 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError Analysis Prompting Enables Human-Like Translation Evaluation in Large Language Models: A Case Study on ChatGPT
Paper and Code
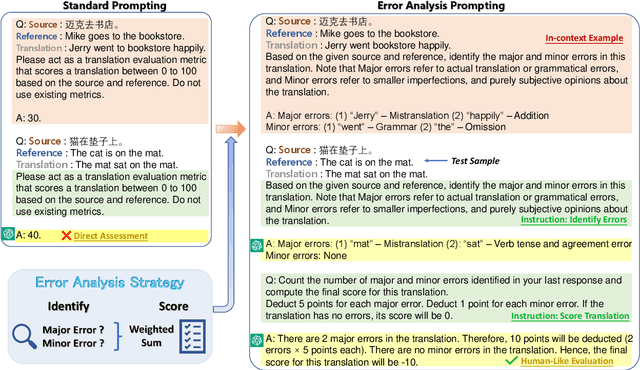
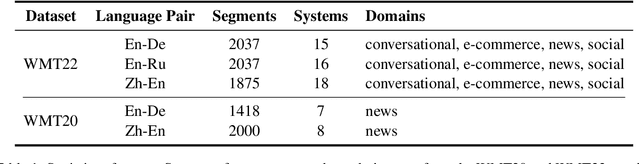
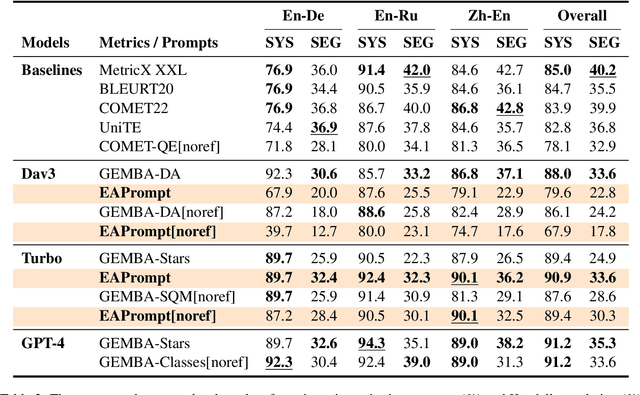
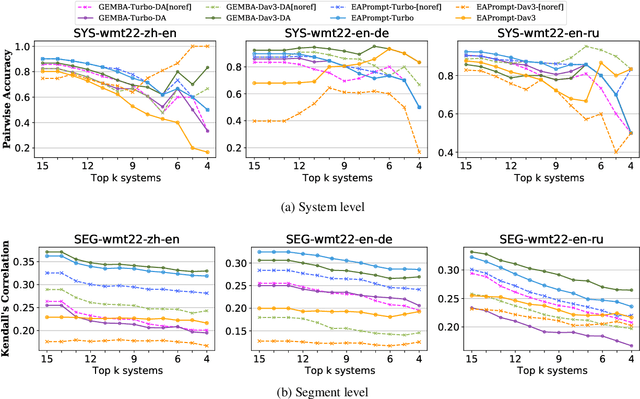
Generative large language models (LLMs), e.g., ChatGPT, have demonstrated remarkable proficiency across several NLP tasks such as machine translation, question answering, text summarization, and natural language understanding. Recent research has shown that utilizing ChatGPT for assessing the quality of machine translation (MT) achieves state-of-the-art performance at the system level but performs poorly at the segment level. To further improve the performance of LLMs on MT quality assessment, we conducted an investigation into several prompting methods. Our results indicate that by combining Chain-of-Thoughts and Error Analysis, a new prompting method called \textbf{\texttt{Error Analysis Prompting}}, LLMs like ChatGPT can \textit{generate human-like MT evaluations at both the system and segment level}. Additionally, we discovered some limitations of ChatGPT as an MT evaluator, such as unstable scoring and biases when provided with multiple translations in a single query. Our findings aim to provide a preliminary experience for appropriately evaluating translation quality on ChatGPT while offering a variety of tricks in designing prompts for in-context learning. We anticipate that this report will shed new light on advancing the field of translation evaluation with LLMs by enhancing both the accuracy and reliability of metrics. The project can be found in \url{https://github.com/Coldmist-Lu/ErrorAnalysis_Prompt}.