 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Broad, Acting Fast: Latent Reasoning Distillation from Multi-Perspective Chain-of-Thought for E-Commerce Relevance
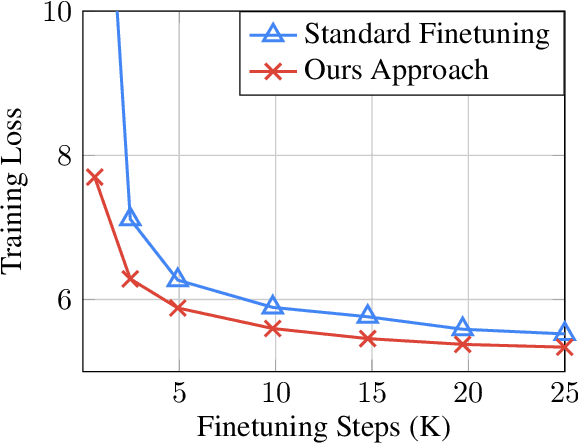
Jan 29, 2026Effective relevance modeling is crucial for e-commerce search, as it aligns search results with user intent and enhances customer experience. Recent work has leveraged large language models (LLMs) to address the limitations of traditional relevance models, especially for long-tail and ambiguous queries. By incorporating Chain-of-Thought (CoT) reasoning, these approaches improve both accuracy and interpretability through multi-step reasoning. However, two key limitations remain: (1) most existing approaches rely on single-perspective CoT reasoning, which fails to capture the multifaceted nature of e-commerce relevance (e.g., user intent vs. attribute-level matching vs. business-specific rules); and (2) although CoT-enhanced LLM's offer rich reasoning capabilities, their high inference latency necessitates knowledge distillation for real-time deployment, yet current distillation methods discard the CoT rationale structure at inference, using it as a transient auxiliary signal and forfeiting its reasoning utility. To address these challenges, we propose a novel framework that better exploits CoT semantics throughout the optimization pipeline. Specifically, the teacher model leverages Multi-Perspective CoT (MPCoT) to generate diverse rationales and combines Supervised Fine-Tuning (SFT) with Direct Preference Optimization (DPO) to construct a more robust reasoner. For distillation, we introduce Latent Reasoning Knowledge Distillation (LRKD), which endows a student model with a lightweight inference-time latent reasoning extractor, allowing efficient and low-latency internalization of the LLM's sophisticated reasoning capabilities. Evaluated in offline experiments and online A/B tests on an e-commerce search advertising platform serving tens of millions of users daily, our method delivers significant offline gains, showing clear benefits in both commercial performance and user experience.
Self-Evolution Knowledge Distillation for LLM-based Machine Translation
Dec 19, 2024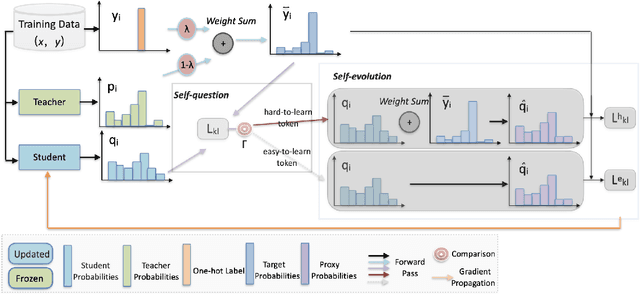
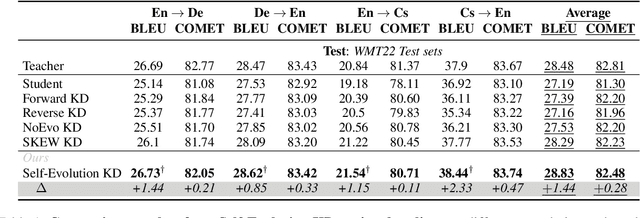
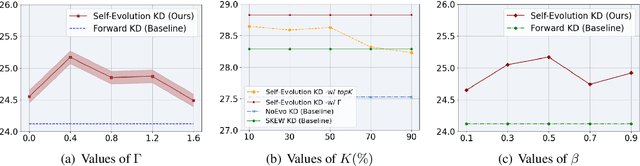
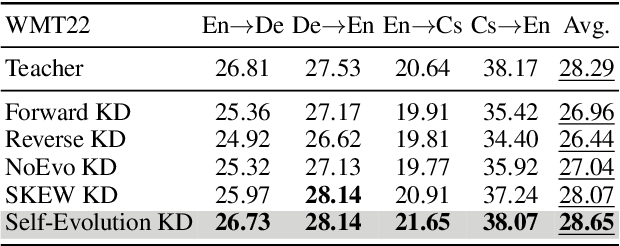
Knowledge distillation (KD) has shown great promise in transferring knowledge from larger teacher models to smaller student models. However, existing KD strategies for large language models often minimize output distributions between student and teacher models indiscriminately for each token. This overlooks the imbalanced nature of tokens and their varying transfer difficulties. In response, we propose a distillation strategy called Self-Evolution KD. The core of this approach involves dynamically integrating teacher distribution and one-hot distribution of ground truth into the student distribution as prior knowledge, which promotes the distillation process. It adjusts the ratio of prior knowledge based on token learning difficulty, fully leveraging the teacher model's potential. Experimental results show our method brings an average improvement of approximately 1.4 SacreBLEU points across four translation directions in the WMT22 test sets. Further analysis indicates that the improvement comes from better knowledge transfer from teachers, confirming our hypothesis.
Building Accurate Translation-Tailored LLMs with Language Aware Instruction Tuning
Mar 21, 2024Translation-tailored Large language models (LLMs) exhibit remarkable translation capabilities, even competing with supervised-trained commercial translation systems. However, off-target translation remains an unsolved problem, especially for low-resource languages, hindering us from developing accurate LLMs-based translation models. To mitigate the off-target translation problem and enhance the performance of LLMs on translation, recent works have either designed advanced prompting strategies to highlight the functionality of translation instructions or exploited the in-context learning ability of LLMs by feeding few-shot demonstrations. However, these methods essentially do not improve LLM's ability to follow translation instructions, especially the language direction information. In this work, we design a two-stage fine-tuning algorithm to improve the instruction-following ability (especially the translation direction) of LLMs. Specifically, we first tune LLMs with the maximum likelihood estimation loss on the translation dataset to elicit the basic translation capabilities. In the second stage, we construct instruction-conflicting samples by randomly replacing the translation directions with a wrong one within the instruction, and then introduce an extra unlikelihood loss to learn those samples. Experiments on IWSLT and WMT benchmarks upon the LLaMA model spanning 16 zero-shot directions show that, compared to the competitive baseline -- translation-finetuned LLama, our method could effectively reduce the off-target translation ratio (averagely -53.3\%), thus improving translation quality with average +5.7 SacreBLEU and +16.4 BLEURT. Analysis shows that our method could preserve the model's general task performance on AlpacaEval. Code and models will be released at \url{https://github.com/alphadl/LanguageAware_Tuning}.
Unlikelihood Tuning on Negative Samples Amazingly Improves Zero-Shot Translation
Sep 28, 2023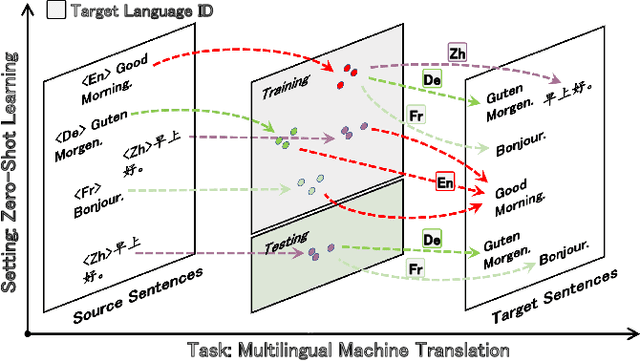
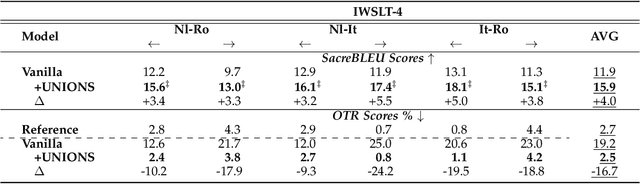
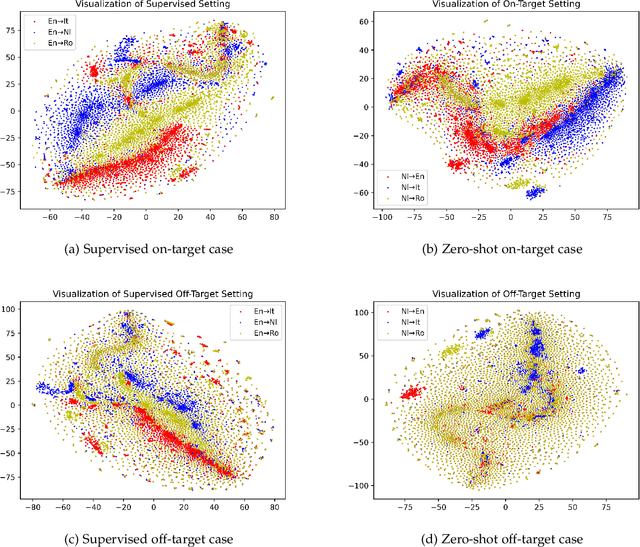
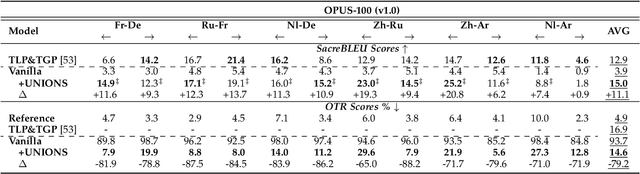
Zero-shot translation (ZST), which is generally based on a multilingual neural machine translation model, aims to translate between unseen language pairs in training data. The common practice to guide the zero-shot language mapping during inference is to deliberately insert the source and target language IDs, e.g., <EN> for English and <DE> for German. Recent studies have shown that language IDs sometimes fail to navigate the ZST task, making them suffer from the off-target problem (non-target language words exist in the generated translation) and, therefore, difficult to apply the current multilingual translation model to a broad range of zero-shot language scenarios. To understand when and why the navigation capabilities of language IDs are weakened, we compare two extreme decoder input cases in the ZST directions: Off-Target (OFF) and On-Target (ON) cases. By contrastively visualizing the contextual word representations (CWRs) of these cases with teacher forcing, we show that 1) the CWRs of different languages are effectively distributed in separate regions when the sentence and ID are matched (ON setting), and 2) if the sentence and ID are unmatched (OFF setting), the CWRs of different languages are chaotically distributed. Our analyses suggest that although they work well in ideal ON settings, language IDs become fragile and lose their navigation ability when faced with off-target tokens, which commonly exist during inference but are rare in training scenarios. In response, we employ unlikelihood tuning on the negative (OFF) samples to minimize their probability such that the language IDs can discriminate between the on- and off-target tokens during training. Experiments spanning 40 ZST directions show that our method reduces the off-target ratio by -48.0% on average, leading to a +9.1 BLEU improvement with only an extra +0.3% tuning cost.
Unsupervised Dense Retrieval with Relevance-Aware Contrastive Pre-Training
Jun 05, 2023
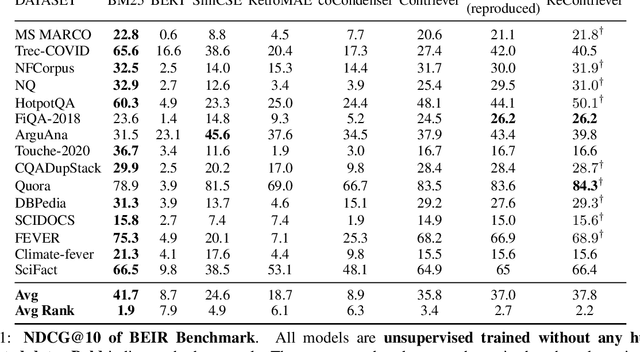
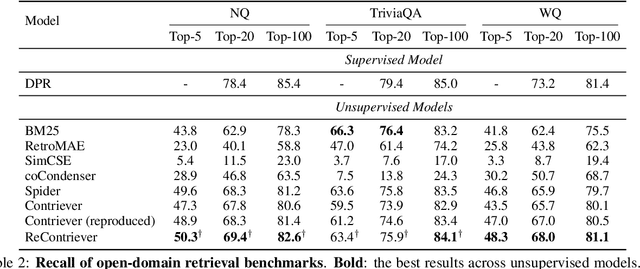
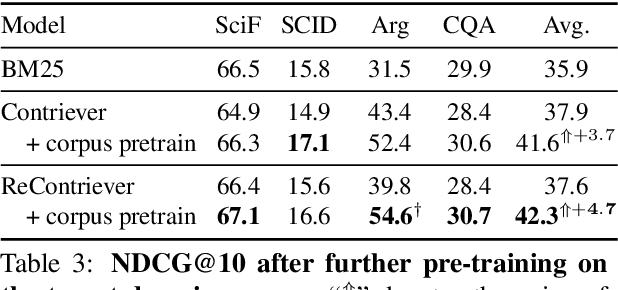
Dense retrievers have achieved impressive performance, but their demand for abundant training data limits their application scenarios. Contrastive pre-training, which constructs pseudo-positive examples from unlabeled data, has shown great potential to solve this problem. However, the pseudo-positive examples crafted by data augmentations can be irrelevant. To this end, we propose relevance-aware contrastive learning. It takes the intermediate-trained model itself as an imperfect oracle to estimate the relevance of positive pairs and adaptively weighs the contrastive loss of different pairs according to the estimated relevance. Our method consistently improves the SOTA unsupervised Contriever model on the BEIR and open-domain QA retrieval benchmarks. Further exploration shows that our method can not only beat BM25 after further pre-training on the target corpus but also serves as a good few-shot learner. Our code is publicly available at https://github.com/Yibin-Lei/ReContriever.
Prompt-Learning for Cross-Lingual Relation Extraction
Apr 20, 2023Relation Extraction (RE) is a crucial task in Information Extraction, which entails predicting relationships between entities within a given sentence. However, extending pre-trained RE models to other languages is challenging, particularly in real-world scenarios where Cross-Lingual Relation Extraction (XRE) is required. Despite recent advancements in Prompt-Learning, which involves transferring knowledge from Multilingual Pre-trained Language Models (PLMs) to diverse downstream tasks, there is limited research on the effective use of multilingual PLMs with prompts to improve XRE. In this paper, we present a novel XRE algorithm based on Prompt-Tuning, referred to as Prompt-XRE. To evaluate its effectiveness, we design and implement several prompt templates, including hard, soft, and hybrid prompts, and empirically test their performance on competitive multilingual PLMs, specifically mBART. Our extensive experiments, conducted on the low-resource ACE05 benchmark across multiple languages, demonstrate that our Prompt-XRE algorithm significantly outperforms both vanilla multilingual PLMs and other existing models, achieving state-of-the-art performance in XRE. To further show the generalization of our Prompt-XRE on larger data scales, we construct and release a new XRE dataset- WMT17-EnZh XRE, containing 0.9M English-Chinese pairs extracted from WMT 2017 parallel corpus. Experiments on WMT17-EnZh XRE also show the effectiveness of our Prompt-XRE against other competitive baselines. The code and newly constructed dataset are freely available at \url{https://github.com/HSU-CHIA-MING/Prompt-XRE}.
Vega-MT: The JD Explore Academy Translation System for WMT22
Sep 21, 2022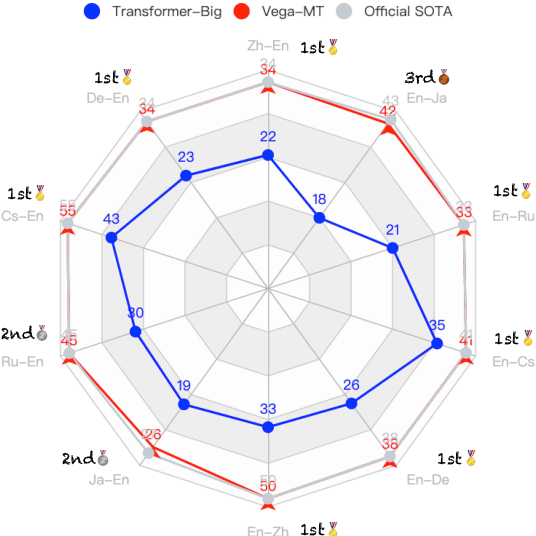
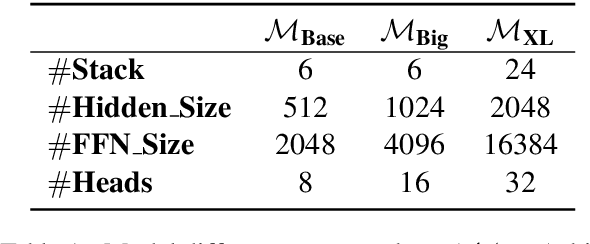
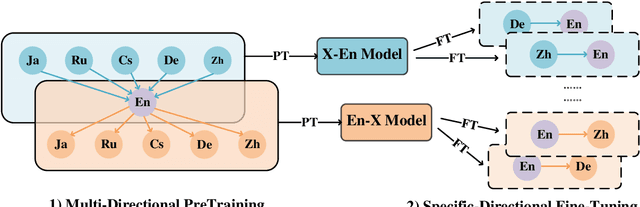

We describe the JD Explore Academy's submission of the WMT 2022 shared general translation task. We participated in all high-resource tracks and one medium-resource track, including Chinese-English, German-English, Czech-English, Russian-English, and Japanese-English. We push the limit of our previous work -- bidirectional training for translation by scaling up two main factors, i.e. language pairs and model sizes, namely the \textbf{Vega-MT} system. As for language pairs, we scale the "bidirectional" up to the "multidirectional" settings, covering all participating languages, to exploit the common knowledge across languages, and transfer them to the downstream bilingual tasks. As for model sizes, we scale the Transformer-Big up to the extremely large model that owns nearly 4.7 Billion parameters, to fully enhance the model capacity for our Vega-MT. Also, we adopt the data augmentation strategies, e.g. cycle translation for monolingual data, and bidirectional self-training for bilingual and monolingual data, to comprehensively exploit the bilingual and monolingual data. To adapt our Vega-MT to the general domain test set, generalization tuning is designed. Based on the official automatic scores of constrained systems, in terms of the sacreBLEU shown in Figure-1, we got the 1st place on {Zh-En (33.5), En-Zh (49.7), De-En (33.7), En-De (37.8), Cs-En (54.9), En-Cs (41.4) and En-Ru (32.7)}, 2nd place on {Ru-En (45.1) and Ja-En (25.6)}, and 3rd place on {En-Ja(41.5)}, respectively; W.R.T the COMET, we got the 1st place on {Zh-En (45.1), En-Zh (61.7), De-En (58.0), En-De (63.2), Cs-En (74.7), Ru-En (64.9), En-Ru (69.6) and En-Ja (65.1)}, 2nd place on {En-Cs (95.3) and Ja-En (40.6)}, respectively. Models will be released to facilitate the MT community through GitHub and OmniForce Platform.
On the Complementarity between Pre-Training and Random-Initialization for Resource-Rich Machine Translation
Sep 15, 2022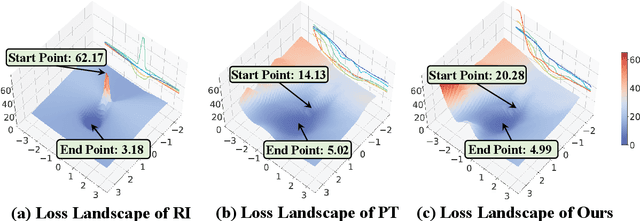
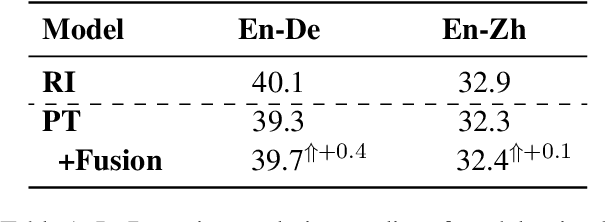
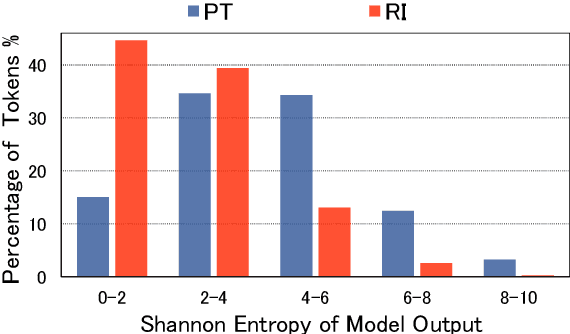
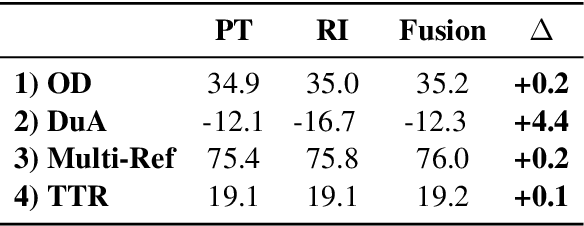
Pre-Training (PT) of text representations has been successfully applied to low-resource Neural Machine Translation (NMT). However, it usually fails to achieve notable gains (sometimes, even worse) on resource-rich NMT on par with its Random-Initialization (RI) counterpart. We take the first step to investigate the complementarity between PT and RI in resource-rich scenarios via two probing analyses, and find that: 1) PT improves NOT the accuracy, but the generalization by achieving flatter loss landscapes than that of RI; 2) PT improves NOT the confidence of lexical choice, but the negative diversity by assigning smoother lexical probability distributions than that of RI. Based on these insights, we propose to combine their complementarities with a model fusion algorithm that utilizes optimal transport to align neurons between PT and RI. Experiments on two resource-rich translation benchmarks, WMT'17 English-Chinese (20M) and WMT'19 English-German (36M), show that PT and RI could be nicely complementary to each other, achieving substantial improvements considering both translation accuracy, generalization, and negative diversity. Probing tools and code are released at: https://github.com/zanchangtong/PTvsRI.
Bridging Cross-Lingual Gaps During Leveraging the Multilingual Sequence-to-Sequence Pretraining for Text Generation
Apr 16, 2022
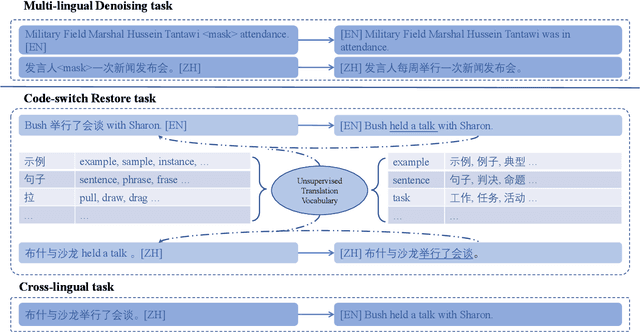
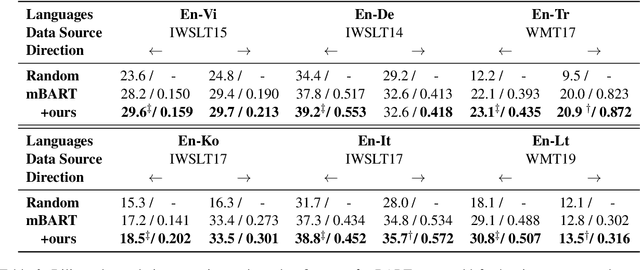
For multilingual sequence-to-sequence pretrained language models (multilingual Seq2Seq PLMs), e.g. mBART, the self-supervised pretraining task is trained on a wide range of monolingual languages, e.g. 25 languages from commoncrawl, while the downstream cross-lingual tasks generally progress on a bilingual language subset, e.g. English-German, making there exists the cross-lingual data discrepancy, namely \textit{domain discrepancy}, and cross-lingual learning objective discrepancy, namely \textit{task discrepancy}, between the pretrain and finetune stages. To bridge the above cross-lingual domain and task gaps, we extend the vanilla pretrain-finetune pipeline with extra code-switching restore task. Specifically, the first stage employs the self-supervised code-switching restore task as a pretext task, allowing the multilingual Seq2Seq PLM to acquire some in-domain alignment information. And for the second stage, we continuously fine-tune the model on labeled data normally. Experiments on a variety of cross-lingual NLG tasks, including 12 bilingual translation tasks, 36 zero-shot translation tasks, and cross-lingual summarization tasks show our model outperforms the strong baseline mBART consistently. Comprehensive analyses indicate our approach could narrow the cross-lingual sentence representation distance and improve low-frequency word translation with trivial computational cost.