 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovable Frequency Diverse Array-Assisted Covert Communication With Multiple Wardens
Jul 26, 2024



The frequency diverse array (FDA) is highly promising for improving covert communication performance by adjusting the frequency of each antenna at the transmitter. However, when faced with the cases of multiple wardens and highly correlated channels, FDA is limited by the frequency constraint and cannot provide satisfactory covert performance. In this paper, we propose a novel movable FDA (MFDA) antenna technology where positions of the antennas can be dynamically adjusted in a given finite region. Specifically, we aim to maximize the covert rate by jointly optimizing the antenna beamforming vector, antenna frequency vector and antenna position vector. To solve this non-convex optimization problem with coupled variables, we develop a two-stage alternating optimization (AO) algorithm based on the block successive upper-bound minimization (BSUM) method. Moreover, considering the challenge of obtaining perfect channel state information (CSI) at multiple wardens, we study the case of imperfect CSI. Simulation results demonstrate that MFDA can significantly enhance covert performance compared to the conventional FDA. In particular, when the frequency constraint is strict, MFDA can further increase the covert rate by adjusting the positions of antennas instead of the frequencies.
Movable Frequency Diverse Array for Wireless Communication Security
Jul 26, 2024



Frequency diverse array (FDA) is a promising antenna technology to achieve physical layer security by varying the frequency of each antenna at the transmitter. However, when the channels of the legitimate user and eavesdropper are highly correlated, FDA is limited by the frequency constraint and cannot provide satisfactory security performance. In this paper, we propose a novel movable FDA (MFDA) antenna technology where the positions of antennas can be dynamically adjusted in a given finite region. Specifically, we aim to maximize the secrecy capacity by jointly optimizing the antenna beamforming vector, antenna frequency vector and antenna position vector. To solve this non-convex optimization problem with coupled variables, we develop a two-stage alternating optimization (AO) algorithm based on block successive upper-bound minimization (BSUM) method. Moreover, to evaluate the security performance provided by MFDA, we introduce two benchmark schemes, i.e., phased array (PA) and FDA. Simulation results demonstrate that MFDA can significantly enhance security performance compared to PA and FDA. In particular, when the frequency constraint is strict, MFDA can further increase the secrecy capacity by adjusting the positions of antennas instead of the frequencies.
Learning by Distillation: A Self-Supervised Learning Framework for Optical Flow Estimation
Jun 08, 2021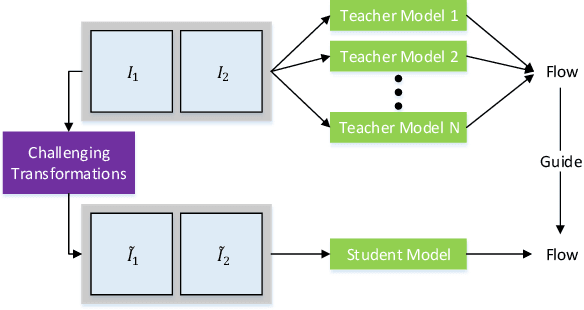
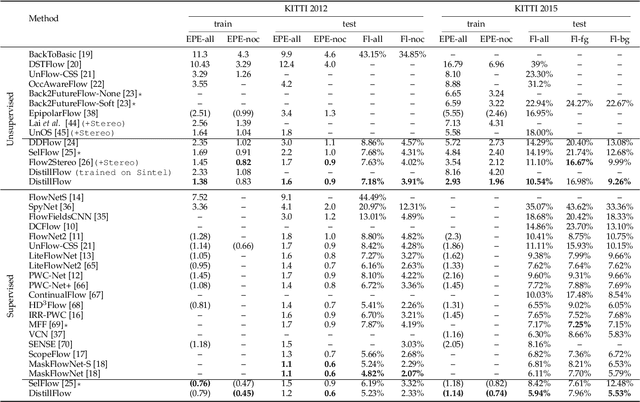
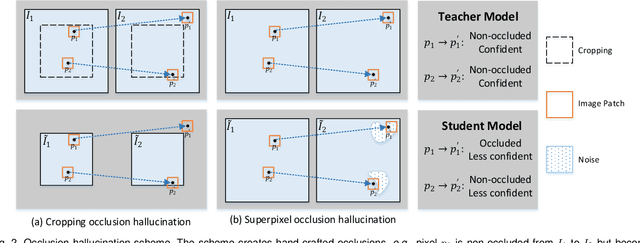
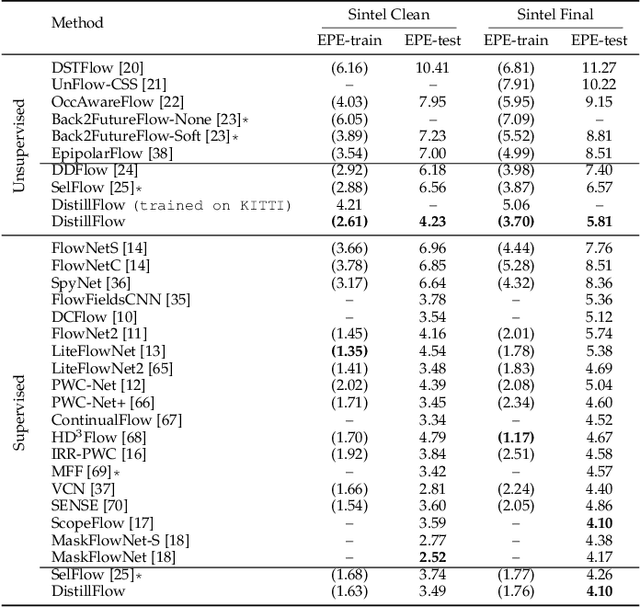
We present DistillFlow, a knowledge distillation approach to learning optical flow. DistillFlow trains multiple teacher models and a student model, where challenging transformations are applied to the input of the student model to generate hallucinated occlusions as well as less confident predictions. Then, a self-supervised learning framework is constructed: confident predictions from teacher models are served as annotations to guide the student model to learn optical flow for those less confident predictions. The self-supervised learning framework enables us to effectively learn optical flow from unlabeled data, not only for non-occluded pixels, but also for occluded pixels. DistillFlow achieves state-of-the-art unsupervised learning performance on both KITTI and Sintel datasets. Our self-supervised pre-trained model also provides an excellent initialization for supervised fine-tuning, suggesting an alternate training paradigm in contrast to current supervised learning methods that highly rely on pre-training on synthetic data. At the time of writing, our fine-tuned models ranked 1st among all monocular methods on the KITTI 2015 benchmark, and outperform all published methods on the Sintel Final benchmark. More importantly, we demonstrate the generalization capability of DistillFlow in three aspects: framework generalization, correspondence generalization and cross-dataset generalization.
Function4D: Real-time Human Volumetric Capture from Very Sparse Consumer RGBD Sensors
May 06, 2021


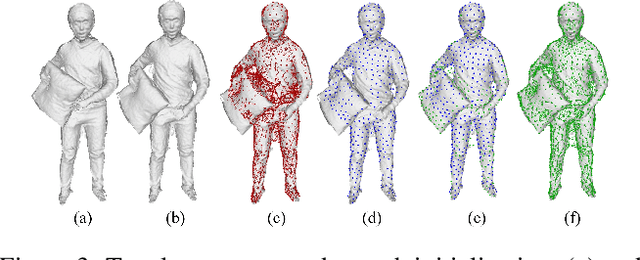
Human volumetric capture is a long-standing topic in computer vision and computer graphics. Although high-quality results can be achieved using sophisticated off-line systems, real-time human volumetric capture of complex scenarios, especially using light-weight setups, remains challenging. In this paper, we propose a human volumetric capture method that combines temporal volumetric fusion and deep implicit functions. To achieve high-quality and temporal-continuous reconstruction, we propose dynamic sliding fusion to fuse neighboring depth observations together with topology consistency. Moreover, for detailed and complete surface generation, we propose detail-preserving deep implicit functions for RGBD input which can not only preserve the geometric details on the depth inputs but also generate more plausible texturing results. Results and experiments show that our method outperforms existing methods in terms of view sparsity, generalization capacity, reconstruction quality, and run-time efficiency.
Learning 3D Face Reconstruction with a Pose Guidance Network
Oct 09, 2020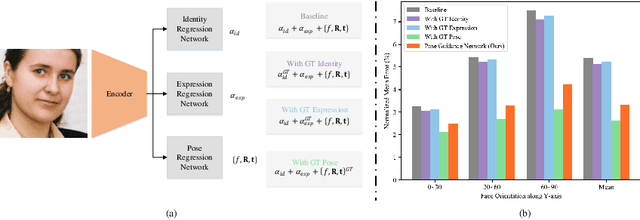
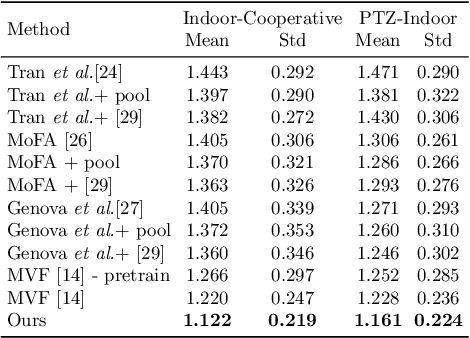
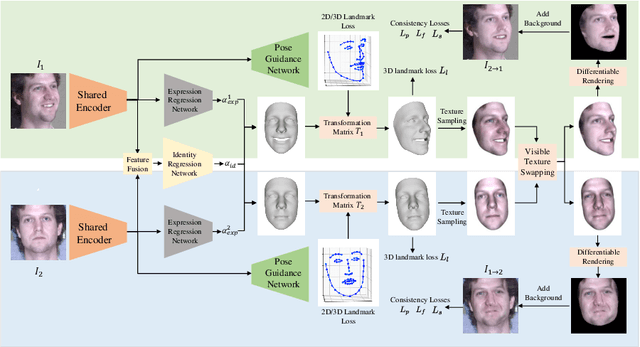

We present a self-supervised learning approach to learning monocular 3D face reconstruction with a pose guidance network (PGN). First, we unveil the bottleneck of pose estimation in prior parametric 3D face learning methods, and propose to utilize 3D face landmarks for estimating pose parameters. With our specially designed PGN, our model can learn from both faces with fully labeled 3D landmarks and unlimited unlabeled in-the-wild face images. Our network is further augmented with a self-supervised learning scheme, which exploits face geometry information embedded in multiple frames of the same person, to alleviate the ill-posed nature of regressing 3D face geometry from a single image. These three insights yield a single approach that combines the complementary strengths of parametric model learning and data-driven learning techniques. We conduct a rigorous evaluation on the challenging AFLW2000-3D, Florence and FaceWarehouse datasets, and show that our method outperforms the state-of-the-art for all metrics.
Flow2Stereo: Effective Self-Supervised Learning of Optical Flow and Stereo Matching
Apr 05, 2020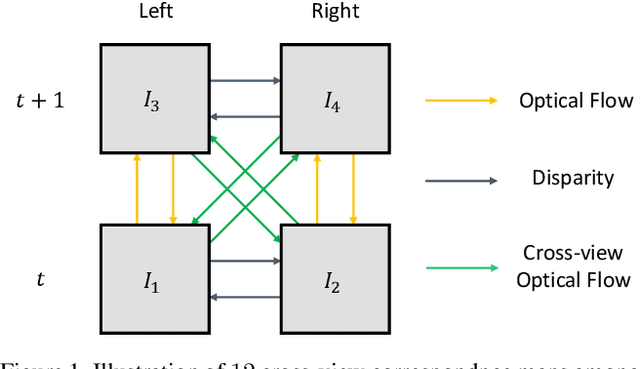
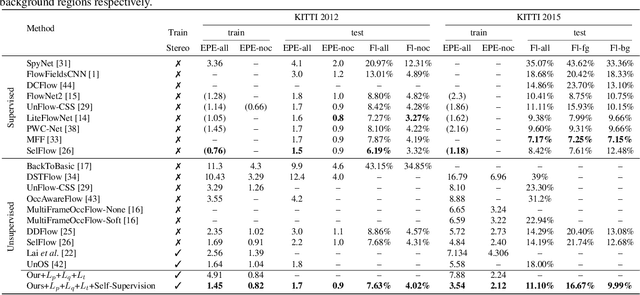


In this paper, we propose a unified method to jointly learn optical flow and stereo matching. Our first intuition is stereo matching can be modeled as a special case of optical flow, and we can leverage 3D geometry behind stereoscopic videos to guide the learning of these two forms of correspondences. We then enroll this knowledge into the state-of-the-art self-supervised learning framework, and train one single network to estimate both flow and stereo. Second, we unveil the bottlenecks in prior self-supervised learning approaches, and propose to create a new set of challenging proxy tasks to boost performance. These two insights yield a single model that achieves the highest accuracy among all existing unsupervised flow and stereo methods on KITTI 2012 and 2015 benchmarks. More remarkably, our self-supervised method even outperforms several state-of-the-art fully supervised methods, including PWC-Net and FlowNet2 on KITTI 2012.
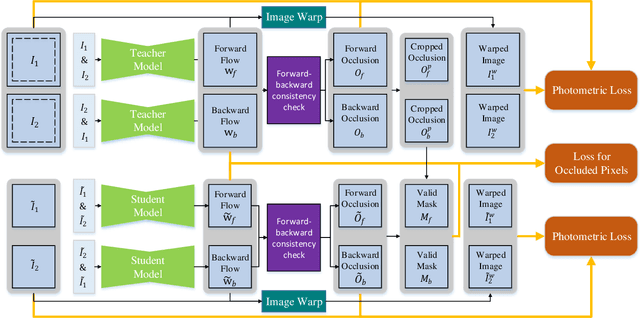
SelFlow: Self-Supervised Learning of Optical Flow
Apr 19, 2019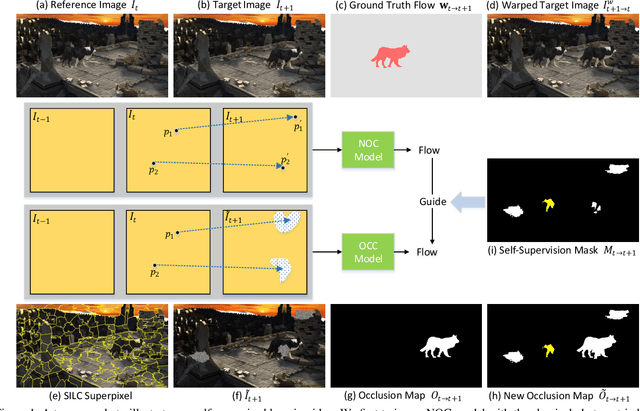
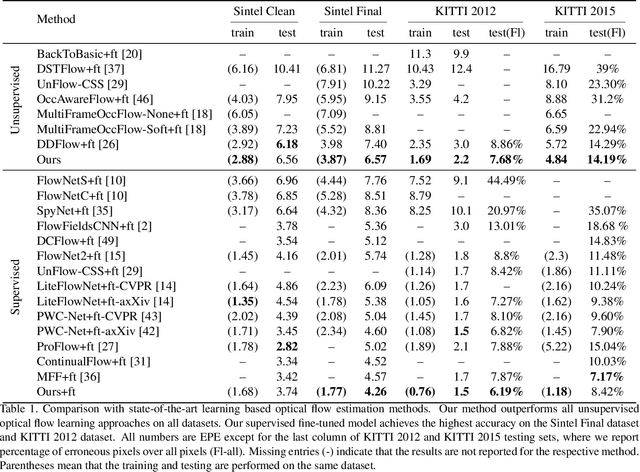

We present a self-supervised learning approach for optical flow. Our method distills reliable flow estimations from non-occluded pixels, and uses these predictions as ground truth to learn optical flow for hallucinated occlusions. We further design a simple CNN to utilize temporal information from multiple frames for better flow estimation. These two principles lead to an approach that yields the best performance for unsupervised optical flow learning on the challenging benchmarks including MPI Sintel, KITTI 2012 and 2015. More notably, our self-supervised pre-trained model provides an excellent initialization for supervised fine-tuning. Our fine-tuned models achieve state-of-the-art results on all three datasets. At the time of writing, we achieve EPE=4.26 on the Sintel benchmark, outperforming all submitted methods.
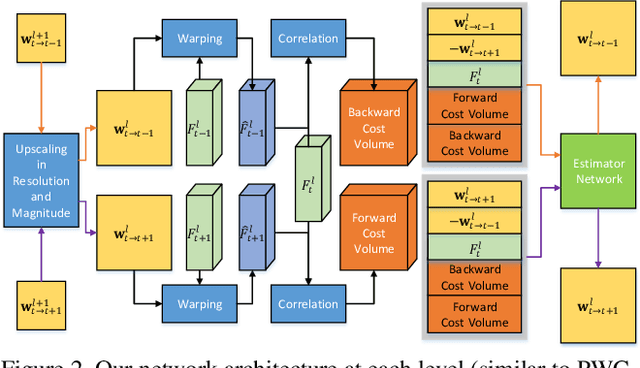
DDFlow: Learning Optical Flow with Unlabeled Data Distillation
Feb 25, 2019


We present DDFlow, a data distillation approach to learning optical flow estimation from unlabeled data. The approach distills reliable predictions from a teacher network, and uses these predictions as annotations to guide a student network to learn optical flow. Unlike existing work relying on hand-crafted energy terms to handle occlusion, our approach is data-driven, and learns optical flow for occluded pixels. This enables us to train our model with a much simpler loss function, and achieve a much higher accuracy. We conduct a rigorous evaluation on the challenging Flying Chairs, MPI Sintel, KITTI 2012 and 2015 benchmarks, and show that our approach significantly outperforms all existing unsupervised learning methods, while running at real time.
Semantically Consistent Image Completion with Fine-grained Details
Nov 26, 2017



Image completion has achieved significant progress due to advances in generative adversarial networks (GANs). Albeit natural-looking, the synthesized contents still lack details, especially for scenes with complex structures or images with large holes. This is because there exists a gap between low-level reconstruction loss and high-level adversarial loss. To address this issue, we introduce a perceptual network to provide mid-level guidance, which measures the semantical similarity between the synthesized and original contents in a similarity-enhanced space. We conduct a detailed analysis on the effects of different losses and different levels of perceptual features in image completion, showing that there exist complementarity between adversarial training and perceptual features. By combining them together, our model can achieve nearly seamless fusion results in an end-to-end manner. Moreover, we design an effective lightweight generator architecture, which can achieve effective image inpainting with far less parameters. Evaluated on CelebA Face and Paris StreetView dataset, our proposed method significantly outperforms existing methods.