 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Human-Like Evaluation for Natural Language Generation with Error Analysis
Paper and Code
Dec 20, 2022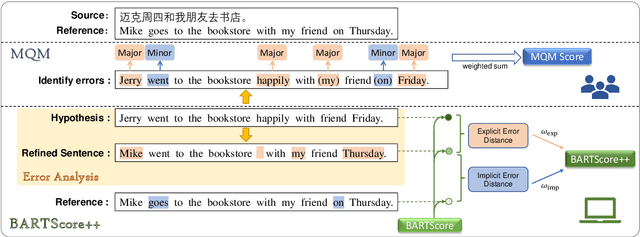


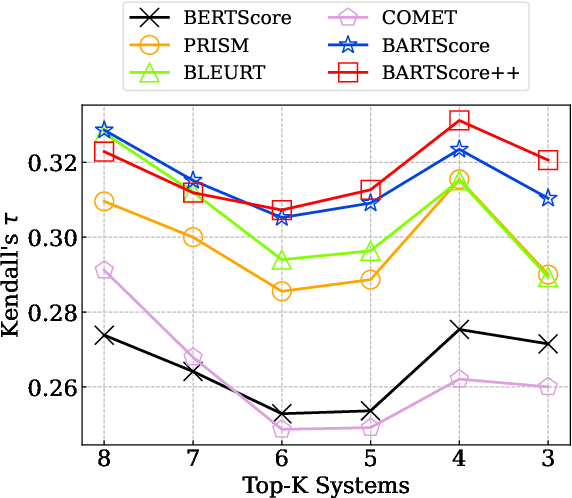
The state-of-the-art language model-based automatic metrics, e.g. BARTScore, benefiting from large-scale contextualized pre-training, have been successfully used in a wide range of natural language generation (NLG) tasks, including machine translation, text summarization, and data-to-text. Recent studies show that considering both major errors (e.g. mistranslated tokens) and minor errors (e.g. imperfections in fluency) can produce high-quality human judgments. This inspires us to approach the final goal of the evaluation metrics (human-like evaluations) by automatic error analysis. To this end, we augment BARTScore by incorporating the human-like error analysis strategies, namely BARTScore++, where the final score consists of both the evaluations of major errors and minor errors. Experimental results show that BARTScore++ can consistently improve the performance of vanilla BARTScore and outperform existing top-scoring metrics in 20 out of 25 test settings. We hope our technique can also be extended to other pre-trained model-based metrics. We will release our code and scripts to facilitate the community.