 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Bitter Lesson of Diffusion Language Models for Agentic Workflows: A Comprehensive Reality Check
Jan 19, 2026The pursuit of real-time agentic interaction has driven interest in Diffusion-based Large Language Models (dLLMs) as alternatives to auto-regressive backbones, promising to break the sequential latency bottleneck. However, does such efficiency gains translate into effective agentic behavior? In this work, we present a comprehensive evaluation of dLLMs (e.g., LLaDA, Dream) across two distinct agentic paradigms: Embodied Agents (requiring long-horizon planning) and Tool-Calling Agents (requiring precise formatting). Contrary to the efficiency hype, our results on Agentboard and BFCL reveal a "bitter lesson": current dLLMs fail to serve as reliable agentic backbones, frequently leading to systematically failure. (1) In Embodied settings, dLLMs suffer repeated attempts, failing to branch under temporal feedback. (2) In Tool-Calling settings, dLLMs fail to maintain symbolic precision (e.g. strict JSON schemas) under diffusion noise. To assess the potential of dLLMs in agentic workflows, we introduce DiffuAgent, a multi-agent evaluation framework that integrates dLLMs as plug-and-play cognitive cores. Our analysis shows that dLLMs are effective in non-causal roles (e.g., memory summarization and tool selection) but require the incorporation of causal, precise, and logically grounded reasoning mechanisms into the denoising process to be viable for agentic tasks.
Probabilistic Temporal Masked Attention for Cross-view Online Action Detection
Aug 23, 2025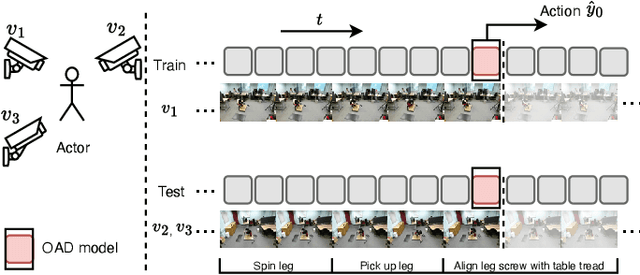
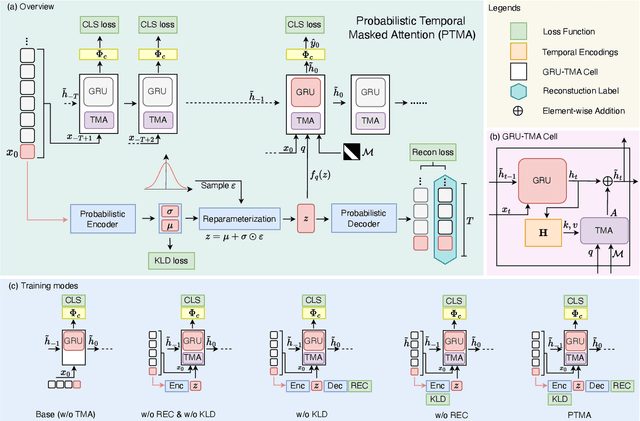
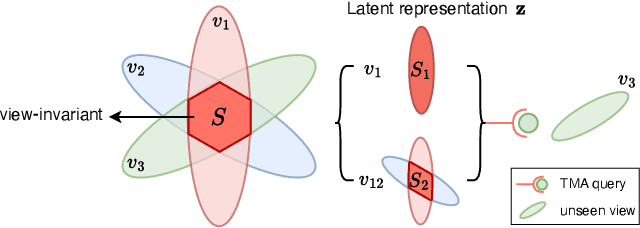
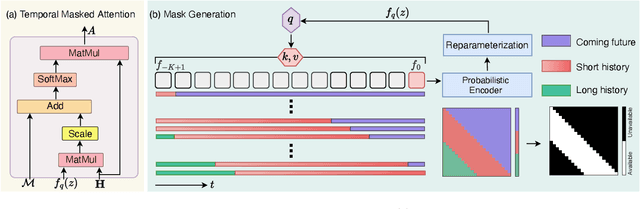
As a critical task in video sequence classification within computer vision, Online Action Detection (OAD) has garnered significant attention. The sensitivity of mainstream OAD models to varying video viewpoints often hampers their generalization when confronted with unseen sources. To address this limitation, we propose a novel Probabilistic Temporal Masked Attention (PTMA) model, which leverages probabilistic modeling to derive latent compressed representations of video frames in a cross-view setting. The PTMA model incorporates a GRU-based temporal masked attention (TMA) cell, which leverages these representations to effectively query the input video sequence, thereby enhancing information interaction and facilitating autoregressive frame-level video analysis. Additionally, multi-view information can be integrated into the probabilistic modeling to facilitate the extraction of view-invariant features. Experiments conducted under three evaluation protocols: cross-subject (cs), cross-view (cv), and cross-subject-view (csv) show that PTMA achieves state-of-the-art performance on the DAHLIA, IKEA ASM, and Breakfast datasets.
Runaway is Ashamed, But Helpful: On the Early-Exit Behavior of Large Language Model-based Agents in Embodied Environments
May 23, 2025Agents powered by large language models (LLMs) have demonstrated strong planning and decision-making capabilities in complex embodied environments. However, such agents often suffer from inefficiencies in multi-turn interactions, frequently trapped in repetitive loops or issuing ineffective commands, leading to redundant computational overhead. Instead of relying solely on learning from trajectories, we take a first step toward exploring the early-exit behavior for LLM-based agents. We propose two complementary approaches: 1. an $\textbf{intrinsic}$ method that injects exit instructions during generation, and 2. an $\textbf{extrinsic}$ method that verifies task completion to determine when to halt an agent's trial. To evaluate early-exit mechanisms, we introduce two metrics: one measures the reduction of $\textbf{redundant steps}$ as a positive effect, and the other evaluates $\textbf{progress degradation}$ as a negative effect. Experiments with 4 different LLMs across 5 embodied environments show significant efficiency improvements, with only minor drops in agent performance. We also validate a practical strategy where a stronger agent assists after an early-exit agent, achieving better performance with the same total steps. We will release our code to support further research.
MQM-APE: Toward High-Quality Error Annotation Predictors with Automatic Post-Editing in LLM Translation Evaluators
Sep 22, 2024Large Language Models (LLMs) have shown significant potential as judges for Machine Translation (MT) quality assessment, providing both scores and fine-grained feedback. Although approaches such as GEMBA-MQM has shown SOTA performance on reference-free evaluation, the predicted errors do not align well with those annotated by human, limiting their interpretability as feedback signals. To enhance the quality of error annotations predicted by LLM evaluators, we introduce a universal and training-free framework, $\textbf{MQM-APE}$, based on the idea of filtering out non-impactful errors by Automatically Post-Editing (APE) the original translation based on each error, leaving only those errors that contribute to quality improvement. Specifically, we prompt the LLM to act as 1) $\textit{evaluator}$ to provide error annotations, 2) $\textit{post-editor}$ to determine whether errors impact quality improvement and 3) $\textit{pairwise quality verifier}$ as the error filter. Experiments show that our approach consistently improves both the reliability and quality of error spans against GEMBA-MQM, across eight LLMs in both high- and low-resource languages. Orthogonal to trained approaches, MQM-APE complements translation-specific evaluators such as Tower, highlighting its broad applicability. Further analysis confirm the effectiveness of each module and offer valuable insights into evaluator design and LLMs selection. The code will be released to facilitate the community.
A lightweight network for photovoltaic cell defect detection in electroluminescence images based on neural architecture search and knowledge distillation
Feb 15, 2023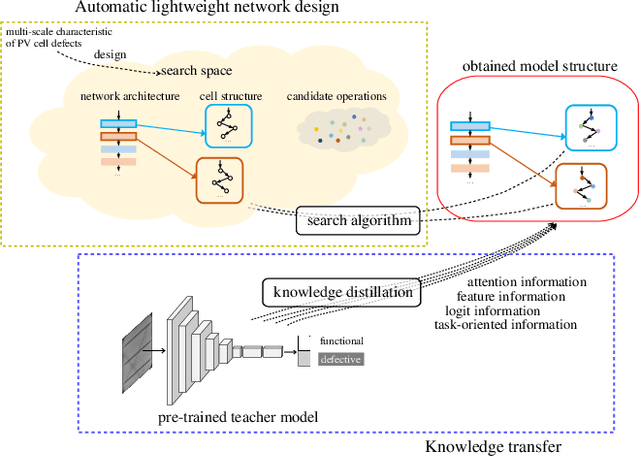
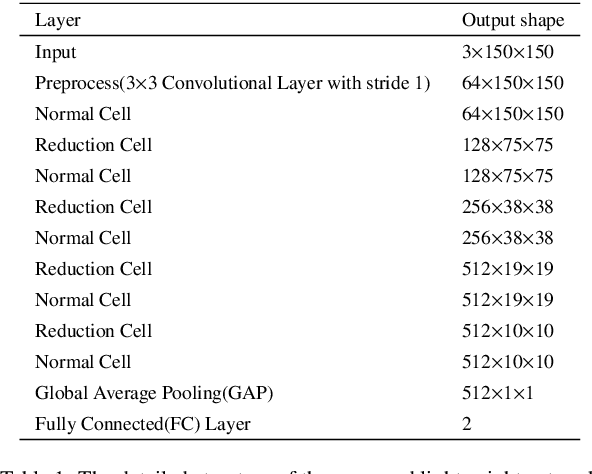
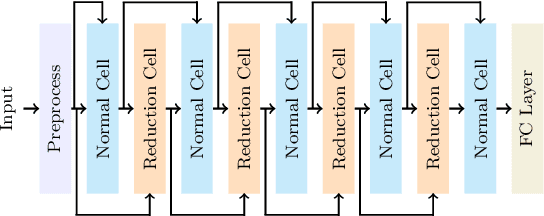
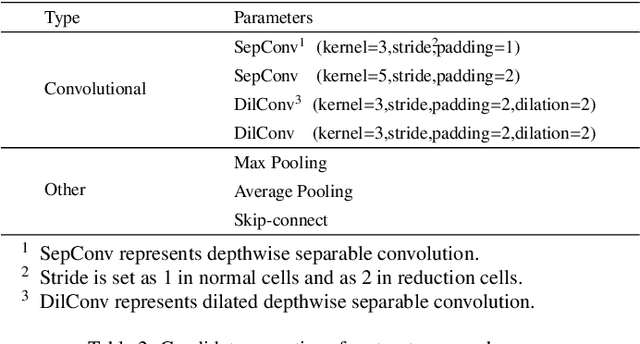
Nowadays, the rapid development of photovoltaic(PV) power stations requires increasingly reliable maintenance and fault diagnosis of PV modules in the field. Due to the effectiveness, convolutional neural network (CNN) has been widely used in the existing automatic defect detection of PV cells. However, the parameters of these CNN-based models are very large, which require stringent hardware resources and it is difficult to be applied in actual industrial projects. To solve these problems, we propose a novel lightweight high-performance model for automatic defect detection of PV cells in electroluminescence(EL) images based on neural architecture search and knowledge distillation. To auto-design an effective lightweight model, we introduce neural architecture search to the field of PV cell defect classification for the first time. Since the defect can be any size, we design a proper search structure of network to better exploit the multi-scale characteristic. To improve the overall performance of the searched lightweight model, we further transfer the knowledge learned by the existing pre-trained large-scale model based on knowledge distillation. Different kinds of knowledge are exploited and transferred, including attention information, feature information, logit information and task-oriented information. Experiments have demonstrated that the proposed model achieves the state-of-the-art performance on the public PV cell dataset of EL images under online data augmentation with accuracy of 91.74% and the parameters of 1.85M. The proposed lightweight high-performance model can be easily deployed to the end devices of the actual industrial projects and retain the accuracy.
Toward Human-Like Evaluation for Natural Language Generation with Error Analysis
Dec 20, 2022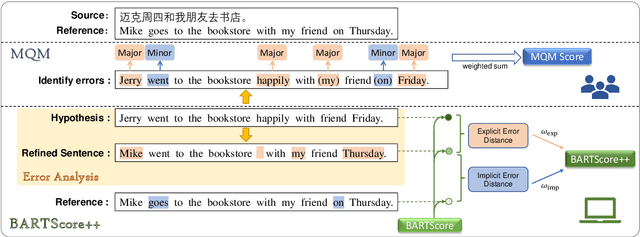


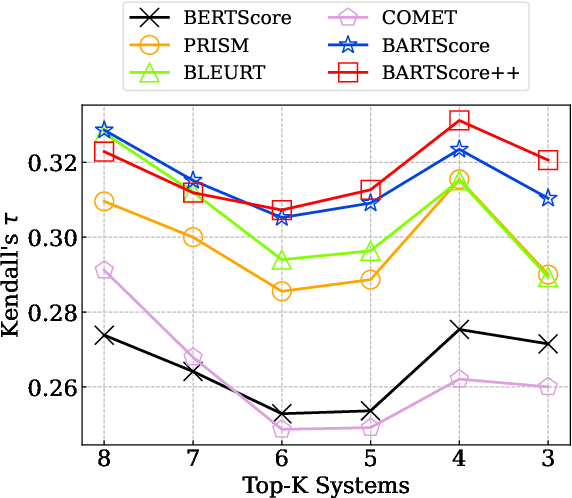
The state-of-the-art language model-based automatic metrics, e.g. BARTScore, benefiting from large-scale contextualized pre-training, have been successfully used in a wide range of natural language generation (NLG) tasks, including machine translation, text summarization, and data-to-text. Recent studies show that considering both major errors (e.g. mistranslated tokens) and minor errors (e.g. imperfections in fluency) can produce high-quality human judgments. This inspires us to approach the final goal of the evaluation metrics (human-like evaluations) by automatic error analysis. To this end, we augment BARTScore by incorporating the human-like error analysis strategies, namely BARTScore++, where the final score consists of both the evaluations of major errors and minor errors. Experimental results show that BARTScore++ can consistently improve the performance of vanilla BARTScore and outperform existing top-scoring metrics in 20 out of 25 test settings. We hope our technique can also be extended to other pre-trained model-based metrics. We will release our code and scripts to facilitate the community.
Probabilistic Decomposition Transformer for Time Series Forecasting
Oct 31, 2022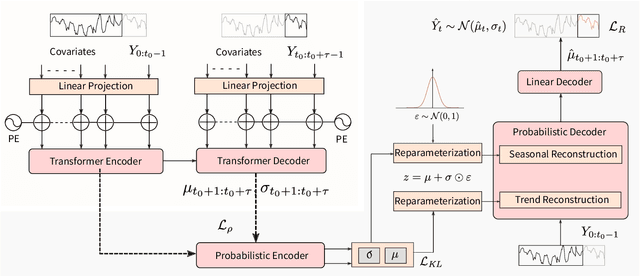
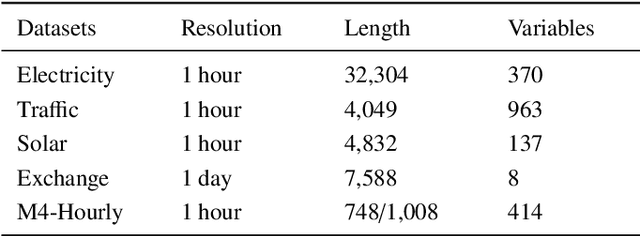
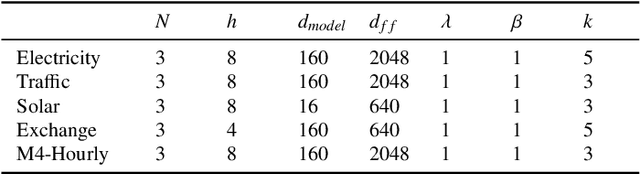
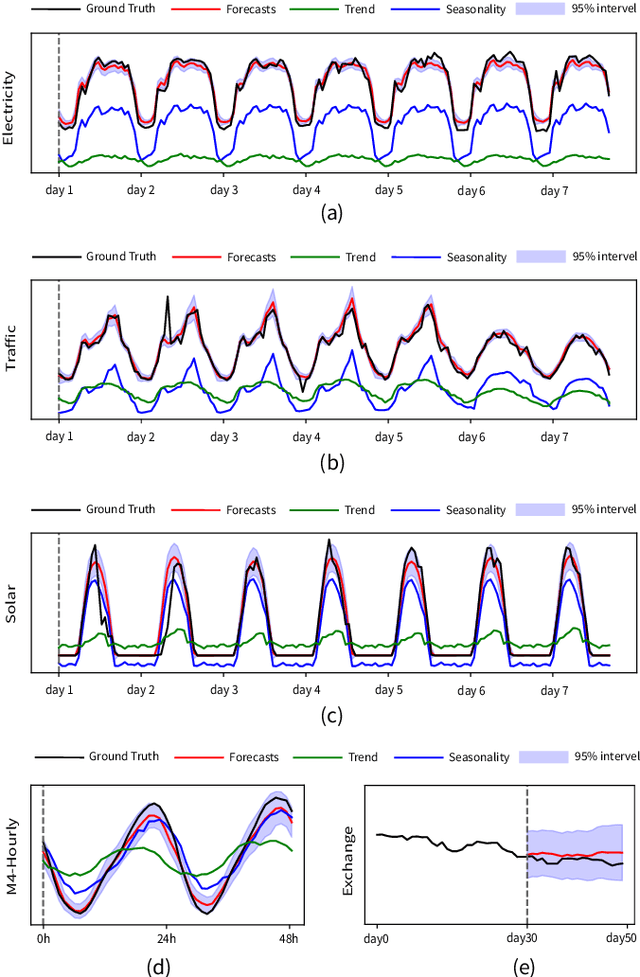
Time series forecasting is crucial for many fields, such as disaster warning, weather prediction, and energy consumption. The Transformer-based models are considered to have revolutionized the field of sequence modeling. However, the complex temporal patterns of the time series hinder the model from mining reliable temporal dependencies. Furthermore, the autoregressive form of the Transformer introduces cumulative errors in the inference step. In this paper, we propose the probabilistic decomposition Transformer model that combines the Transformer with a conditional generative model, which provides hierarchical and interpretable probabilistic forecasts for intricate time series. The Transformer is employed to learn temporal patterns and implement primary probabilistic forecasts, while the conditional generative model is used to achieve non-autoregressive hierarchical probabilistic forecasts by introducing latent space feature representations. In addition, the conditional generative model reconstructs typical features of the series, such as seasonality and trend terms, from probability distributions in the latent space to enable complex pattern separation and provide interpretable forecasts. Extensive experiments on several datasets demonstrate the effectiveness and robustness of the proposed model, indicating that it compares favorably with the state of the art.