 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Literal Mapping: Benchmarking and Improving Non-Literal Translation Evaluation
Jan 12, 2026Large Language Models (LLMs) have significantly advanced Machine Translation (MT), applying them to linguistically complex domains-such as Social Network Services, literature etc. In these scenarios, translations often require handling non-literal expressions, leading to the inaccuracy of MT metrics. To systematically investigate the reliability of MT metrics, we first curate a meta-evaluation dataset focused on non-literal translations, namely MENT. MENT encompasses four non-literal translation domains and features source sentences paired with translations from diverse MT systems, with 7,530 human-annotated scores on translation quality. Experimental results reveal the inaccuracies of traditional MT metrics and the limitations of LLM-as-a-Judge, particularly the knowledge cutoff and score inconsistency problem. To mitigate these limitations, we propose RATE, a novel agentic translation evaluation framework, centered by a reflective Core Agent that dynamically invokes specialized sub-agents. Experimental results indicate the efficacy of RATE, achieving an improvement of at least 3.2 meta score compared with current metrics. Further experiments demonstrate the robustness of RATE to general-domain MT evaluation. Code and dataset are available at: https://github.com/BITHLP/RATE.
TSPE-GS: Probabilistic Depth Extraction for Semi-Transparent Surface Reconstruction via 3D Gaussian Splatting
Nov 13, 20253D Gaussian Splatting offers a strong speed-quality trade-off but struggles to reconstruct semi-transparent surfaces because most methods assume a single depth per pixel, which fails when multiple surfaces are visible. We propose TSPE-GS (Transparent Surface Probabilistic Extraction for Gaussian Splatting), which uniformly samples transmittance to model a pixel-wise multi-modal distribution of opacity and depth, replacing the prior single-peak assumption and resolving cross-surface depth ambiguity. By progressively fusing truncated signed distance functions, TSPE-GS reconstructs external and internal surfaces separately within a unified framework. The method generalizes to other Gaussian-based reconstruction pipelines without extra training overhead. Extensive experiments on public and self-collected semi-transparent and opaque datasets show TSPE-GS significantly improves semi-transparent geometry reconstruction while maintaining performance on opaque scenes.
PRIM: Towards Practical In-Image Multilingual Machine Translation
Sep 05, 2025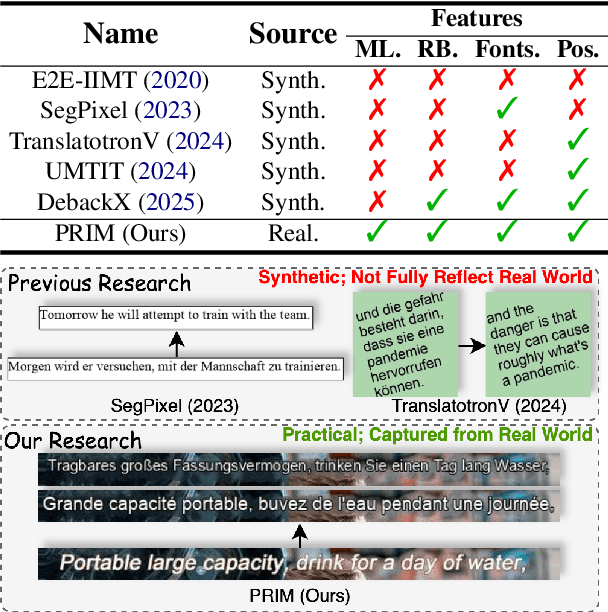
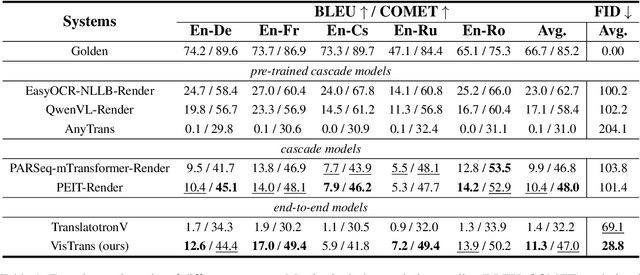
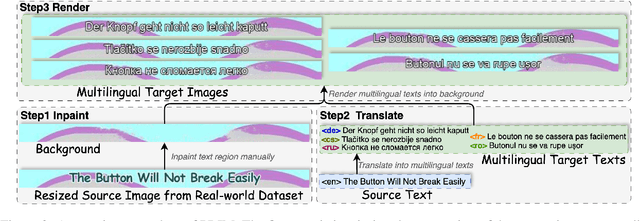

In-Image Machine Translation (IIMT) aims to translate images containing texts from one language to another. Current research of end-to-end IIMT mainly conducts on synthetic data, with simple background, single font, fixed text position, and bilingual translation, which can not fully reflect real world, causing a significant gap between the research and practical conditions. To facilitate research of IIMT in real-world scenarios, we explore Practical In-Image Multilingual Machine Translation (IIMMT). In order to convince the lack of publicly available data, we annotate the PRIM dataset, which contains real-world captured one-line text images with complex background, various fonts, diverse text positions, and supports multilingual translation directions. We propose an end-to-end model VisTrans to handle the challenge of practical conditions in PRIM, which processes visual text and background information in the image separately, ensuring the capability of multilingual translation while improving the visual quality. Experimental results indicate the VisTrans achieves a better translation quality and visual effect compared to other models. The code and dataset are available at: https://github.com/BITHLP/PRIM.
RepoDebug: Repository-Level Multi-Task and Multi-Language Debugging Evaluation of Large Language Models
Sep 04, 2025Large Language Models (LLMs) have exhibited significant proficiency in code debugging, especially in automatic program repair, which may substantially reduce the time consumption of developers and enhance their efficiency. Significant advancements in debugging datasets have been made to promote the development of code debugging. However, these datasets primarily focus on assessing the LLM's function-level code repair capabilities, neglecting the more complex and realistic repository-level scenarios, which leads to an incomplete understanding of the LLM's challenges in repository-level debugging. While several repository-level datasets have been proposed, they often suffer from limitations such as limited diversity of tasks, languages, and error types. To mitigate this challenge, this paper introduces RepoDebug, a multi-task and multi-language repository-level code debugging dataset with 22 subtypes of errors that supports 8 commonly used programming languages and 3 debugging tasks. Furthermore, we conduct evaluation experiments on 10 LLMs, where Claude 3.5 Sonnect, the best-performing model, still cannot perform well in repository-level debugging.
D^3-Talker: Dual-Branch Decoupled Deformation Fields for Few-Shot 3D Talking Head Synthesis
Aug 20, 2025A key challenge in 3D talking head synthesis lies in the reliance on a long-duration talking head video to train a new model for each target identity from scratch. Recent methods have attempted to address this issue by extracting general features from audio through pre-training models. However, since audio contains information irrelevant to lip motion, existing approaches typically struggle to map the given audio to realistic lip behaviors in the target face when trained on only a few frames, causing poor lip synchronization and talking head image quality. This paper proposes D^3-Talker, a novel approach that constructs a static 3D Gaussian attribute field and employs audio and Facial Motion signals to independently control two distinct Gaussian attribute deformation fields, effectively decoupling the predictions of general and personalized deformations. We design a novel similarity contrastive loss function during pre-training to achieve more thorough decoupling. Furthermore, we integrate a Coarse-to-Fine module to refine the rendered images, alleviating blurriness caused by head movements and enhancing overall image quality. Extensive experiments demonstrate that D^3-Talker outperforms state-of-the-art methods in both high-fidelity rendering and accurate audio-lip synchronization with limited training data. Our code will be provided upon acceptance.
JoyAgents-R1: Joint Evolution Dynamics for Versatile Multi-LLM Agents with Reinforcement Learning
Jun 24, 2025Multi-agent reinforcement learning (MARL) has emerged as a prominent paradigm for increasingly complex tasks. However, joint evolution across heterogeneous agents remains challenging due to cooperative inefficiency and training instability. In this paper, we propose the joint evolution dynamics for MARL called JoyAgents-R1, which first applies Group Relative Policy Optimization (GRPO) to the joint training of heterogeneous multi-agents. By iteratively refining agents' large language models (LLMs) and memories, the method achieves holistic equilibrium with optimal decision-making and memory capabilities. Specifically, JoyAgents-R1 first implements node-wise Monte Carlo sampling on the behavior of each agent across entire reasoning trajectories to enhance GRPO sampling efficiency while maintaining policy diversity. Then, our marginal benefit-driven selection strategy identifies top-$K$ sampling groups with maximal reward fluctuations, enabling targeted agent model updates that improve training stability and maximize joint benefits through cost-effective parameter adjustments. Meanwhile, JoyAgents-R1 introduces an adaptive memory evolution mechanism that repurposes GRPO rewards as cost-free supervisory signals to eliminate repetitive reasoning and accelerate convergence. Experiments across general and domain-specific scenarios demonstrate that JoyAgents-R1 achieves performance comparable to that of larger LLMs while built on smaller open-source models.
HomeBench: Evaluating LLMs in Smart Homes with Valid and Invalid Instructions Across Single and Multiple Devices
May 26, 2025Large language models (LLMs) have the potential to revolutionize smart home assistants by enhancing their ability to accurately understand user needs and respond appropriately, which is extremely beneficial for building a smarter home environment. While recent studies have explored integrating LLMs into smart home systems, they primarily focus on handling straightforward, valid single-device operation instructions. However, real-world scenarios are far more complex and often involve users issuing invalid instructions or controlling multiple devices simultaneously. These have two main challenges: LLMs must accurately identify and rectify errors in user instructions and execute multiple user instructions perfectly. To address these challenges and advance the development of LLM-based smart home assistants, we introduce HomeBench, the first smart home dataset with valid and invalid instructions across single and multiple devices in this paper. We have experimental results on 13 distinct LLMs; e.g., GPT-4o achieves only a 0.0% success rate in the scenario of invalid multi-device instructions, revealing that the existing state-of-the-art LLMs still cannot perform well in this situation even with the help of in-context learning, retrieval-augmented generation, and fine-tuning. Our code and dataset are publicly available at https://github.com/BITHLP/HomeBench.
DocMEdit: Towards Document-Level Model Editing
May 26, 2025Model editing aims to correct errors and outdated knowledge in the Large language models (LLMs) with minimal cost. Prior research has proposed a variety of datasets to assess the effectiveness of these model editing methods. However, most existing datasets only require models to output short phrases or sentences, overlooks the widespread existence of document-level tasks in the real world, raising doubts about their practical usability. Aimed at addressing this limitation and promoting the application of model editing in real-world scenarios, we propose the task of document-level model editing. To tackle such challenges and enhance model capabilities in practical settings, we introduce \benchmarkname, a dataset focused on document-level model editing, characterized by document-level inputs and outputs, extrapolative, and multiple facts within a single edit. We propose a series of evaluation metrics and experiments. The results show that the difficulties in document-level model editing pose challenges for existing model editing methods.
TransBench: Breaking Barriers for Transferable Graphical User Interface Agents in Dynamic Digital Environments
May 23, 2025Graphical User Interface (GUI) agents, which autonomously operate on digital interfaces through natural language instructions, hold transformative potential for accessibility, automation, and user experience. A critical aspect of their functionality is grounding - the ability to map linguistic intents to visual and structural interface elements. However, existing GUI agents often struggle to adapt to the dynamic and interconnected nature of real-world digital environments, where tasks frequently span multiple platforms and applications while also being impacted by version updates. To address this, we introduce TransBench, the first benchmark designed to systematically evaluate and enhance the transferability of GUI agents across three key dimensions: cross-version transferability (adapting to version updates), cross-platform transferability (generalizing across platforms like iOS, Android, and Web), and cross-application transferability (handling tasks spanning functionally distinct apps). TransBench includes 15 app categories with diverse functionalities, capturing essential pages across versions and platforms to enable robust evaluation. Our experiments demonstrate significant improvements in grounding accuracy, showcasing the practical utility of GUI agents in dynamic, real-world environments. Our code and data will be publicly available at Github.
Exploring In-Image Machine Translation with Real-World Background
May 21, 2025In-Image Machine Translation (IIMT) aims to translate texts within images from one language to another. Previous research on IIMT was primarily conducted on simplified scenarios such as images of one-line text with black font in white backgrounds, which is far from reality and impractical for applications in the real world. To make IIMT research practically valuable, it is essential to consider a complex scenario where the text backgrounds are derived from real-world images. To facilitate research of complex scenario IIMT, we design an IIMT dataset that includes subtitle text with real-world background. However previous IIMT models perform inadequately in complex scenarios. To address the issue, we propose the DebackX model, which separates the background and text-image from the source image, performs translation on text-image directly, and fuses the translated text-image with the background, to generate the target image. Experimental results show that our model achieves improvements in both translation quality and visual effect.