 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCM-Eval: An Expert-Level Dynamic and Extensible Benchmark for Traditional Chinese Medicine
Nov 10, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in modern medicine, yet their application in Traditional Chinese Medicine (TCM) remains severely limited by the absence of standardized benchmarks and the scarcity of high-quality training data. To address these challenges, we introduce TCM-Eval, the first dynamic and extensible benchmark for TCM, meticulously curated from national medical licensing examinations and validated by TCM experts. Furthermore, we construct a large-scale training corpus and propose Self-Iterative Chain-of-Thought Enhancement (SI-CoTE) to autonomously enrich question-answer pairs with validated reasoning chains through rejection sampling, establishing a virtuous cycle of data and model co-evolution. Using this enriched training data, we develop ZhiMingTang (ZMT), a state-of-the-art LLM specifically designed for TCM, which significantly exceeds the passing threshold for human practitioners. To encourage future research and development, we release a public leaderboard, fostering community engagement and continuous improvement.
RepoDebug: Repository-Level Multi-Task and Multi-Language Debugging Evaluation of Large Language Models
Sep 04, 2025Large Language Models (LLMs) have exhibited significant proficiency in code debugging, especially in automatic program repair, which may substantially reduce the time consumption of developers and enhance their efficiency. Significant advancements in debugging datasets have been made to promote the development of code debugging. However, these datasets primarily focus on assessing the LLM's function-level code repair capabilities, neglecting the more complex and realistic repository-level scenarios, which leads to an incomplete understanding of the LLM's challenges in repository-level debugging. While several repository-level datasets have been proposed, they often suffer from limitations such as limited diversity of tasks, languages, and error types. To mitigate this challenge, this paper introduces RepoDebug, a multi-task and multi-language repository-level code debugging dataset with 22 subtypes of errors that supports 8 commonly used programming languages and 3 debugging tasks. Furthermore, we conduct evaluation experiments on 10 LLMs, where Claude 3.5 Sonnect, the best-performing model, still cannot perform well in repository-level debugging.
ToolSpectrum : Towards Personalized Tool Utilization for Large Language Models
May 19, 2025

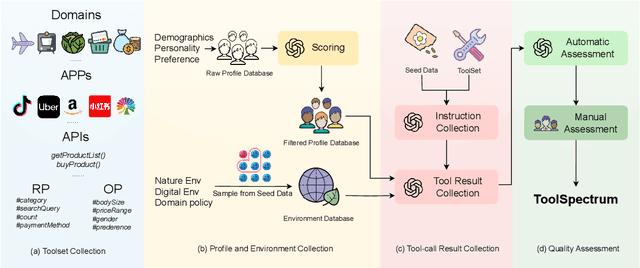

While integrating external tools into large language models (LLMs) enhances their ability to access real-time information and domain-specific services, existing approaches focus narrowly on functional tool selection following user instructions, overlooking the context-aware personalization in tool selection. This oversight leads to suboptimal user satisfaction and inefficient tool utilization, particularly when overlapping toolsets require nuanced selection based on contextual factors. To bridge this gap, we introduce ToolSpectrum, a benchmark designed to evaluate LLMs' capabilities in personalized tool utilization. Specifically, we formalize two key dimensions of personalization, user profile and environmental factors, and analyze their individual and synergistic impacts on tool utilization. Through extensive experiments on ToolSpectrum, we demonstrate that personalized tool utilization significantly improves user experience across diverse scenarios. However, even state-of-the-art LLMs exhibit the limited ability to reason jointly about user profiles and environmental factors, often prioritizing one dimension at the expense of the other. Our findings underscore the necessity of context-aware personalization in tool-augmented LLMs and reveal critical limitations for current models. Our data and code are available at https://github.com/Chengziha0/ToolSpectrum.
Beyond Binary: Towards Fine-Grained LLM-Generated Text Detection via Role Recognition and Involvement Measurement
Oct 18, 2024The rapid development of large language models (LLMs), like ChatGPT, has resulted in the widespread presence of LLM-generated content on social media platforms, raising concerns about misinformation, data biases, and privacy violations, which can undermine trust in online discourse. While detecting LLM-generated content is crucial for mitigating these risks, current methods often focus on binary classification, failing to address the complexities of real-world scenarios like human-AI collaboration. To move beyond binary classification and address these challenges, we propose a new paradigm for detecting LLM-generated content. This approach introduces two novel tasks: LLM Role Recognition (LLM-RR), a multi-class classification task that identifies specific roles of LLM in content generation, and LLM Influence Measurement (LLM-IM), a regression task that quantifies the extent of LLM involvement in content creation. To support these tasks, we propose LLMDetect, a benchmark designed to evaluate detectors' performance on these new tasks. LLMDetect includes the Hybrid News Detection Corpus (HNDC) for training detectors, as well as DetectEval, a comprehensive evaluation suite that considers five distinct cross-context variations and multi-intensity variations within the same LLM role. This allows for a thorough assessment of detectors' generalization and robustness across diverse contexts. Our empirical validation of 10 baseline detection methods demonstrates that fine-tuned PLM-based models consistently outperform others on both tasks, while advanced LLMs face challenges in accurately detecting their own generated content. Our experimental results and analysis offer insights for developing more effective detection models for LLM-generated content. This research enhances the understanding of LLM-generated content and establishes a foundation for more nuanced detection methodologies.
HorGait: Advancing Gait Recognition with Efficient High-Order Spatial Interactions in LiDAR Point Clouds
Oct 11, 2024Gait recognition is a remote biometric technology that utilizes the dynamic characteristics of human movement to identify individuals even under various extreme lighting conditions. Due to the limitation in spatial perception capability inherent in 2D gait representations, LiDAR can directly capture 3D gait features and represent them as point clouds, reducing environmental and lighting interference in recognition while significantly advancing privacy protection. For complex 3D representations, shallow networks fail to achieve accurate recognition, making vision Transformers the foremost prevalent method. However, the prevalence of dumb patches has limited the widespread use of Transformer architecture in gait recognition. This paper proposes a method named HorGait, which utilizes a hybrid model with a Transformer architecture for gait recognition on the planar projection of 3D point clouds from LiDAR. Specifically, it employs a hybrid model structure called LHM Block to achieve input adaptation, long-range, and high-order spatial interaction of the Transformer architecture. Additionally, it uses large convolutional kernel CNNs to segment the input representation, replacing attention windows to reduce dumb patches. We conducted extensive experiments, and the results show that HorGait achieves state-of-the-art performance among Transformer architecture methods on the SUSTech1K dataset, verifying that the hybrid model can complete the full Transformer process and perform better in point cloud planar projection. The outstanding performance of HorGait offers new insights for the future application of the Transformer architecture in gait recognition.
SpheriGait: Enriching Spatial Representation via Spherical Projection for LiDAR-based Gait Recognition
Sep 18, 2024Gait recognition is a rapidly progressing technique for the remote identification of individuals. Prior research predominantly employing 2D sensors to gather gait data has achieved notable advancements; nonetheless, they have unavoidably neglected the influence of 3D dynamic characteristics on recognition. Gait recognition utilizing LiDAR 3D point clouds not only directly captures 3D spatial features but also diminishes the impact of lighting conditions while ensuring privacy protection.The essence of the problem lies in how to effectively extract discriminative 3D dynamic representation from point clouds.In this paper, we proposes a method named SpheriGait for extracting and enhancing dynamic features from point clouds for Lidar-based gait recognition. Specifically, it substitutes the conventional point cloud plane projection method with spherical projection to augment the perception of dynamic feature.Additionally, a network block named DAM-L is proposed to extract gait cues from the projected point cloud data. We conducted extensive experiments and the results demonstrated the SpheriGait achieved state-of-the-art performance on the SUSTech1K dataset, and verified that the spherical projection method can serve as a universal data preprocessing technique to enhance the performance of other LiDAR-based gait recognition methods, exhibiting exceptional flexibility and practicality.
Movable Frequency Diverse Array for Wireless Communication Security
Jul 26, 2024



Frequency diverse array (FDA) is a promising antenna technology to achieve physical layer security by varying the frequency of each antenna at the transmitter. However, when the channels of the legitimate user and eavesdropper are highly correlated, FDA is limited by the frequency constraint and cannot provide satisfactory security performance. In this paper, we propose a novel movable FDA (MFDA) antenna technology where the positions of antennas can be dynamically adjusted in a given finite region. Specifically, we aim to maximize the secrecy capacity by jointly optimizing the antenna beamforming vector, antenna frequency vector and antenna position vector. To solve this non-convex optimization problem with coupled variables, we develop a two-stage alternating optimization (AO) algorithm based on block successive upper-bound minimization (BSUM) method. Moreover, to evaluate the security performance provided by MFDA, we introduce two benchmark schemes, i.e., phased array (PA) and FDA. Simulation results demonstrate that MFDA can significantly enhance security performance compared to PA and FDA. In particular, when the frequency constraint is strict, MFDA can further increase the secrecy capacity by adjusting the positions of antennas instead of the frequencies.
Movable Frequency Diverse Array-Assisted Covert Communication With Multiple Wardens
Jul 26, 2024



The frequency diverse array (FDA) is highly promising for improving covert communication performance by adjusting the frequency of each antenna at the transmitter. However, when faced with the cases of multiple wardens and highly correlated channels, FDA is limited by the frequency constraint and cannot provide satisfactory covert performance. In this paper, we propose a novel movable FDA (MFDA) antenna technology where positions of the antennas can be dynamically adjusted in a given finite region. Specifically, we aim to maximize the covert rate by jointly optimizing the antenna beamforming vector, antenna frequency vector and antenna position vector. To solve this non-convex optimization problem with coupled variables, we develop a two-stage alternating optimization (AO) algorithm based on the block successive upper-bound minimization (BSUM) method. Moreover, considering the challenge of obtaining perfect channel state information (CSI) at multiple wardens, we study the case of imperfect CSI. Simulation results demonstrate that MFDA can significantly enhance covert performance compared to the conventional FDA. In particular, when the frequency constraint is strict, MFDA can further increase the covert rate by adjusting the positions of antennas instead of the frequencies.