 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Broad, Acting Fast: Latent Reasoning Distillation from Multi-Perspective Chain-of-Thought for E-Commerce Relevance
Jan 29, 2026Effective relevance modeling is crucial for e-commerce search, as it aligns search results with user intent and enhances customer experience. Recent work has leveraged large language models (LLMs) to address the limitations of traditional relevance models, especially for long-tail and ambiguous queries. By incorporating Chain-of-Thought (CoT) reasoning, these approaches improve both accuracy and interpretability through multi-step reasoning. However, two key limitations remain: (1) most existing approaches rely on single-perspective CoT reasoning, which fails to capture the multifaceted nature of e-commerce relevance (e.g., user intent vs. attribute-level matching vs. business-specific rules); and (2) although CoT-enhanced LLM's offer rich reasoning capabilities, their high inference latency necessitates knowledge distillation for real-time deployment, yet current distillation methods discard the CoT rationale structure at inference, using it as a transient auxiliary signal and forfeiting its reasoning utility. To address these challenges, we propose a novel framework that better exploits CoT semantics throughout the optimization pipeline. Specifically, the teacher model leverages Multi-Perspective CoT (MPCoT) to generate diverse rationales and combines Supervised Fine-Tuning (SFT) with Direct Preference Optimization (DPO) to construct a more robust reasoner. For distillation, we introduce Latent Reasoning Knowledge Distillation (LRKD), which endows a student model with a lightweight inference-time latent reasoning extractor, allowing efficient and low-latency internalization of the LLM's sophisticated reasoning capabilities. Evaluated in offline experiments and online A/B tests on an e-commerce search advertising platform serving tens of millions of users daily, our method delivers significant offline gains, showing clear benefits in both commercial performance and user experience.
Error Analysis Prompting Enables Human-Like Translation Evaluation in Large Language Models: A Case Study on ChatGPT
Mar 24, 2023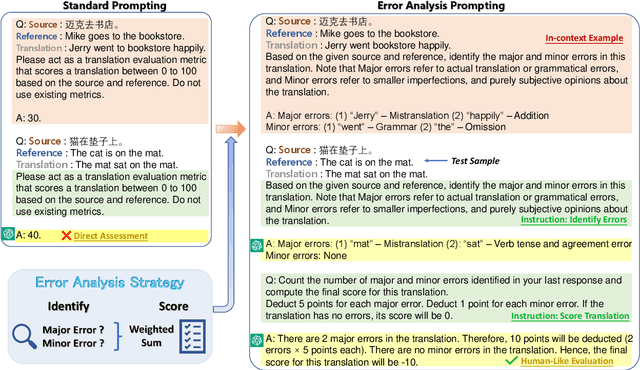
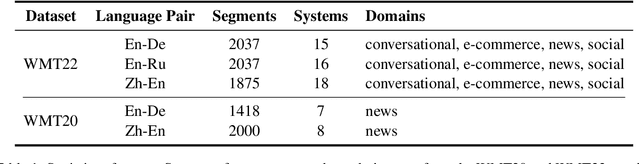
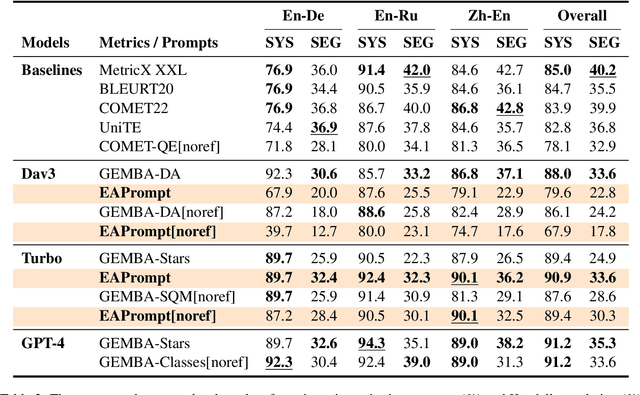
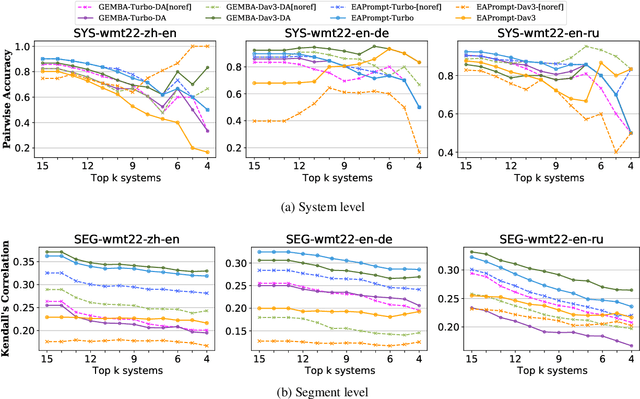
Generative large language models (LLMs), e.g., ChatGPT, have demonstrated remarkable proficiency across several NLP tasks such as machine translation, question answering, text summarization, and natural language understanding. Recent research has shown that utilizing ChatGPT for assessing the quality of machine translation (MT) achieves state-of-the-art performance at the system level but performs poorly at the segment level. To further improve the performance of LLMs on MT quality assessment, we conducted an investigation into several prompting methods. Our results indicate that by combining Chain-of-Thoughts and Error Analysis, a new prompting method called \textbf{\texttt{Error Analysis Prompting}}, LLMs like ChatGPT can \textit{generate human-like MT evaluations at both the system and segment level}. Additionally, we discovered some limitations of ChatGPT as an MT evaluator, such as unstable scoring and biases when provided with multiple translations in a single query. Our findings aim to provide a preliminary experience for appropriately evaluating translation quality on ChatGPT while offering a variety of tricks in designing prompts for in-context learning. We anticipate that this report will shed new light on advancing the field of translation evaluation with LLMs by enhancing both the accuracy and reliability of metrics. The project can be found in \url{https://github.com/Coldmist-Lu/ErrorAnalysis_Prompt}.
Original or Translated? On the Use of Parallel Data for Translation Quality Estimation
Dec 20, 2022



Machine Translation Quality Estimation (QE) is the task of evaluating translation output in the absence of human-written references. Due to the scarcity of human-labeled QE data, previous works attempted to utilize the abundant unlabeled parallel corpora to produce additional training data with pseudo labels. In this paper, we demonstrate a significant gap between parallel data and real QE data: for QE data, it is strictly guaranteed that the source side is original texts and the target side is translated (namely translationese). However, for parallel data, it is indiscriminate and the translationese may occur on either source or target side. We compare the impact of parallel data with different translation directions in QE data augmentation, and find that using the source-original part of parallel corpus consistently outperforms its target-original counterpart. Moreover, since the WMT corpus lacks direction information for each parallel sentence, we train a classifier to distinguish source- and target-original bitext, and carry out an analysis of their difference in both style and domain. Together, these findings suggest using source-original parallel data for QE data augmentation, which brings a relative improvement of up to 4.0% and 6.4% compared to undifferentiated data on sentence- and word-level QE tasks respectively.
Vega-MT: The JD Explore Academy Translation System for WMT22
Sep 21, 2022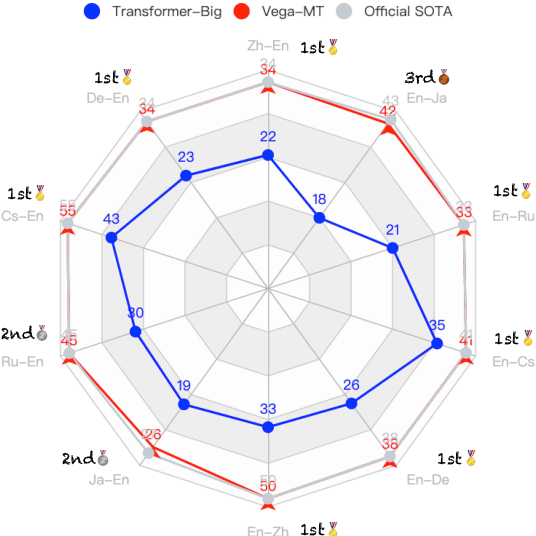
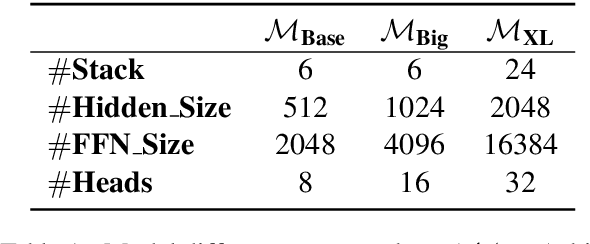
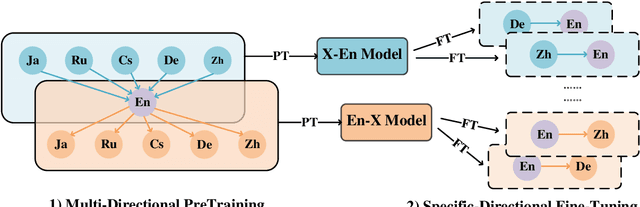

We describe the JD Explore Academy's submission of the WMT 2022 shared general translation task. We participated in all high-resource tracks and one medium-resource track, including Chinese-English, German-English, Czech-English, Russian-English, and Japanese-English. We push the limit of our previous work -- bidirectional training for translation by scaling up two main factors, i.e. language pairs and model sizes, namely the \textbf{Vega-MT} system. As for language pairs, we scale the "bidirectional" up to the "multidirectional" settings, covering all participating languages, to exploit the common knowledge across languages, and transfer them to the downstream bilingual tasks. As for model sizes, we scale the Transformer-Big up to the extremely large model that owns nearly 4.7 Billion parameters, to fully enhance the model capacity for our Vega-MT. Also, we adopt the data augmentation strategies, e.g. cycle translation for monolingual data, and bidirectional self-training for bilingual and monolingual data, to comprehensively exploit the bilingual and monolingual data. To adapt our Vega-MT to the general domain test set, generalization tuning is designed. Based on the official automatic scores of constrained systems, in terms of the sacreBLEU shown in Figure-1, we got the 1st place on {Zh-En (33.5), En-Zh (49.7), De-En (33.7), En-De (37.8), Cs-En (54.9), En-Cs (41.4) and En-Ru (32.7)}, 2nd place on {Ru-En (45.1) and Ja-En (25.6)}, and 3rd place on {En-Ja(41.5)}, respectively; W.R.T the COMET, we got the 1st place on {Zh-En (45.1), En-Zh (61.7), De-En (58.0), En-De (63.2), Cs-En (74.7), Ru-En (64.9), En-Ru (69.6) and En-Ja (65.1)}, 2nd place on {En-Cs (95.3) and Ja-En (40.6)}, respectively. Models will be released to facilitate the MT community through GitHub and OmniForce Platform.