perform exceptionally well across various tasks. Nevertheless, outdated knowledge or factual errors within LLMs can lead to misleading or incorrect responses, causing significant issues in practical applications. To rectify the fatal flaw without the necessity for costly model retraining, various model editing approaches have been proposed to correct inaccurate knowledge within LLMs in a cost-efficient way. To evaluate these model editing methods, previous work introduced a series of datasets. However, most of the previous datasets only contain fabricated data in a single format, which diverges from real-world model editing scenarios, raising doubts about their usability in practice. To facilitate the application of model editing in real-world scenarios, we propose the challenge of practicality. To resolve such challenges and effectively enhance the capabilities of LLMs, we present FAME, an factual, comprehensive, and multi-task dataset, which is designed to enhance the practicality of model editing. We then propose SKEME, a model editing method that uses a novel caching mechanism to ensure synchronization with the real world. The experiments demonstrate that SKEME performs excellently across various tasks and scenarios, confirming its practicality.