 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovable Frequency Diverse Array-Assisted Covert Communication With Multiple Wardens
Jul 26, 2024



The frequency diverse array (FDA) is highly promising for improving covert communication performance by adjusting the frequency of each antenna at the transmitter. However, when faced with the cases of multiple wardens and highly correlated channels, FDA is limited by the frequency constraint and cannot provide satisfactory covert performance. In this paper, we propose a novel movable FDA (MFDA) antenna technology where positions of the antennas can be dynamically adjusted in a given finite region. Specifically, we aim to maximize the covert rate by jointly optimizing the antenna beamforming vector, antenna frequency vector and antenna position vector. To solve this non-convex optimization problem with coupled variables, we develop a two-stage alternating optimization (AO) algorithm based on the block successive upper-bound minimization (BSUM) method. Moreover, considering the challenge of obtaining perfect channel state information (CSI) at multiple wardens, we study the case of imperfect CSI. Simulation results demonstrate that MFDA can significantly enhance covert performance compared to the conventional FDA. In particular, when the frequency constraint is strict, MFDA can further increase the covert rate by adjusting the positions of antennas instead of the frequencies.
Maximising Quantum-Computing Expressive Power through Randomised Circuits
Dec 04, 2023In the noisy intermediate-scale quantum era, variational quantum algorithms (VQAs) have emerged as a promising avenue to obtain quantum advantage. However, the success of VQAs depends on the expressive power of parameterised quantum circuits, which is constrained by the limited gate number and the presence of barren plateaus. In this work, we propose and numerically demonstrate a novel approach for VQAs, utilizing randomised quantum circuits to generate the variational wavefunction. We parameterize the distribution function of these random circuits using artificial neural networks and optimize it to find the solution. This random-circuit approach presents a trade-off between the expressive power of the variational wavefunction and time cost, in terms of the sampling cost of quantum circuits. Given a fixed gate number, we can systematically increase the expressive power by extending the quantum-computing time. With a sufficiently large permissible time cost, the variational wavefunction can approximate any quantum state with arbitrary accuracy. Furthermore, we establish explicit relationships between expressive power, time cost, and gate number for variational quantum eigensolvers. These results highlight the promising potential of the random-circuit approach in achieving a high expressive power in quantum computing.
A Comparative Study of Polynomial Chaos Expansion-Based Methods for Global Sensitivity Analysis in Power System Uncertainty Control
Jul 13, 2023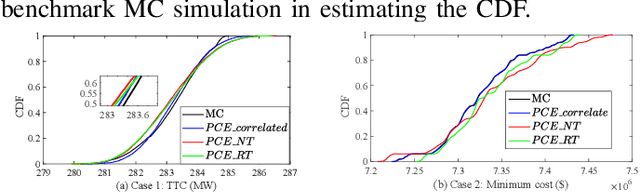
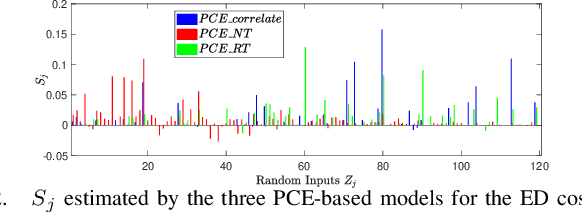
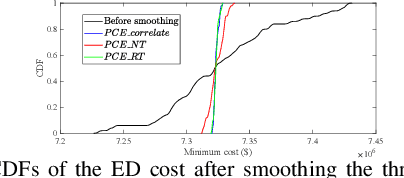
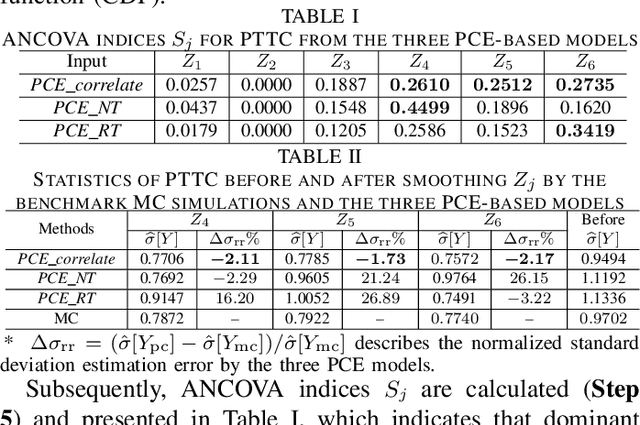
In this letter, we compare three polynomial chaos expansion (PCE)-based methods for ANCOVA (ANalysis of COVAriance) indices based global sensitivity analysis for correlated random inputs in two power system applications. Surprisingly, the PCE-based models built with independent inputs after decorrelation may not give the most accurate ANCOVA indices, though this approach seems to be the most correct one and was applied in [1] in the field of civil engineering. In contrast, the PCE model built using correlated random inputs directly yields the most accurate ANCOVA indices for global sensitivity analysis. Analysis and discussions about the errors of different PCE-based models will also be presented. These results provide important guidance for uncertainty management and control in power system operation and security assessment.
Prompt-Learning for Cross-Lingual Relation Extraction
Apr 20, 2023Relation Extraction (RE) is a crucial task in Information Extraction, which entails predicting relationships between entities within a given sentence. However, extending pre-trained RE models to other languages is challenging, particularly in real-world scenarios where Cross-Lingual Relation Extraction (XRE) is required. Despite recent advancements in Prompt-Learning, which involves transferring knowledge from Multilingual Pre-trained Language Models (PLMs) to diverse downstream tasks, there is limited research on the effective use of multilingual PLMs with prompts to improve XRE. In this paper, we present a novel XRE algorithm based on Prompt-Tuning, referred to as Prompt-XRE. To evaluate its effectiveness, we design and implement several prompt templates, including hard, soft, and hybrid prompts, and empirically test their performance on competitive multilingual PLMs, specifically mBART. Our extensive experiments, conducted on the low-resource ACE05 benchmark across multiple languages, demonstrate that our Prompt-XRE algorithm significantly outperforms both vanilla multilingual PLMs and other existing models, achieving state-of-the-art performance in XRE. To further show the generalization of our Prompt-XRE on larger data scales, we construct and release a new XRE dataset- WMT17-EnZh XRE, containing 0.9M English-Chinese pairs extracted from WMT 2017 parallel corpus. Experiments on WMT17-EnZh XRE also show the effectiveness of our Prompt-XRE against other competitive baselines. The code and newly constructed dataset are freely available at \url{https://github.com/HSU-CHIA-MING/Prompt-XRE}.
MT-SNN: Enhance Spiking Neural Network with Multiple Thresholds
Mar 20, 2023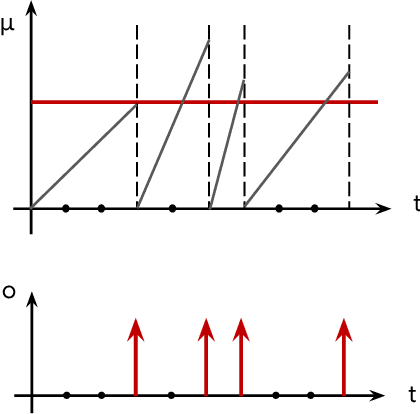
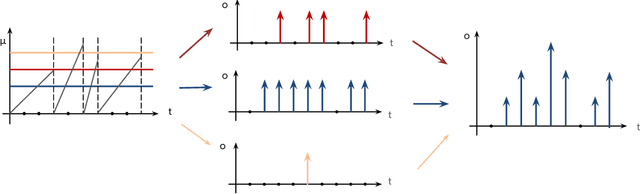
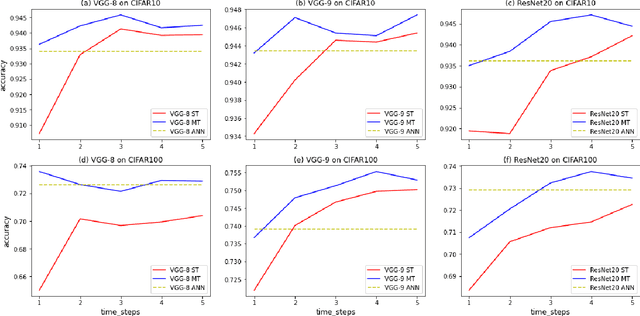
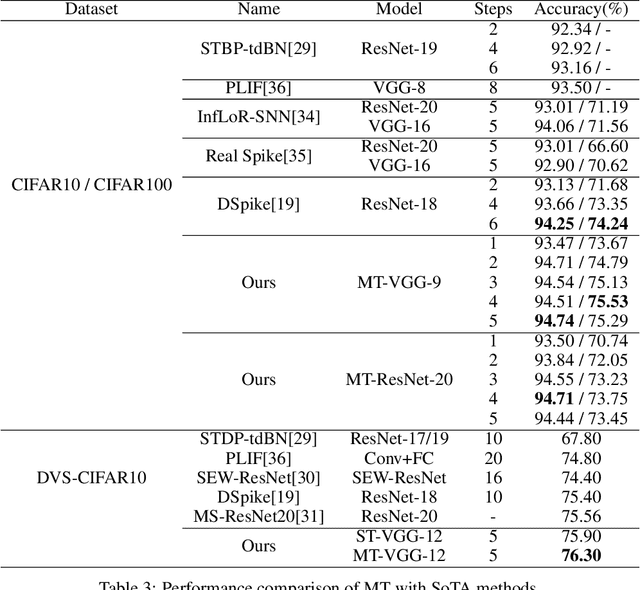
Spiking neural networks (SNNs), as a biology-inspired method mimicking the spiking nature of brain neurons, is a promising energy-efficient alternative to the traditional artificial neural networks (ANNs). The energy saving of SNNs is mainly from multiplication free property brought by binarized intermediate activations. In this paper, we proposed a Multiple Threshold (MT) approach to alleviate the precision loss brought by the binarized activations, such that SNNs can reach higher accuracy at fewer steps. We evaluate the approach on CIFAR10, CIFAR100 and DVS-CIFAR10, and demonstrate that MT can promote SNNs extensively, especially at early steps. For example, With MT, Parametric-Leaky-Integrate-Fire(PLIF) based VGG net can even outperform the ANN counterpart with 1 step.
DIWIFT: Discovering Instance-wise Influential Features for Tabular Data
Jul 06, 2022
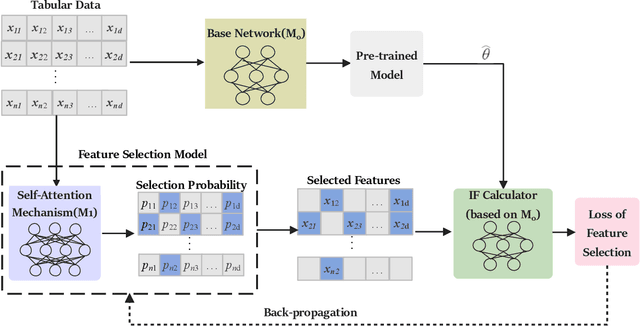
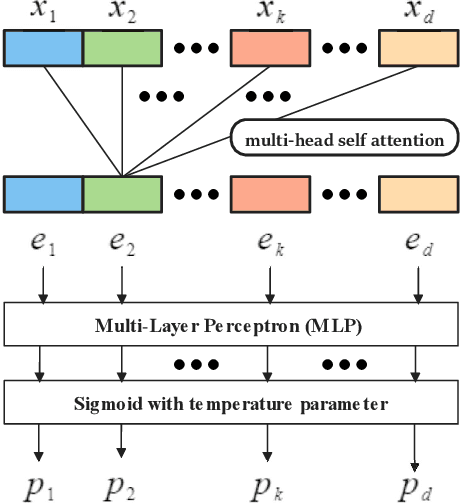
Tabular data is one of the most common data storage formats in business applications, ranging from retail, bank and E-commerce. These applications rely heavily on machine learning models to achieve business success. One of the critical problems in learning tabular data is to distinguish influential features from all the predetermined features. Global feature selection has been well-studied for quite some time, assuming that all instances have the same influential feature subsets. However, different instances rely on different feature subsets in practice, which also gives rise to that instance-wise feature selection receiving increasing attention in recent studies. In this paper, we first propose a novel method for discovering instance-wise influential features for tabular data (DIWIFT), the core of which is to introduce the influence function to measure the importance of an instance-wise feature. DIWIFT is capable of automatically discovering influential feature subsets of different sizes in different instances, which is different from global feature selection that considers all instances with the same influential feature subset. On the other hand, different from the previous instance-wise feature selection, DIWIFT minimizes the validation loss on the validation set and is thus more robust to the distribution shift existing in the training dataset and test dataset, which is important in tabular data. Finally, we conduct extensive experiments on both synthetic and real-world datasets to validate the effectiveness of our DIWIFT, compared it with baseline methods. Moreover, we also demonstrate the robustness of our method via some ablation experiments.
A Data-Driven Uncertainty Quantification Method for Stochastic Economic Dispatch
Sep 16, 2021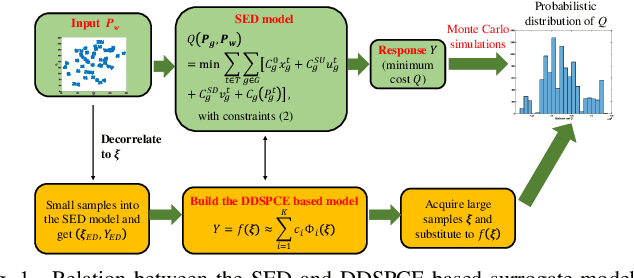
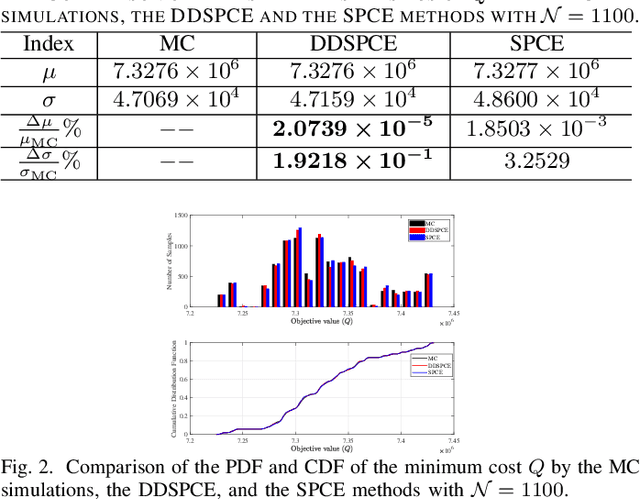
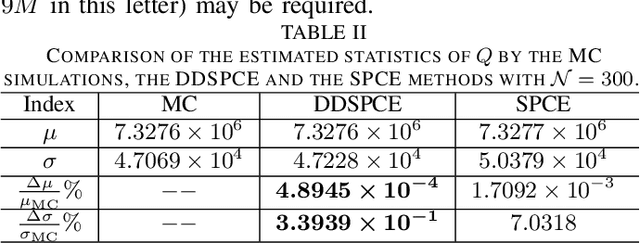
This letter proposes a data-driven sparse polynomial chaos expansion-based surrogate model for the stochastic economic dispatch problem considering uncertainty from wind power. The proposed method can provide accurate estimations for the statistical information (e.g., mean, variance, probability density function, and cumulative distribution function) for the stochastic economic dispatch solution efficiently without requiring the probability distributions of random inputs. Simulation studies on an integrated electricity and gas system (IEEE 118-bus system integrated with a 20-node gas system are presented, demonstrating the efficiency and accuracy of the proposed method compared to the Monte Carlo simulations.
Quantum reinforcement learning in continuous action space
Jan 13, 2021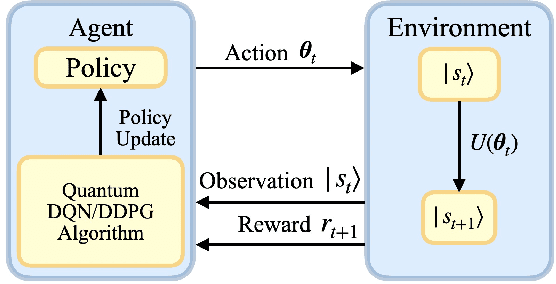
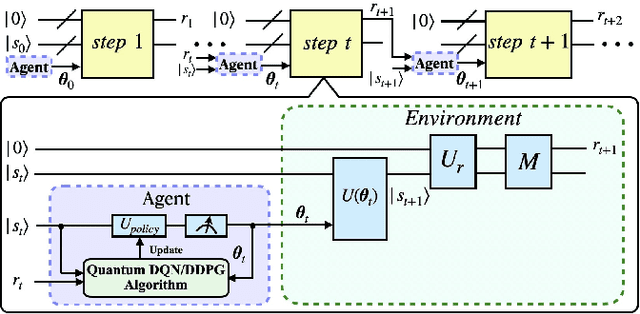
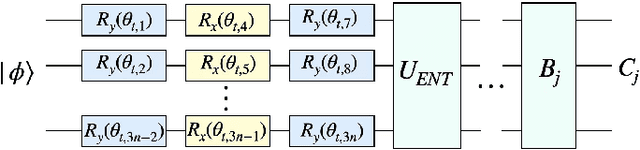
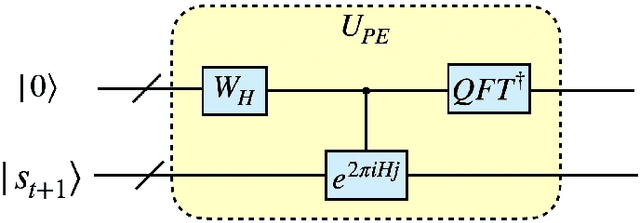
Quantum mechanics has the potential to speedup machine learning algorithms, including reinforcement learning(RL). Previous works have shown that quantum algorithms can efficiently solve RL problems in discrete action space, but could become intractable in continuous domain, suffering notably from the curse of dimensionality due to discretization. In this work, we propose an alternative quantum circuit design that can solve RL problems in continuous action space without the dimensionality problem. Specifically, we propose a quantum version of the Deep Deterministic Policy Gradient method constructed from quantum neural networks, with the potential advantage of obtaining an exponential speedup in gate complexity for each iteration. As applications, we demonstrate that quantum control tasks, including the eigenvalue problem and quantum state generation, can be formulated as sequential decision problems and solved by our method.
Quantum subspace alignment for domain adaptation
Jan 08, 2020


Domain adaptation (DA) is used for adaptively obtaining labels of an unprocessed data set with given a related, but different labelled data set. Subspace alignment (SA), a representative DA algorithm, attempts to find a linear transformation to align the two different data sets. The classifier trained on the aligned labelled data set can be transferred to the unlabelled data set to classify the target labels. In this paper, a quantum version of the SA algorithm is proposed to implement the domain adaptation procedure on a quantum computer. Compared with the classical SA algorithm, the quantum algorithm presented in our work achieves at least quadratic speedup in the number of given samples and the data dimension. In addition, the kernel method is applied to the quantum SA algorithm to capture the nonlinear characteristics of the data sets.