 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Temporal Masked Attention for Cross-view Online Action Detection
Aug 23, 2025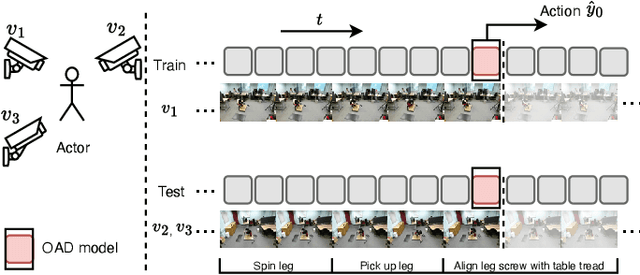
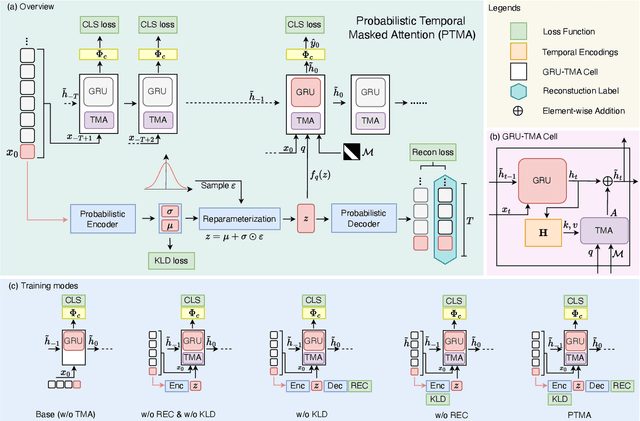
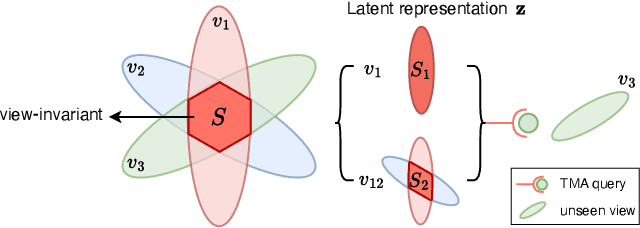
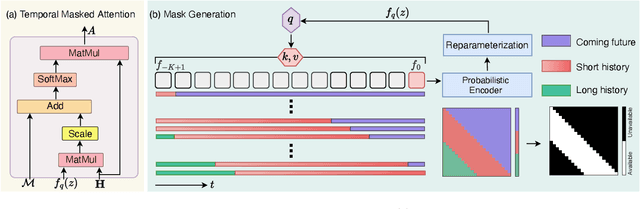
As a critical task in video sequence classification within computer vision, Online Action Detection (OAD) has garnered significant attention. The sensitivity of mainstream OAD models to varying video viewpoints often hampers their generalization when confronted with unseen sources. To address this limitation, we propose a novel Probabilistic Temporal Masked Attention (PTMA) model, which leverages probabilistic modeling to derive latent compressed representations of video frames in a cross-view setting. The PTMA model incorporates a GRU-based temporal masked attention (TMA) cell, which leverages these representations to effectively query the input video sequence, thereby enhancing information interaction and facilitating autoregressive frame-level video analysis. Additionally, multi-view information can be integrated into the probabilistic modeling to facilitate the extraction of view-invariant features. Experiments conducted under three evaluation protocols: cross-subject (cs), cross-view (cv), and cross-subject-view (csv) show that PTMA achieves state-of-the-art performance on the DAHLIA, IKEA ASM, and Breakfast datasets.
MALT: Multi-scale Action Learning Transformer for Online Action Detection
May 31, 2024Online action detection (OAD) aims to identify ongoing actions from streaming video in real-time, without access to future frames. Since these actions manifest at varying scales of granularity, ranging from coarse to fine, projecting an entire set of action frames to a single latent encoding may result in a lack of local information, necessitating the acquisition of action features across multiple scales. In this paper, we propose a multi-scale action learning transformer (MALT), which includes a novel recurrent decoder (used for feature fusion) that includes fewer parameters and can be trained more efficiently. A hierarchical encoder with multiple encoding branches is further proposed to capture multi-scale action features. The output from the preceding branch is then incrementally input to the subsequent branch as part of a cross-attention calculation. In this way, output features transition from coarse to fine as the branches deepen. We also introduce an explicit frame scoring mechanism employing sparse attention, which filters irrelevant frames more efficiently, without requiring an additional network. The proposed method achieved state-of-the-art performance on two benchmark datasets (THUMOS'14 and TVSeries), outperforming all existing models used for comparison, with an mAP of 0.2% for THUMOS'14 and an mcAP of 0.1% for TVseries.
Error Analysis Prompting Enables Human-Like Translation Evaluation in Large Language Models: A Case Study on ChatGPT
Mar 24, 2023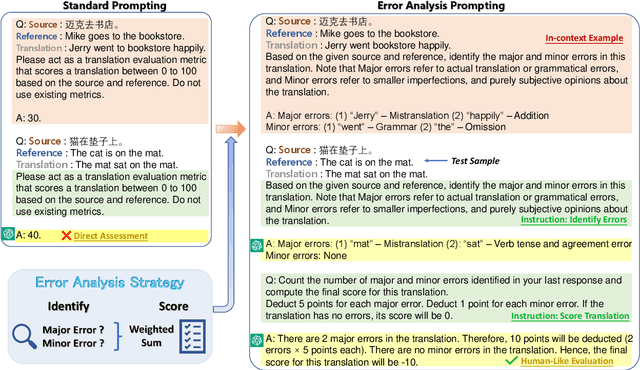
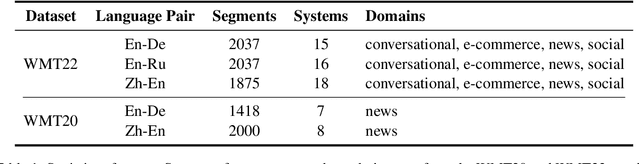
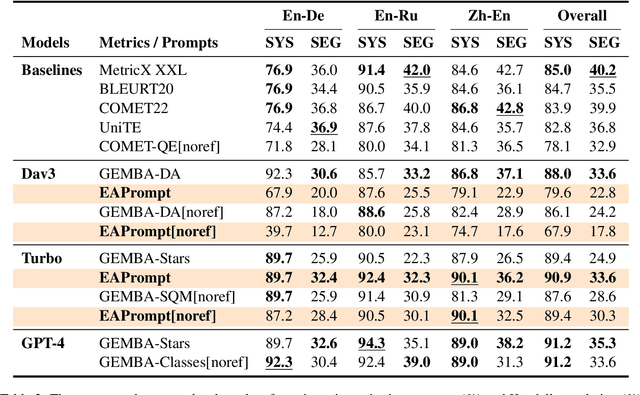
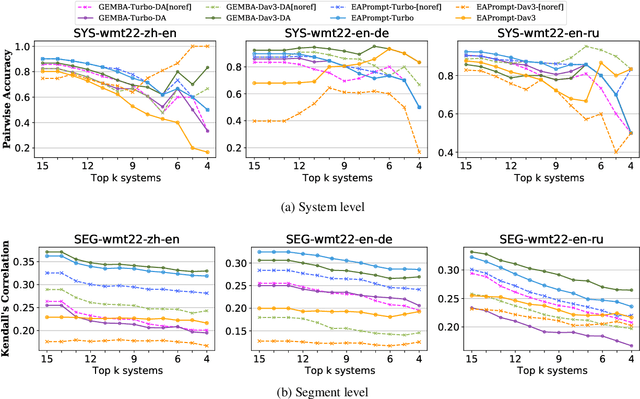
Generative large language models (LLMs), e.g., ChatGPT, have demonstrated remarkable proficiency across several NLP tasks such as machine translation, question answering, text summarization, and natural language understanding. Recent research has shown that utilizing ChatGPT for assessing the quality of machine translation (MT) achieves state-of-the-art performance at the system level but performs poorly at the segment level. To further improve the performance of LLMs on MT quality assessment, we conducted an investigation into several prompting methods. Our results indicate that by combining Chain-of-Thoughts and Error Analysis, a new prompting method called \textbf{\texttt{Error Analysis Prompting}}, LLMs like ChatGPT can \textit{generate human-like MT evaluations at both the system and segment level}. Additionally, we discovered some limitations of ChatGPT as an MT evaluator, such as unstable scoring and biases when provided with multiple translations in a single query. Our findings aim to provide a preliminary experience for appropriately evaluating translation quality on ChatGPT while offering a variety of tricks in designing prompts for in-context learning. We anticipate that this report will shed new light on advancing the field of translation evaluation with LLMs by enhancing both the accuracy and reliability of metrics. The project can be found in \url{https://github.com/Coldmist-Lu/ErrorAnalysis_Prompt}.
Toward Human-Like Evaluation for Natural Language Generation with Error Analysis
Dec 20, 2022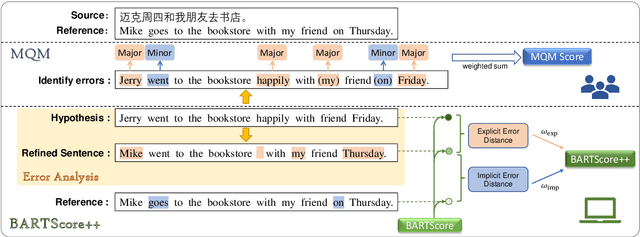


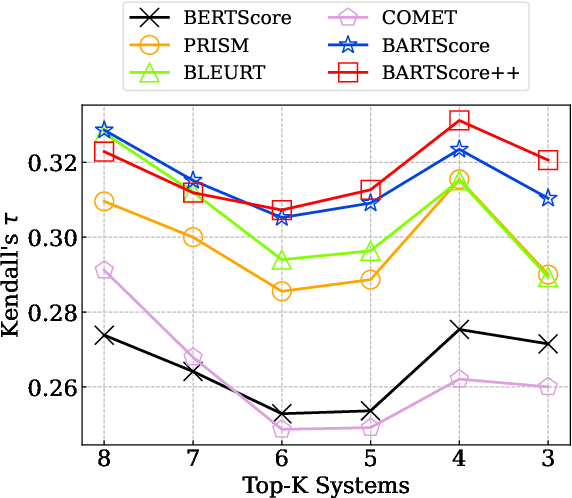
The state-of-the-art language model-based automatic metrics, e.g. BARTScore, benefiting from large-scale contextualized pre-training, have been successfully used in a wide range of natural language generation (NLG) tasks, including machine translation, text summarization, and data-to-text. Recent studies show that considering both major errors (e.g. mistranslated tokens) and minor errors (e.g. imperfections in fluency) can produce high-quality human judgments. This inspires us to approach the final goal of the evaluation metrics (human-like evaluations) by automatic error analysis. To this end, we augment BARTScore by incorporating the human-like error analysis strategies, namely BARTScore++, where the final score consists of both the evaluations of major errors and minor errors. Experimental results show that BARTScore++ can consistently improve the performance of vanilla BARTScore and outperform existing top-scoring metrics in 20 out of 25 test settings. We hope our technique can also be extended to other pre-trained model-based metrics. We will release our code and scripts to facilitate the community.
Probabilistic Decomposition Transformer for Time Series Forecasting
Oct 31, 2022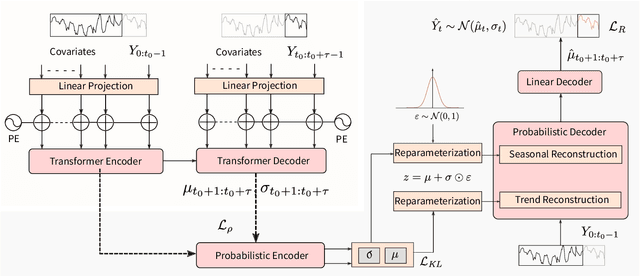
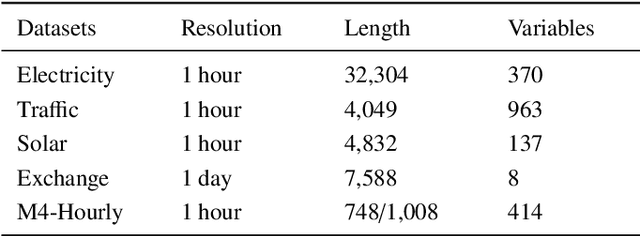
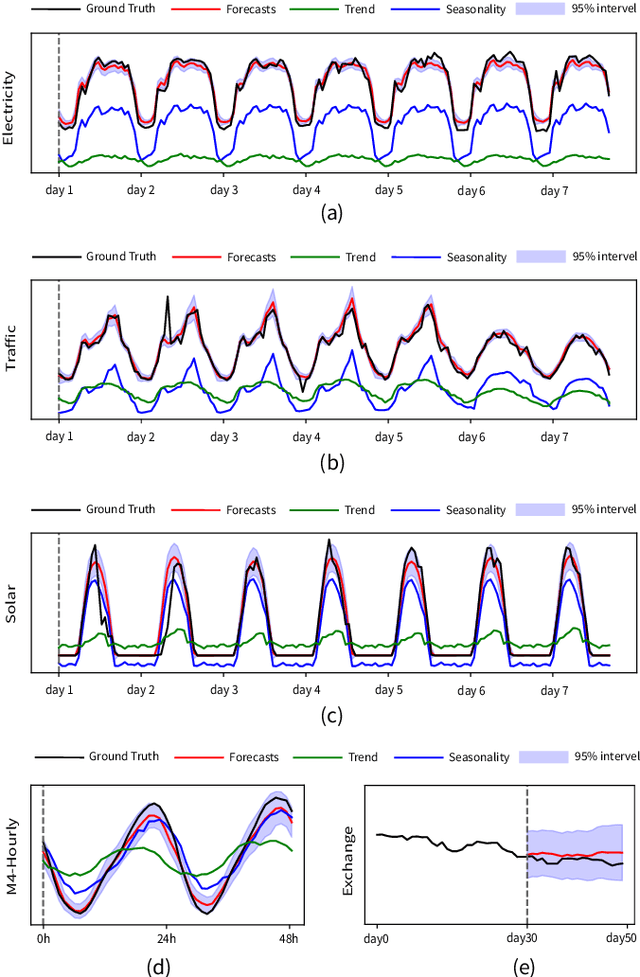
Time series forecasting is crucial for many fields, such as disaster warning, weather prediction, and energy consumption. The Transformer-based models are considered to have revolutionized the field of sequence modeling. However, the complex temporal patterns of the time series hinder the model from mining reliable temporal dependencies. Furthermore, the autoregressive form of the Transformer introduces cumulative errors in the inference step. In this paper, we propose the probabilistic decomposition Transformer model that combines the Transformer with a conditional generative model, which provides hierarchical and interpretable probabilistic forecasts for intricate time series. The Transformer is employed to learn temporal patterns and implement primary probabilistic forecasts, while the conditional generative model is used to achieve non-autoregressive hierarchical probabilistic forecasts by introducing latent space feature representations. In addition, the conditional generative model reconstructs typical features of the series, such as seasonality and trend terms, from probability distributions in the latent space to enable complex pattern separation and provide interpretable forecasts. Extensive experiments on several datasets demonstrate the effectiveness and robustness of the proposed model, indicating that it compares favorably with the state of the art.
MetaComp: Learning to Adapt for Online Depth Completion
Jul 21, 2022
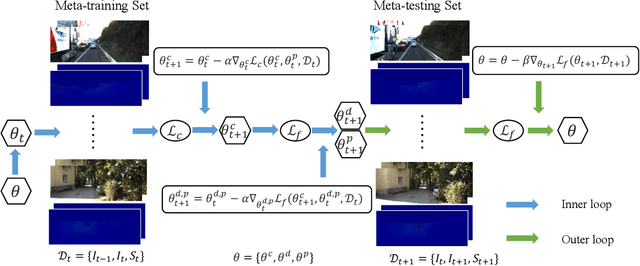


Relying on deep supervised or self-supervised learning, previous methods for depth completion from paired single image and sparse depth data have achieved impressive performance in recent years. However, facing a new environment where the test data occurs online and differs from the training data in the RGB image content and depth sparsity, the trained model might suffer severe performance drop. To encourage the trained model to work well in such conditions, we expect it to be capable of adapting to the new environment continuously and effectively. To achieve this, we propose MetaComp. It utilizes the meta-learning technique to simulate adaptation policies during the training phase, and then adapts the model to new environments in a self-supervised manner in testing. Considering that the input is multi-modal data, it would be challenging to adapt a model to variations in two modalities simultaneously, due to significant differences in structure and form of the two modal data. Therefore, we further propose to disentangle the adaptation procedure in the basic meta-learning training into two steps, the first one focusing on the depth sparsity while the second attending to the image content. During testing, we take the same strategy to adapt the model online to new multi-modal data. Experimental results and comprehensive ablations show that our MetaComp is capable of adapting to the depth completion in a new environment effectively and robust to changes in different modalities.