 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversifying the Mixture-of-Experts Representation for Language Models with Orthogonal Optimizer
Oct 15, 2023The Mixture of Experts (MoE) has emerged as a highly successful technique in deep learning, based on the principle of divide-and-conquer to maximize model capacity without significant additional computational cost. Even in the era of large-scale language models (LLMs), MoE continues to play a crucial role, as some researchers have indicated that GPT-4 adopts the MoE structure to ensure diverse inference results. However, MoE is susceptible to performance degeneracy, particularly evident in the issues of imbalance and homogeneous representation among experts. While previous studies have extensively addressed the problem of imbalance, the challenge of homogeneous representation remains unresolved. In this study, we shed light on the homogeneous representation problem, wherein experts in the MoE fail to specialize and lack diversity, leading to frustratingly high similarities in their representations (up to 99% in a well-performed MoE model). This problem restricts the expressive power of the MoE and, we argue, contradicts its original intention. To tackle this issue, we propose a straightforward yet highly effective solution: OMoE, an orthogonal expert optimizer. Additionally, we introduce an alternating training strategy that encourages each expert to update in a direction orthogonal to the subspace spanned by other experts. Our algorithm facilitates MoE training in two key ways: firstly, it explicitly enhances representation diversity, and secondly, it implicitly fosters interaction between experts during orthogonal weights computation. Through extensive experiments, we demonstrate that our proposed optimization algorithm significantly improves the performance of fine-tuning the MoE model on the GLUE benchmark, SuperGLUE benchmark, question-answering task, and name entity recognition tasks.
Cherry Hypothesis: Identifying the Cherry on the Cake for Dynamic Networks
Nov 10, 2022



Dynamic networks have been extensively explored as they can considerably improve the model's representation power with acceptable computational cost. The common practice in implementing dynamic networks is to convert given static layers into fully dynamic ones where all parameters are dynamic and vary with the input. Recent studies empirically show the trend that the more dynamic layers contribute to ever-increasing performance. However, such a fully dynamic setting 1) may cause redundant parameters and high deployment costs, limiting the applicability of dynamic networks to a broader range of tasks and models, and more importantly, 2) contradicts the previous discovery in the human brain that \textit{when human brains process an attention-demanding task, only partial neurons in the task-specific areas are activated by the input, while the rest neurons leave in a baseline state.} Critically, there is no effort to understand and resolve the above contradictory finding, leaving the primal question -- to make the computational parameters fully dynamic or not? -- unanswered. The main contributions of our work are challenging the basic commonsense in dynamic networks, and, proposing and validating the \textsc{cherry hypothesis} -- \textit{A fully dynamic network contains a subset of dynamic parameters that when transforming other dynamic parameters into static ones, can maintain or even exceed the performance of the original network.} Technically, we propose a brain-inspired partially dynamic network, namely PAD-Net, to transform the redundant dynamic parameters into static ones. Also, we further design Iterative Mode Partition to partition the dynamic- and static-subnet, which alleviates the redundancy in traditional fully dynamic networks. Our hypothesis and method are comprehensively supported by large-scale experiments with typical advanced dynamic methods.
Vega-MT: The JD Explore Academy Translation System for WMT22
Sep 21, 2022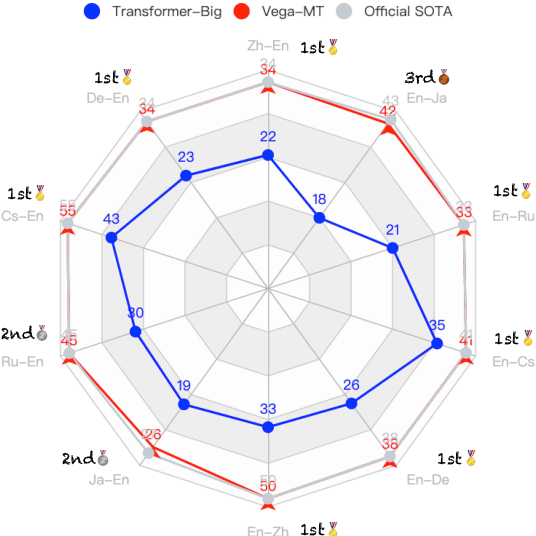
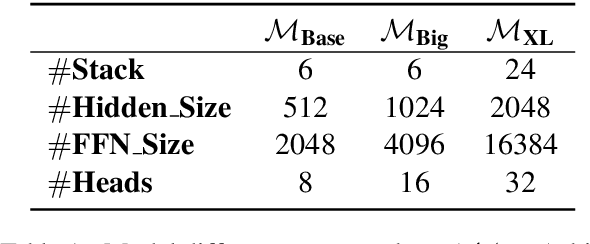
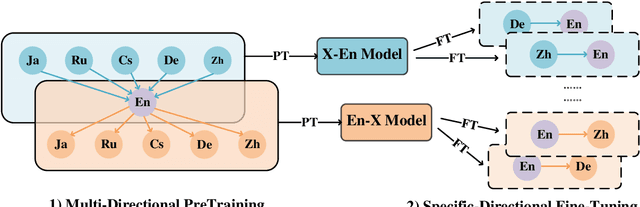

We describe the JD Explore Academy's submission of the WMT 2022 shared general translation task. We participated in all high-resource tracks and one medium-resource track, including Chinese-English, German-English, Czech-English, Russian-English, and Japanese-English. We push the limit of our previous work -- bidirectional training for translation by scaling up two main factors, i.e. language pairs and model sizes, namely the \textbf{Vega-MT} system. As for language pairs, we scale the "bidirectional" up to the "multidirectional" settings, covering all participating languages, to exploit the common knowledge across languages, and transfer them to the downstream bilingual tasks. As for model sizes, we scale the Transformer-Big up to the extremely large model that owns nearly 4.7 Billion parameters, to fully enhance the model capacity for our Vega-MT. Also, we adopt the data augmentation strategies, e.g. cycle translation for monolingual data, and bidirectional self-training for bilingual and monolingual data, to comprehensively exploit the bilingual and monolingual data. To adapt our Vega-MT to the general domain test set, generalization tuning is designed. Based on the official automatic scores of constrained systems, in terms of the sacreBLEU shown in Figure-1, we got the 1st place on {Zh-En (33.5), En-Zh (49.7), De-En (33.7), En-De (37.8), Cs-En (54.9), En-Cs (41.4) and En-Ru (32.7)}, 2nd place on {Ru-En (45.1) and Ja-En (25.6)}, and 3rd place on {En-Ja(41.5)}, respectively; W.R.T the COMET, we got the 1st place on {Zh-En (45.1), En-Zh (61.7), De-En (58.0), En-De (63.2), Cs-En (74.7), Ru-En (64.9), En-Ru (69.6) and En-Ja (65.1)}, 2nd place on {En-Cs (95.3) and Ja-En (40.6)}, respectively. Models will be released to facilitate the MT community through GitHub and OmniForce Platform.