 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Denoising Knowledge Graphs For Retrieval Augmented Generation
Oct 16, 2025Retrieval-Augmented Generation (RAG) systems enable large language models (LLMs) instant access to relevant information for the generative process, demonstrating their superior performance in addressing common LLM challenges such as hallucination, factual inaccuracy, and the knowledge cutoff. Graph-based RAG further extends this paradigm by incorporating knowledge graphs (KGs) to leverage rich, structured connections for more precise and inferential responses. A critical challenge, however, is that most Graph-based RAG systems rely on LLMs for automated KG construction, often yielding noisy KGs with redundant entities and unreliable relationships. This noise degrades retrieval and generation performance while also increasing computational cost. Crucially, current research does not comprehensively address the denoising problem for LLM-generated KGs. In this paper, we introduce DEnoised knowledge Graphs for Retrieval Augmented Generation (DEG-RAG), a framework that addresses these challenges through: (1) entity resolution, which eliminates redundant entities, and (2) triple reflection, which removes erroneous relations. Together, these techniques yield more compact, higher-quality KGs that significantly outperform their unprocessed counterparts. Beyond the methods, we conduct a systematic evaluation of entity resolution for LLM-generated KGs, examining different blocking strategies, embedding choices, similarity metrics, and entity merging techniques. To the best of our knowledge, this is the first comprehensive exploration of entity resolution in LLM-generated KGs. Our experiments demonstrate that this straightforward approach not only drastically reduces graph size but also consistently improves question answering performance across diverse popular Graph-based RAG variants.
Margin-aware Fuzzy Rough Feature Selection: Bridging Uncertainty Characterization and Pattern Classification
May 21, 2025Fuzzy rough feature selection (FRFS) is an effective means of addressing the curse of dimensionality in high-dimensional data. By removing redundant and irrelevant features, FRFS helps mitigate classifier overfitting, enhance generalization performance, and lessen computational overhead. However, most existing FRFS algorithms primarily focus on reducing uncertainty in pattern classification, neglecting that lower uncertainty does not necessarily result in improved classification performance, despite it commonly being regarded as a key indicator of feature selection effectiveness in the FRFS literature. To bridge uncertainty characterization and pattern classification, we propose a Margin-aware Fuzzy Rough Feature Selection (MAFRFS) framework that considers both the compactness and separation of label classes. MAFRFS effectively reduces uncertainty in pattern classification tasks, while guiding the feature selection towards more separable and discriminative label class structures. Extensive experiments on 15 public datasets demonstrate that MAFRFS is highly scalable and more effective than FRFS. The algorithms developed using MAFRFS outperform six state-of-the-art feature selection algorithms.
Rethinking Label-specific Features for Label Distribution Learning
Apr 27, 2025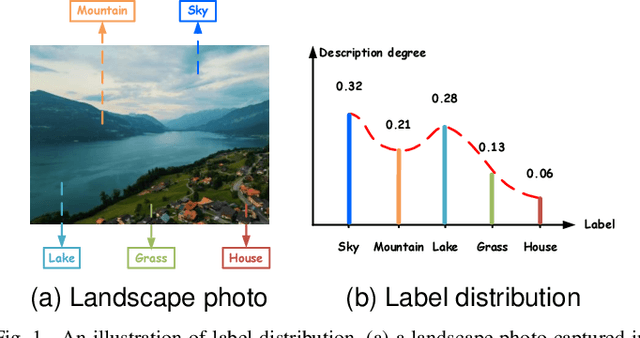
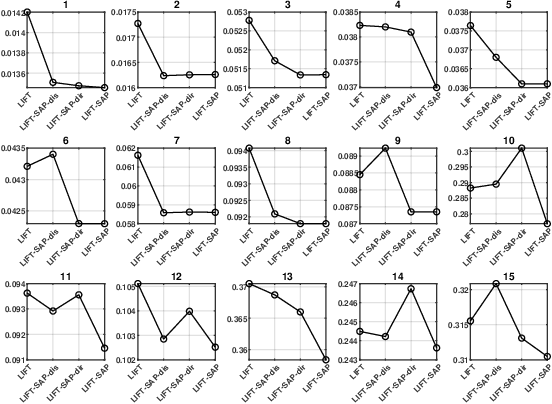
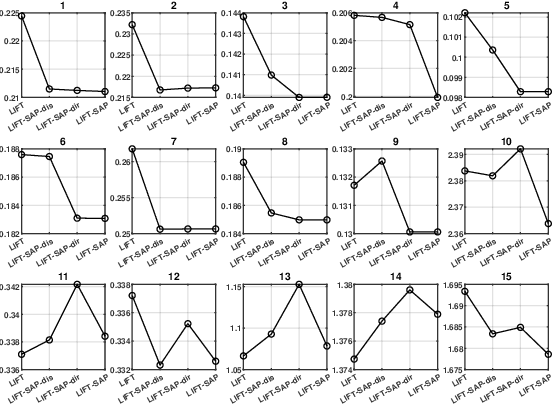
Label distribution learning (LDL) is an emerging learning paradigm designed to capture the relative importance of labels for each instance. Label-specific features (LSFs), constructed by LIFT, have proven effective for learning tasks with label ambiguity by leveraging clustering-based prototypes for each label to re-characterize instances. However, directly introducing LIFT into LDL tasks can be suboptimal, as the prototypes it collects primarily reflect intra-cluster relationships while neglecting interactions among distinct clusters. Additionally, constructing LSFs using multi-perspective information, rather than relying solely on Euclidean distance, provides a more robust and comprehensive representation of instances, mitigating noise and bias that may arise from a single distance perspective. To address these limitations, we introduce Structural Anchor Points (SAPs) to capture inter-cluster interactions. This leads to a novel LSFs construction strategy, LIFT-SAP, which enhances LIFT by integrating both distance and direction information of each instance relative to SAPs. Furthermore, we propose a novel LDL algorithm, Label Distribution Learning via Label-specifIc FeaTure with SAPs (LDL-LIFT-SAP), which unifies multiple label description degrees predicted from different LSF spaces into a cohesive label distribution. Extensive experiments on 15 real-world datasets demonstrate the effectiveness of LIFT-SAP over LIFT, as well as the superiority of LDL-LIFT-SAP compared to seven other well-established algorithms.
Original or Translated? On the Use of Parallel Data for Translation Quality Estimation
Dec 20, 2022



Machine Translation Quality Estimation (QE) is the task of evaluating translation output in the absence of human-written references. Due to the scarcity of human-labeled QE data, previous works attempted to utilize the abundant unlabeled parallel corpora to produce additional training data with pseudo labels. In this paper, we demonstrate a significant gap between parallel data and real QE data: for QE data, it is strictly guaranteed that the source side is original texts and the target side is translated (namely translationese). However, for parallel data, it is indiscriminate and the translationese may occur on either source or target side. We compare the impact of parallel data with different translation directions in QE data augmentation, and find that using the source-original part of parallel corpus consistently outperforms its target-original counterpart. Moreover, since the WMT corpus lacks direction information for each parallel sentence, we train a classifier to distinguish source- and target-original bitext, and carry out an analysis of their difference in both style and domain. Together, these findings suggest using source-original parallel data for QE data augmentation, which brings a relative improvement of up to 4.0% and 6.4% compared to undifferentiated data on sentence- and word-level QE tasks respectively.
Data-Free Adversarial Perturbations for Practical Black-Box Attack
Mar 03, 2020
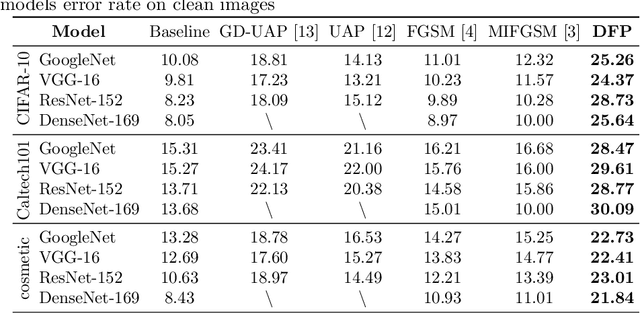

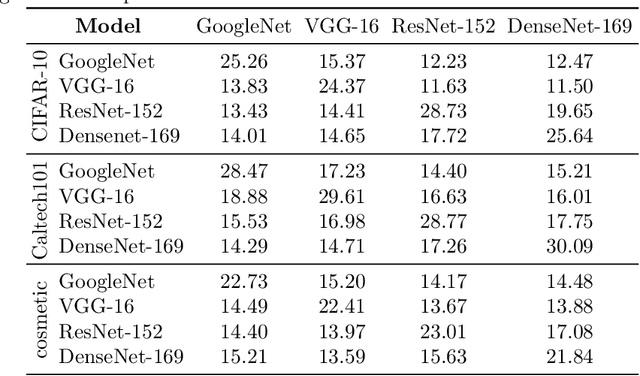
Neural networks are vulnerable to adversarial examples, which are malicious inputs crafted to fool pre-trained models. Adversarial examples often exhibit black-box attacking transferability, which allows that adversarial examples crafted for one model can fool another model. However, existing black-box attack methods require samples from the training data distribution to improve the transferability of adversarial examples across different models. Because of the data dependence, the fooling ability of adversarial perturbations is only applicable when training data are accessible. In this paper, we present a data-free method for crafting adversarial perturbations that can fool a target model without any knowledge about the training data distribution. In the practical setting of a black-box attack scenario where attackers do not have access to target models and training data, our method achieves high fooling rates on target models and outperforms other universal adversarial perturbation methods. Our method empirically shows that current deep learning models are still at risk even when the attackers do not have access to training data.
Adaptive Re-ranking of Deep Feature for Person Re-identification
Nov 21, 2018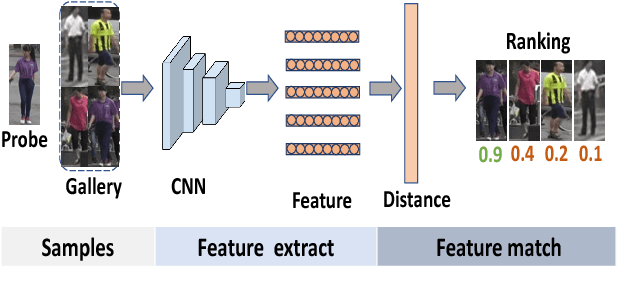
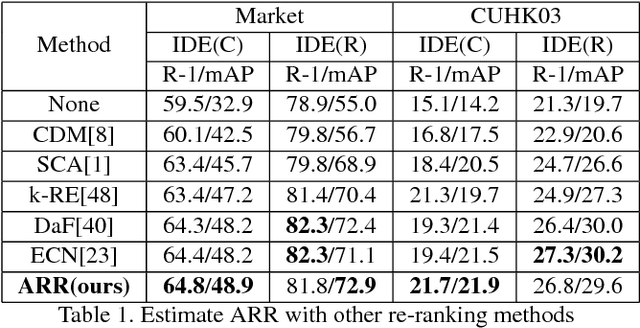
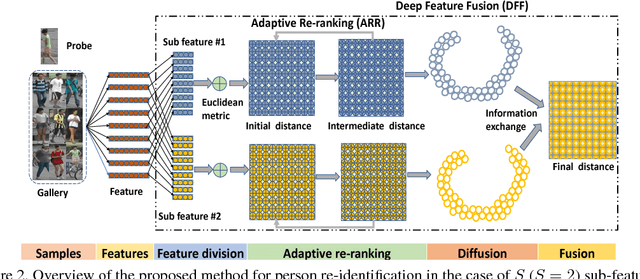
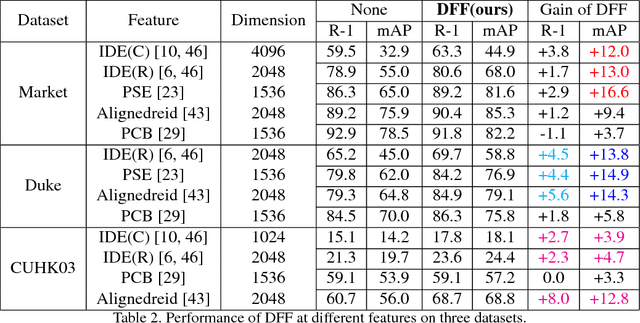
Typical person re-identification (re-ID) methods train a deep CNN to extract deep features and combine them with a distance metric for the final evaluation. In this work, we focus on exploiting the full information encoded in the deep feature to boost the re-ID performance. First, we propose a Deep Feature Fusion (DFF) method to exploit the diverse information embedded in a deep feature. DFF treats each sub-feature as an information carrier and employs a diffusion process to exchange their information. Second, we propose an Adaptive Re-Ranking (ARR) method to exploit the contextual information encoded in the features of neighbors. ARR utilizes the contextual information to re-rank the retrieval results in an iterative manner. Particularly, it adds more contextual information after each iteration automatically to consider more matches. Third, we propose a strategy that combines DFF and ARR to enhance the performance. Extensive comparative evaluations demonstrate the superiority of the proposed methods on three large benchmarks.