 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Scalar Scores: Exploring LLM-based Metrics for Clinical Significance Evaluation in Radiology Reports
Jun 17, 2026Reliable evaluation of generated radiology reports requires strict clinical accuracy, as omitted critical findings or mischaracterized radiographic observations can directly affect patient care. Existing metrics obscure this requirement by reducing report quality to a medically ungrounded scalar. Although Large Language Models (LLMs) possess rich medical knowledge, they likewise struggle to draw a reliable boundary between clinically significant errors and harmless variation. We study this boundary using ReEvalMed benchmark as testbed and evaluate metric-level clinical significance from detecting true clinical errors ("Discrimination") and tolerating insignificant variations ("Robustness"). Across 8 LLM evaluators under one-pass and two-pass settings, we identify a widespread discrimination bias: models effectively detect errors but also over-penalize harmless rephrasings. To mitigate this, we synthesize 4k report pairs and train lightweight interpretable metrics on Qwen3-8B and MedGemma-4B. Our trained metric sharpens the clinical significance boundary, surpassing 32B-scale medical LLMs and remaining competitive with proprietary models. Crucially, the more costly two-pass setting fails to consistently improve overall performance and mainly trades discrimination for robustness. These findings suggest one-pass trained metrics as the practical choice for cost-sensitive deployment, with two-pass inference reserved for settings where D-R balance is critical. We will release the dataset and metric.
The Bitter Lesson of Diffusion Language Models for Agentic Workflows: A Comprehensive Reality Check
Jan 19, 2026The pursuit of real-time agentic interaction has driven interest in Diffusion-based Large Language Models (dLLMs) as alternatives to auto-regressive backbones, promising to break the sequential latency bottleneck. However, does such efficiency gains translate into effective agentic behavior? In this work, we present a comprehensive evaluation of dLLMs (e.g., LLaDA, Dream) across two distinct agentic paradigms: Embodied Agents (requiring long-horizon planning) and Tool-Calling Agents (requiring precise formatting). Contrary to the efficiency hype, our results on Agentboard and BFCL reveal a "bitter lesson": current dLLMs fail to serve as reliable agentic backbones, frequently leading to systematically failure. (1) In Embodied settings, dLLMs suffer repeated attempts, failing to branch under temporal feedback. (2) In Tool-Calling settings, dLLMs fail to maintain symbolic precision (e.g. strict JSON schemas) under diffusion noise. To assess the potential of dLLMs in agentic workflows, we introduce DiffuAgent, a multi-agent evaluation framework that integrates dLLMs as plug-and-play cognitive cores. Our analysis shows that dLLMs are effective in non-causal roles (e.g., memory summarization and tool selection) but require the incorporation of causal, precise, and logically grounded reasoning mechanisms into the denoising process to be viable for agentic tasks.
SurgGoal: Rethinking Surgical Planning Evaluation via Goal-Satisfiability
Jan 15, 2026Surgical planning integrates visual perception, long-horizon reasoning, and procedural knowledge, yet it remains unclear whether current evaluation protocols reliably assess vision-language models (VLMs) in safety-critical settings. Motivated by a goal-oriented view of surgical planning, we define planning correctness via phase-goal satisfiability, where plan validity is determined by expert-defined surgical rules. Based on this definition, we introduce a multicentric meta-evaluation benchmark with valid procedural variations and invalid plans containing order and content errors. Using this benchmark, we show that sequence similarity metrics systematically misjudge planning quality, penalizing valid plans while failing to identify invalid ones. We therefore adopt a rule-based goal-satisfiability metric as a high-precision meta-evaluation reference to assess Video-LLMs under progressively constrained settings, revealing failures due to perception errors and under-constrained reasoning. Structural knowledge consistently improves performance, whereas semantic guidance alone is unreliable and benefits larger models only when combined with structural constraints.
Runaway is Ashamed, But Helpful: On the Early-Exit Behavior of Large Language Model-based Agents in Embodied Environments
May 23, 2025Agents powered by large language models (LLMs) have demonstrated strong planning and decision-making capabilities in complex embodied environments. However, such agents often suffer from inefficiencies in multi-turn interactions, frequently trapped in repetitive loops or issuing ineffective commands, leading to redundant computational overhead. Instead of relying solely on learning from trajectories, we take a first step toward exploring the early-exit behavior for LLM-based agents. We propose two complementary approaches: 1. an $\textbf{intrinsic}$ method that injects exit instructions during generation, and 2. an $\textbf{extrinsic}$ method that verifies task completion to determine when to halt an agent's trial. To evaluate early-exit mechanisms, we introduce two metrics: one measures the reduction of $\textbf{redundant steps}$ as a positive effect, and the other evaluates $\textbf{progress degradation}$ as a negative effect. Experiments with 4 different LLMs across 5 embodied environments show significant efficiency improvements, with only minor drops in agent performance. We also validate a practical strategy where a stronger agent assists after an early-exit agent, achieving better performance with the same total steps. We will release our code to support further research.
Multi-modal clothing recommendation model based on large model and VAE enhancement
Oct 03, 2024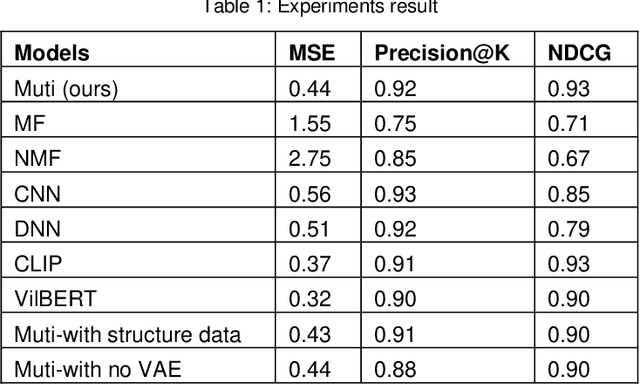
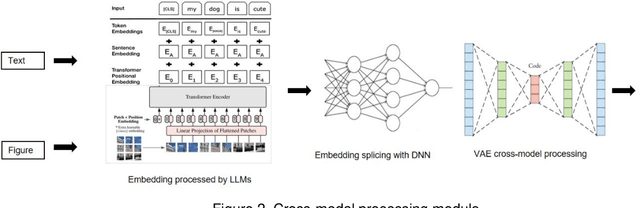
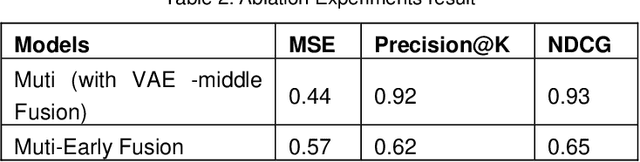
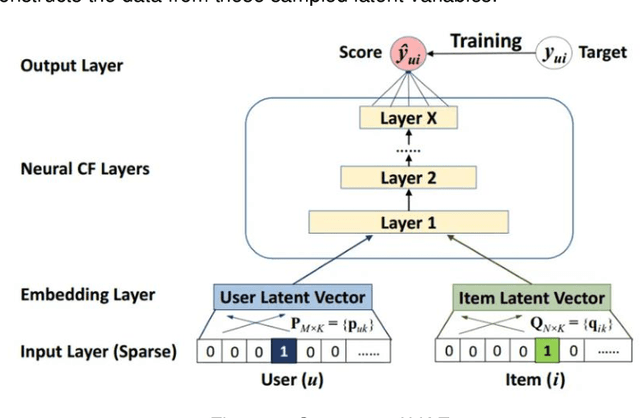
Accurately recommending products has long been a subject requiring in-depth research. This study proposes a multimodal paradigm for clothing recommendations. Specifically, it designs a multimodal analysis method that integrates clothing description texts and images, utilizing a pre-trained large language model to deeply explore the hidden meanings of users and products. Additionally, a variational encoder is employed to learn the relationship between user information and products to address the cold start problem in recommendation systems. This study also validates the significant performance advantages of this method over various recommendation system methods through extensive ablation experiments, providing crucial practical guidance for the comprehensive optimization of recommendation systems.
MQM-APE: Toward High-Quality Error Annotation Predictors with Automatic Post-Editing in LLM Translation Evaluators
Sep 22, 2024Large Language Models (LLMs) have shown significant potential as judges for Machine Translation (MT) quality assessment, providing both scores and fine-grained feedback. Although approaches such as GEMBA-MQM has shown SOTA performance on reference-free evaluation, the predicted errors do not align well with those annotated by human, limiting their interpretability as feedback signals. To enhance the quality of error annotations predicted by LLM evaluators, we introduce a universal and training-free framework, $\textbf{MQM-APE}$, based on the idea of filtering out non-impactful errors by Automatically Post-Editing (APE) the original translation based on each error, leaving only those errors that contribute to quality improvement. Specifically, we prompt the LLM to act as 1) $\textit{evaluator}$ to provide error annotations, 2) $\textit{post-editor}$ to determine whether errors impact quality improvement and 3) $\textit{pairwise quality verifier}$ as the error filter. Experiments show that our approach consistently improves both the reliability and quality of error spans against GEMBA-MQM, across eight LLMs in both high- and low-resource languages. Orthogonal to trained approaches, MQM-APE complements translation-specific evaluators such as Tower, highlighting its broad applicability. Further analysis confirm the effectiveness of each module and offer valuable insights into evaluator design and LLMs selection. The code will be released to facilitate the community.
Error Analysis Prompting Enables Human-Like Translation Evaluation in Large Language Models: A Case Study on ChatGPT
Mar 24, 2023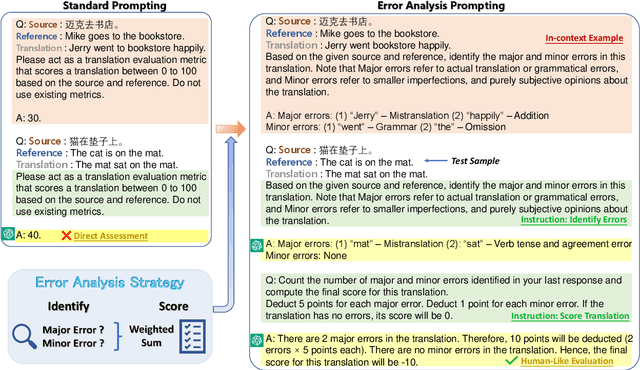
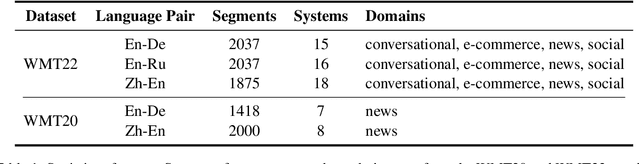
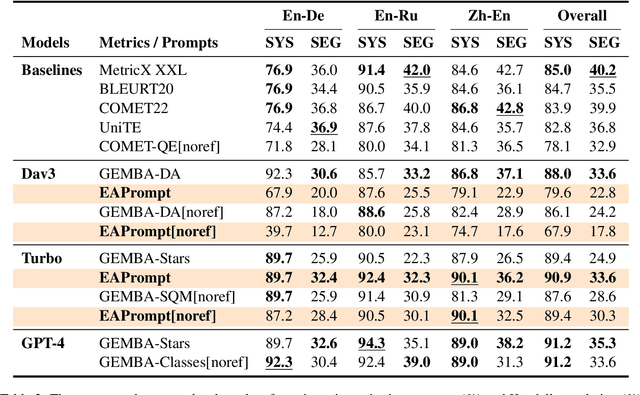
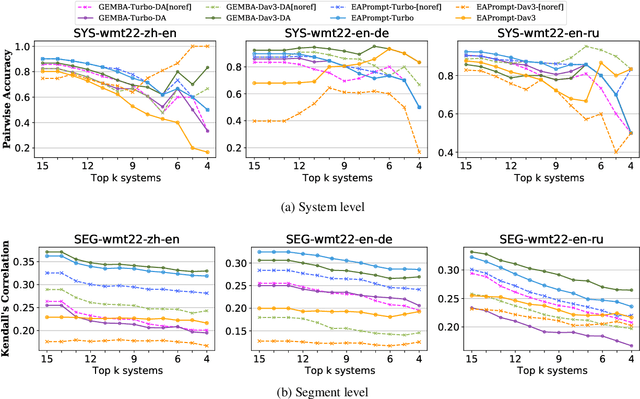
Generative large language models (LLMs), e.g., ChatGPT, have demonstrated remarkable proficiency across several NLP tasks such as machine translation, question answering, text summarization, and natural language understanding. Recent research has shown that utilizing ChatGPT for assessing the quality of machine translation (MT) achieves state-of-the-art performance at the system level but performs poorly at the segment level. To further improve the performance of LLMs on MT quality assessment, we conducted an investigation into several prompting methods. Our results indicate that by combining Chain-of-Thoughts and Error Analysis, a new prompting method called \textbf{\texttt{Error Analysis Prompting}}, LLMs like ChatGPT can \textit{generate human-like MT evaluations at both the system and segment level}. Additionally, we discovered some limitations of ChatGPT as an MT evaluator, such as unstable scoring and biases when provided with multiple translations in a single query. Our findings aim to provide a preliminary experience for appropriately evaluating translation quality on ChatGPT while offering a variety of tricks in designing prompts for in-context learning. We anticipate that this report will shed new light on advancing the field of translation evaluation with LLMs by enhancing both the accuracy and reliability of metrics. The project can be found in \url{https://github.com/Coldmist-Lu/ErrorAnalysis_Prompt}.
Toward Human-Like Evaluation for Natural Language Generation with Error Analysis
Dec 20, 2022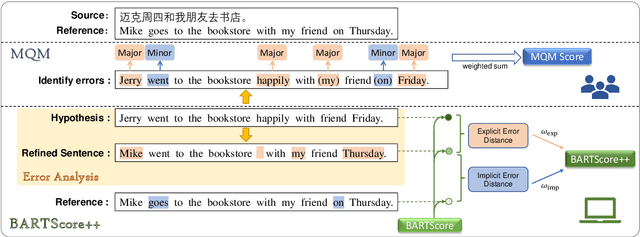


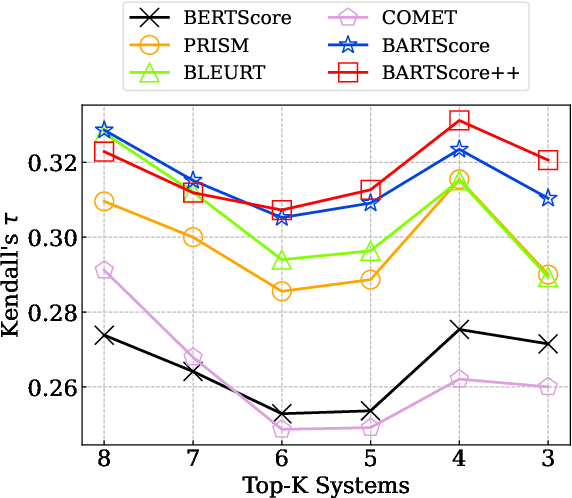
The state-of-the-art language model-based automatic metrics, e.g. BARTScore, benefiting from large-scale contextualized pre-training, have been successfully used in a wide range of natural language generation (NLG) tasks, including machine translation, text summarization, and data-to-text. Recent studies show that considering both major errors (e.g. mistranslated tokens) and minor errors (e.g. imperfections in fluency) can produce high-quality human judgments. This inspires us to approach the final goal of the evaluation metrics (human-like evaluations) by automatic error analysis. To this end, we augment BARTScore by incorporating the human-like error analysis strategies, namely BARTScore++, where the final score consists of both the evaluations of major errors and minor errors. Experimental results show that BARTScore++ can consistently improve the performance of vanilla BARTScore and outperform existing top-scoring metrics in 20 out of 25 test settings. We hope our technique can also be extended to other pre-trained model-based metrics. We will release our code and scripts to facilitate the community.
Vega-MT: The JD Explore Academy Translation System for WMT22
Sep 21, 2022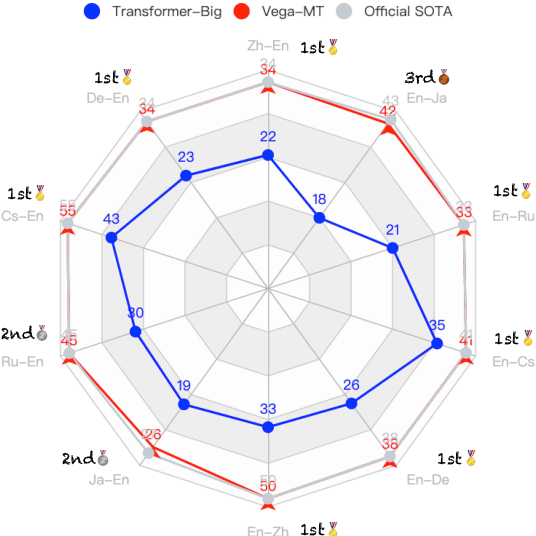
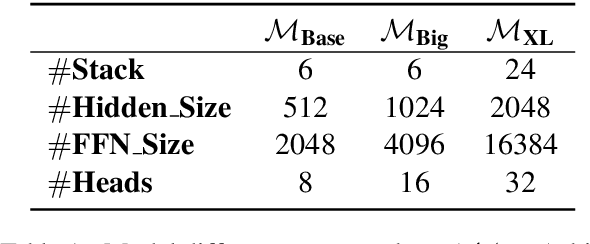
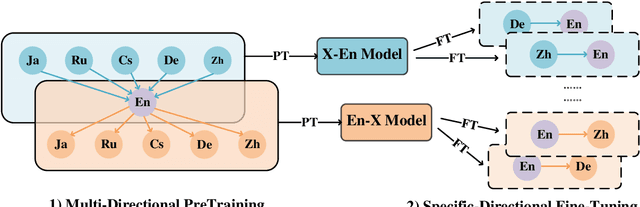

We describe the JD Explore Academy's submission of the WMT 2022 shared general translation task. We participated in all high-resource tracks and one medium-resource track, including Chinese-English, German-English, Czech-English, Russian-English, and Japanese-English. We push the limit of our previous work -- bidirectional training for translation by scaling up two main factors, i.e. language pairs and model sizes, namely the \textbf{Vega-MT} system. As for language pairs, we scale the "bidirectional" up to the "multidirectional" settings, covering all participating languages, to exploit the common knowledge across languages, and transfer them to the downstream bilingual tasks. As for model sizes, we scale the Transformer-Big up to the extremely large model that owns nearly 4.7 Billion parameters, to fully enhance the model capacity for our Vega-MT. Also, we adopt the data augmentation strategies, e.g. cycle translation for monolingual data, and bidirectional self-training for bilingual and monolingual data, to comprehensively exploit the bilingual and monolingual data. To adapt our Vega-MT to the general domain test set, generalization tuning is designed. Based on the official automatic scores of constrained systems, in terms of the sacreBLEU shown in Figure-1, we got the 1st place on {Zh-En (33.5), En-Zh (49.7), De-En (33.7), En-De (37.8), Cs-En (54.9), En-Cs (41.4) and En-Ru (32.7)}, 2nd place on {Ru-En (45.1) and Ja-En (25.6)}, and 3rd place on {En-Ja(41.5)}, respectively; W.R.T the COMET, we got the 1st place on {Zh-En (45.1), En-Zh (61.7), De-En (58.0), En-De (63.2), Cs-En (74.7), Ru-En (64.9), En-Ru (69.6) and En-Ja (65.1)}, 2nd place on {En-Cs (95.3) and Ja-En (40.6)}, respectively. Models will be released to facilitate the MT community through GitHub and OmniForce Platform.